Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
《Spark最佳实战 陈欢》写的这本书,关于此知识点,非常好,在94页。
hive里的扩展接口,主要包括CLI(控制命令行接口)、Beeline和JDBC等方式访问Hive。
CLI和Beeline都是交互式用户接口,并且功能相似,但是语法和实现不同。
JDBC是一种类似于编程访问关系型数据库的编程接口。
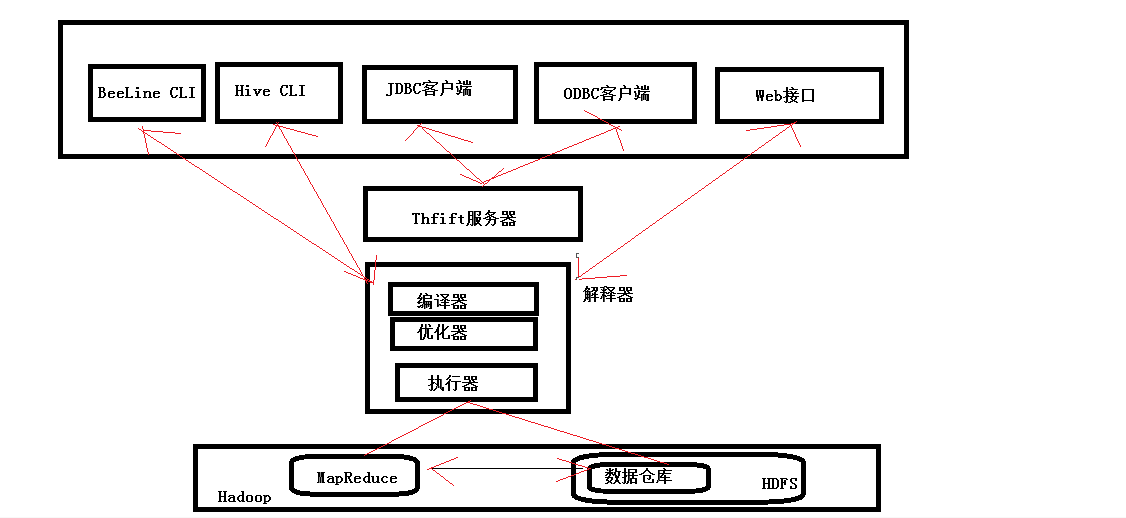
1、CLI
在UNIX shell环境下输入hive命令可以启用Hive CLI。在CLI下,所有的Hive语句都以分号结束。
在CLI下可以对一些属性做出设置,像是设置底层MapReduce任务中Reducer的实例数。这些信息都详细地记录在在线Hive语言手册中。
下面是一些专门针对Hive,并且对使用Hive CLI非常有帮助的属性:
hive.cli.print.header:当设置为true时,查询返回结果的同时会打印列名。默认情况下设置为false。因此不会打印。
想要开启列名打印的功能需要输入以下指令。
hive > set hive.cli.print.header=true;
hive.cli.print.current.db:当设置为true时,将打印当前数据库的名字。默认情况下设置为false。
可以通过输入以下指令修改属性:
hive > set hive.cli.print.current.db=true;
hive (default) >
2、Beeline
Beeline可以作为标准命令行接口的替代者。它使用JDBC连接Hive,而且基于开源的SQLLine项目。
Beeline的工作方式和Hive CLI很像,但是使用Beeline需要与Hive建立显示的连接:
$ beeline
Beeline version 0.11.0 by Apache Hive
beeline > !connect jdbc:hive:// nouser nopassword
本地模式中使用的JDBC的URL是jdbc:hive//。如果是集群中的配置,那么JDBC的URL通常是这样的形式:dbc:hive//<hostname>:<port>。
<hostname>是Hive服务器的主机名,<port>是预先配置的端口号(默认为10000)。
这样的情况下,我们可以使用Beeline执行任何Hive语句,与使用CLI一样。
3、JDBC
Java客户端可以使用预先提供的JDBC驱动来连接Hive。连接步骤和其他兼容JDBC的数据库一样。首先载入驱动,然后建立连接。
JDBC驱动的类名是org.apache.hadoop.hive.jdbc.HiveDriver。
本地模式中使用的JDBC的URL是jdbc:hive://。
如果是集群中的配置,那么JDBC的URL通常是这样的形式:jdbc:hive//<hostname>:<port>。
<hostname>是Hive服务器的主机名,<port>是预先配置的端口号(默认为10000)。
给一个例子,展示使用JDBC连接本地模式的Hive,并提交查询请求:
import java.sql.Connection;
import java.sql.Driver;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.Statement;
import org.apache.log4j.Level;
import org.apache.log4j.LogManager;
public class HiveJdbcClient{
private static String driverName="org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args)throws Exception{
LogManager.getRootLogger().setLevel(Level.ERROR);
Class.forName(driverName);
Connection con=DriverManager.getConnection(
"jdbc:hive://","","");
