(转)Hibernate的优化方案
http://blog.csdn.net/yerenyuan_pku/article/details/70768603
HQL优化
- 使用参数绑定
- 使用绑定参数的原因是让数据库一次解析SQL,对后续的重复请求可以使用生成好的执行计划,这样做节省CPU时间和内存。
- 避免SQL注入。
- 尽量少使用NOT
如果where子句中包含not关键字,那么执行时该字段的索引失效。 - 尽量使用where来替换having
having在检索出所有记录后才对结果集进行过滤,这个处理需要一定的开销,而where子句限制记录的数目,能减少这方面的开销。 - 减少对表的查询
在含有子查询的HQL中,尽量减少对表的查询,降低开销。 - 使用表的别名
当在HQL语句中连接多个表时,使用别名,提高程序阅读性,并把别名前缀与每个列连接上,这样一来,可以减少解析时间并减少列歧义引起的语法错误。 - 实体的更新与删除
在Hibernate3以后支持hql的update与delete操作。可参考度娘。
一级缓存优化
一级缓存也叫做session缓存,在一个hibernate session有效,这级缓存的可干预性不强,大多于hibernate自动管理,但它提供清除缓存的方法,这在大批量增加(更新)操作是有效果的,例如,同时增加十万条记录,按常规进行,很可能会出现异常,这时可能需要手动清除一级缓存,session.evict以及session.clear。
检索策略(抓取策略)
延迟加载
延迟加载是Hibernate为提高程序执行的效率而提供的一种机制,即只有真正使用该对象的数据时才会创建。load方法采用的策略是延迟加载;get方法采用的策略是立即加载。
检索策略分为两种:
- 类级别检索
- 关联级别检索
类级别检索
类级别检索是通过session直接检索某一类对应的数据,例如:
Customer c = session.load(Customer.class, 1);或
session.createQuery("from Order");类级别检索策略分为立即检索与延迟检索,默认是延迟检索,类级别的检索策略可以通过<class>元素的lazy属性来设置,默认值是true。所以我们可在hbm映射配置文件中设置如下:
<class name="Customer" table="t_customer" catalog="hibernateTest" lazy="true">
...
</class>除此之外,我们也可在PO类中使用@Proxy注解,例如:
@Proxy(lazy = true)
public class Customer {
...
}现在我着重来讲一下在PO类中@Proxy注解的使用。提示,以下所有案例代码的编写都是建立在Hibernate检索方式概述一文案例基础之上的。首先将@Proxy(lazy = true)这样的注解加在PO类——Customer类上,这样Customer类的代码就变成:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
@NamedQuery(name="myHql", query="from Customer")
// @SqlResultSetMapping注解才真正帮我们去规定执行sql语句如何将结果封装到Customer对象
@SqlResultSetMapping(name="customerSetMapping",entities={ @EntityResult(entityClass=Customer.class,fields={
@FieldResult(name="id",column="id"),@FieldResult(name="name",column="name") }) })
// fields指定类里面的每一个属性跟表中的列是如何对应的
@NamedNativeQuery(name="findCustomer",query="select * from t_customer",resultSetMapping="customerSetMapping")
// resultSetMapping需要指定一个名字,它用来指定结果如何封装的操作
@Proxy(lazy = true)
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
/*
* targetEntity="...":相当于<one-to-many class="...">
* mappedBy="...":相当于inverse=true,即放弃关联关系的维护,不然会生成一个中间表
*/
@OneToMany(targetEntity=Order.class,mappedBy="c")
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}为了便于演示延迟加载,在cn.itheima.test包下编写一个LoadTest单元测试类,并在该类中编写如下测试方法:
// 演示延迟加载
public class LoadTest {
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Customer c1 = session.load(Customer.class, 1);
// Customer c1 = session.get(Customer.class, 1);
String name = c1.getName();
System.out.println(name);
session.getTransaction().commit();
session.close();
}
}在String name = c1.getName();这句代码上加上一个断点,然后以Debug的方式调试该程序,就能得到你想要的东西哟!!!