Statement stmt=con.createStatement();
stmt.executeQuery(:drop table videos_ex);
ResultSet res=stmt.executeQuery("CREATE EXTERNAL TABLE videos_ex" +
"(producer string,title string,category string,year int)" +
"ROW FROMAT DELTMTIED FIELDS TERMINATED BY \",\" LOCATION " +
"/home/madhu/external/videos_ex/data");
//show tables
String sql = "show tables";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
if(res.next()){
System.out.println(res.getString(1));
}
//describe table
sql="describe videos_ex";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.println(res.getString(1) + "\t" +res.getString(2));
}
//select query
sql="select * from videos_ex";
System.out.println("Running:" + sql);
res=stmt.executeQuery(sql);
ResultSetMetaData rsmd=res.getMetaData();
int ncols=rsmd.getColumnCount();
for(int i=0;i<ncols;i++){
System.out.print(rsmd.getColumnLabel(i+1));
System.out.print("\t");
}
System.out.println();
while(res.next()){
for(int i=0;i<ncols;i++){
System.out.print(res.getString(i+1));
System.out.print("\t");
}
System.out.println();
}
//regular hive query
sql ="select count(1) from videos_ex";
System.out.println.("Running:" +sql);
res=stmt.executeQuery(sql);
if(res.next()){
System.out.println("Number of rows:" + res.getString(1));
}
}
}
再次谈谈 Hive JDBC编程接口与程序设计
Hive支持标准的数据库查询接口JDBC,在JDBC中需要指定驱动字符串以及连接字符串,Hive使用的驱动器字符串为“org.apache.hadoop.hive.jdbc.HiveDriver”。
在Hive的软件包中已经加入了对应的JDBC的驱动程序,连接字符串标志了将要访问的Hive服务器。例如 jdbc://master:10000/default,在配置连接字符串后可以直接使用传统的JDBC编程技术去访问Hive所提供的功能。
当然这里,可以,手动。一般包括
commons-lang-*.*.jar
commons-logging-*.*.*.jar
commons-logging-api-*.*.*.jar
hadoop-core-*.*.*-Intel.jar
hive-exec-*.*.*-Intel.jar
hive-jdbc*.*.*Intel.jar
hive-metastore-*.*.*-Intel.jar
libfb***-*.*.*.jar
log4j-*.*.*.jar
slf4j-api-*.*.*.jar
slf4j-log4j*-*.*.*.jar
为了展示如何基于Hive JDBC进行具体的java编程,设有如下预存在文件中的样例数据:
1&data1_value
2&data2_value
3&data3_value
...
198&data198_value
199&data199_value
200&data200_value
所演示的示例程序将首先创建应Hive表,然后将存放在上述文件中的样例数据装入到这个Hive表中,并通过查询接口并显示出这些数据。
基于Hive JDBC的Java编程示例代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Driver;
import java.sql.SQLException;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.Statement;
import org.apache.log4j.Level;
import org.apache.log4j.LogManager;
//该类用于将Hive作为数据库,使用JDBC连接Hive,实现对Hive进行增、删、查等操作。
public class classHiveJdbc{
private static String driverName="org.apache.hadoop.hive.jdbc.HiveDriver";
/**
*实现连接Hive,并对Hive进行增、删、查等操作
*/
public static void main(String[] args)throws SQLException{
LogManager.getRootLogger().setLevel(Level.ERROR);
{
try{
Class.forName(driverName);
}catch (ClassNotFoundException e){
e.printStackTrace();
System.exit(1);
}
Connection con=DriverManager.getConnection(
"jdbc:hive://192.168.81.182:100000/hivebase","","");
Statement stmt=con.createStatement();
String tableName="HiveTables";
//删除和创建数据表
stmt.executeQuery("DROP TABLE" + tableName);
ResultSet res=stmt.executeQuery("CREATE TABLE " + tableName +
"(key int,value string)" +
"ROW FROMAT DELTMTIED FIELDS TERMINATED BY '&' +
stored as textfile);
//检查和显示数据表
String sql = "SHOW TABLES '" + tableName + "'";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
if(res.next()){
System.out.println(res.getString(1));
}
//显示数据表字段描述信息
sql="describe" + tableName";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.println(res.getString(1) + "\t" +res.getString(2));
}
//将文件数据装载到Hive表中
String filepath="/Test/data.txt";
sql="load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running:" + sql);
res=stmt.executeQuery(sql);
//字段查询
sql="select * from" + tableName;
System.out.println("Running:" + sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.print(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
System.out.print("\t");
}
//统计查询
sql ="select count(1) from tableName";
System.out.println.("Running:" +sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.println(res.getString(1));
}
}//main函数结束
}//HiveJdbc类结束
以下对程序中的重要部分进行说明。
private static String driverName="org.apache.hadoop.hive.jdbc.HiveDriver"; 为驱动字符串。
Class.forName(driverName); 为完成加载数据库驱动,它的主要功能为加载指定的class文件到java虚拟机的内存。
Connection con=DriverManager.getConnection(
"jdbc:hive://192.168.81.182:100000/hivebase","",""); 为连接字符串,这里需要制定服务器IP以及所用到的数据库。由于Hive不需要用户名和密码,所以第2个参数和第3个参数为空。
加载好驱动,配置好连接数据库字符串以后,便可以编写语句对Hive进行相应的操作。
如果操作的数据表已经存在,可以先将该表删掉,如stmt.executeQuery("DROP TABLE" + tableName);
删除表后,27行再创建表。
ResultSet res=stmt.executeQuery("CREATE TABLE " + tableName +
"(key int,value string)" +
"ROW FROMAT DELTMTIED FIELDS TERMINATED BY '&' +
stored as textfile);
在使用JDBC对Hive进行表的操作时所用到的语句与命令行的语句完全相同,只需要在程序中拼接出相应的语句即可。
创建表后,查看数据库是否有该表,将查询回来的结果输出到控制台。
String sql = "SHOW TABLES '" + tableName + "'";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
if(res.next()){
System.out.println(res.getString(1));
}
对表结构的查询、向表加载数据、查询数据以及统计等操作均可以通过与Hive命令相同的方式进行。
显示该表的字段结构信息,共有Key和value两个字段。
sql="describe" + tableName";
System.out.println("Running:" +sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.println(res.getString(1) + "\t" +res.getString(2));
}
将前述预存在一个文件中的数据装载到数据表中。
String filepath="/Test/data.txt";
sql="load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running:" + sql);
res=stmt.executeQuery(sql);
执行常规的字段数据查询,并打印输出查询结果
sql="select * from" + tableName;
System.out.println("Running:" + sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.print(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
System.out.print("\t");
}
执行一个统计查询,统计数据记录的行数并打印输出统计结果
sql ="select count(1) from tableName";
System.out.println.("Running:" +sql);
res=stmt.executeQuery(sql);
while(res.next()){
System.out.println(res.getString(1));
}
最后,执行,得到,以下为程序执行后控制台输出的日志:
1 data1_value
2 data2_value
3 data3_value
4 data4_value
5 data5_value
...