如果将lazy设置为false,代表类级别检索也使用立即检索,这时load与get方法就完全一样了,都是立即检索。
虽然我们是知道了load方法采用的策略是延迟加载;get方法采用的策略是立即加载,但是什么时候用get方法,什么时候用load方法呢?——如果你查询的数据非常大,例如说它里面有一些大的字段,这个时候建议你采用load方法,不要一上来就立即加载,把我们的内存占满,这样可以让我们的性能得到一部分的提升;如果你查询的数据非常少,直接get就无所谓了,因为它不会占用我们很多的内存。
还有一个问题:Hibernate这个框架是在Dao层进行操作的,如果说我现在采用了一个load的方案去获取了一个对象,我们最终会把Session关闭再返回,那么我们就要把这个对象返回到Service层,再返回到Web层,这个时候load出来的代理对象其实还没有对数据进行初始化,也即它里面还没有真正有数据,返回的时候就出问题了,那如何对一个延迟的代理对象进行初始化呢?以码明示,在LoadTest单元测试类中编写如下测试方法:
public class LoadTest {
// 如果对一个延迟的代理对象进行初始化?
@Test
public void test2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Customer c1 = session.load(Customer.class, 1);
Hibernate.initialize(c1);
session.getTransaction().commit();
session.close();
// return c1;
}
}在Customer c1 = session.load(Customer.class, 1);这句代码上加上一个断点,然后以Debug的方式调试该程序,就能得到你想要的东西哟!!!
关联级别检索
查询到某个对象,获得其关联的对象或属性,这种就称为关联级别检索,例如:
c.getOrders().size()
c.getName()对于关联级别检索我们就要研究其检索策略(抓取策略)了。
检索策略(抓取策略)
抓取策略介绍
抓取策略指的是查找到某个对象后,通过这个对象去查询关联对象的信息时的一种策略。Hibernate中对象之间的关联关系有:
- 一对一:
<one-to-one> - 一对多(多对一):
<set>下有<one-to-many>,与<many-to-one> - 多对多:
<set>下有<many-to-many>
此处我们主要讲的是在<set>与<many-to-one>或<one-to-one>标签上设置fetch、lazy这两个属性。
- fetch主要描述的是SQL语句的格式(例如是多条,子查询,多表联查)
- lazy用于控制SQL语句何时发送
例如,查询一个客户,要关联查询它的订单。客户代表一的一方,在客户中有set集合来描述其订单,在配置中我们是使用的:
<set>
<one-to-many>
</set>此时就可以在set标签上设置这两个属性fetch、lazy。
再比如,查询一个订单时,要查询关联的客户信息。订单代表多的一方,在订单中有Customer对象来描述其关联的客户,在配置中我们是使用<many-to-one>标签,此时也可以在该标签上设置这两个属性fetch、lazy。当然了,也可在标签<one-to-one>上设置这两个属性fetch、lazy。
注解配置抓取策略
以一个问题来引出该小节的讲解,如何使用注解来配置抓取策略?