198 data198_value
199 data199_value
200 data200_value
Running:select count(1) from HiveTables
200
Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)的更多相关文章
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
- Hadoop Hive概念学习系列之hive里的分区(九)
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”. 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助. 分 ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
- Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的).想要开发UDF程序,需要继承org.apache ...
- Hadoop Hive概念学习系列之hive里的视图(十二)
不多说,直接上干货! 可以先,从MySQL里的视图概念理解入手 视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,与基本表不同,它是一个虚表.在数据库中,存放的只是视图的定义,而不存放视图包含的 ...
- Hadoop Hive概念学习系列之hive里的桶(十一)
不多说,直接上干货! Hive还可以把表或分区,组织成桶.将表或分区组织成桶有以下几个目的: 第一个目的是为看取样更高效,因为在处理大规模的数据集时,在开发.测试阶段将所有的数据全部处理一遍可能不太 ...
随机推荐
- pandas处理各类表格数据
经常遇到Python读取excel和csv还有其他各种文件的内容.json还有web端的读取还是比较简单,但是excel和csv的读写是很麻烦.这里记录了pandas库提供的方法来实现文本内容和Dat ...
- 2.Linux文件IO编程
2.1Linux文件IO概述 2.1.0POSIX规范 POSIX:(Portable Operating System Interface)可移植操作系统接口规范. 由IEEE制定,是为了提高UNI ...
- linux设置系统时间与各种阻塞
前阵子做了一个P2P的通信系统,发现开机的时候和中间运行的时候会莫名报错,这个问题找了好久,后来从日志中看出来,所有节点上阻塞的操作同时超时. 而在超时左右,有新节点自动加入系统. 在新节点加入系统的 ...
- FJoi2017 1月20日模拟赛 直线斯坦纳树(暴力+最小生成树+骗分+人工构造+随机乱搞)
[题目描述] 给定二维平面上n个整点,求该图的一个直线斯坦纳树,使得树的边长度总和尽量小. 直线斯坦纳树:使所有给定的点连通的树,所有边必须平行于坐标轴,允许在给定点外增加额外的中间节点. 如下图所示 ...
- Leetcode 131.分割回文串
分割回文串 给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串. 返回 s 所有可能的分割方案. 示例: 输入: "aab" 输出: [ ["aa" ...
- 洛谷 P1877 BZOJ 2748 cogs 791 [HAOI2012]音量调节
题目描述 一个吉他手准备参加一场演出.他不喜欢在演出时始终使用同一个音量,所以他决定每一首歌之前他都需要改变一次音量.在演出开始之前,他已经做好一个列表,里面写着每首歌开始之前他想要改变的音量是多少. ...
- 将Jquery EasyUI中DataGird的数据导入Excel中
1.第一步获取前台DataGrid中的数据 var rows = $('#tb).datagrid("getRows"); if (rows.length = ...
- ISO 7064:1983.MOD11-2校验码计算法 : (身份证校验码-18位)
/* 假设某一17位数字是 17位数字 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 加权因子 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2 计算17位 ...
- 洛谷—— P1725 琪露诺
https://www.luogu.org/problem/show?pid=1725 题目描述 在幻想乡,琪露诺是以笨蛋闻名的冰之妖精.某一天,琪露诺又在玩速冻青蛙,就是用冰把青蛙瞬间冻起来.但是这 ...
- T1683 车厢重组 codevs
http://codevs.cn/problem/1683/ 时间限制: 1 s 空间限制: 1000 KB 题目等级 : 白银 Silver 题目描述 Description 在一个旧式的火车 ...