在
<set>标签上设置的fetch与lazy可以使用下面注解来描述:@Fetch(FetchMode.SUBSELECT)
@LazyCollection(LazyCollectionOption.EXTRA)
private Set<Order> orders = new HashSet<Order>();若是在映射配置文件中进行设置,则如下:

在
<many-to-one>或<one-to-one>标签上设置的fetch与lazy可以使用下面注解来描述:@Fetch(FetchMode.SELECT)
@LazyToOne(LazyToOneOption.FALSE)
private Customer c; // 描述订单属于某一个客户若是在映射配置文件中进行设置,则如下:

set上的fetch与lazy
set上的fetch与lazy主要是用于设置关联的集合信息的抓取策略。
fetch可取值有:
- SELECT:多条简单的sql(默认值)
- JOIN:采用迫切左外连接
- SUBSELECT:将生成子查询的SQL
lazy可取值有:
- TURE:延迟检索(默认值)
- FALSE:立即检索
- EXTRA:加强延迟检索(及其懒惰)
这样说来,fetch与lazy的组合就有九种了,其实不然,fetch与lazy的组合实际上只有七种,且听我娓娓道来。
第一种组合
首先修改cn.itheima.domain包下的两个PO类,如下:
客户类
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer { @Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名 // 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SELECT)
@LazyCollection(LazyCollectionOption.TRUE)
private Set<Order> orders = new HashSet<Order>(); public Customer() { } public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
} public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
} @Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
} }订单类
// 订单 ---- 多的一方
@Entity
@Table(name="t_order")
public class Order { @Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址 // 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
@Cascade(CascadeType.SAVE_UPDATE)
private Customer c; // 描述订单属于某一个客户 public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
} @Override
public String toString() {
return "Order [id=" + id + ", money=" + money + ", receiverInfo=" + receiverInfo + "]";
} }
接着在cn.itheima.test包下编写一个SetFetchTest单元测试类,并在该类中编写如下测试方法:
public class SetFetchTest {
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.得到id=1的Customer
Customer customer = session.get(Customer.class, 1);
// 2.得到id=1的Customer关联的Order信息
int size = customer.getOrders().size();
System.out.println(size);
session.getTransaction().commit();
session.close();
}
}在int size = customer.getOrders().size();这句代码上加上一个断点,然后以Debug的方式调试该程序,就能得出结论:会首先查询客户信息,当需要订单信息时,才会关联查询订单信息,并在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.id as id1_1_0_,
orders0_.id as id1_1_1_,
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.money as money2_1_1_,
orders0_.receiverInfo as receiver3_1_1_
from
t_order orders0_
where
orders0_.c_customer_id=?第二种组合
首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SELECT)
@LazyCollection(LazyCollectionOption.FALSE)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}然后以Debug的方式运行SetFetchTest单元测试类中的test1方法,就能得出结论:当查询客户信息时,就会将订单信息也查询,也就是说订单信息没有进行延迟查询。并在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.id as id1_1_0_,
orders0_.id as id1_1_1_,
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.money as money2_1_1_,
orders0_.receiverInfo as receiver3_1_1_
from
t_order orders0_
where
orders0_.c_customer_id=?第三种组合
首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SELECT)
@LazyCollection(LazyCollectionOption.EXTRA)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}然后以Debug的方式运行SetFetchTest单元测试类中的test1方法,就能得出结论:当查询客户信息时,不会查询订单信息,当需要订单的个数时,也不会查询订单信息,只会通过count来统计订单个数,当我们使用size()、contains()或isEmpty()方法时也不会查询订单信息。并在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?
Hibernate:
select
count(id)
from
t_order
where
c_customer_id =?第四种组合
如果fetch选择的是join方案,那么lazy它就会失效。生成SQl语句采用的是迫切左外连接(left outer join fetch),也即这个时候会多表联查,既然是多表联查,就会把信息都查询出来,它既然是一个迫切左外连接,会根据你的需求把信息封装到你指定的对象里面,所以lazy它就会失效。
为了测试这第四种组合,首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.JOIN)
@LazyCollection(LazyCollectionOption.FALSE)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}然后以Debug的方式运行SetFetchTest单元测试类中的test1方法,在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_,
orders1_.c_customer_id as c_custom4_1_1_,
orders1_.id as id1_1_1_,
orders1_.id as id1_1_2_,
orders1_.c_customer_id as c_custom4_1_2_,
orders1_.money as money2_1_2_,
orders1_.receiverInfo as receiver3_1_2_
from
t_customer customer0_
left outer join
t_order orders1_
on customer0_.id=orders1_.c_customer_id
where
customer0_.id=?第五种组合
首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SUBSELECT)
@LazyCollection(LazyCollectionOption.TRUE)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}接着在SetFetchTest单元测试类中编写如下测试方法:
public class SetFetchTest {
@SuppressWarnings("unchecked")
@Test
public void test2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.查询出所有的客户信息
List<Customer> list = session.createQuery("from Customer").list();
for (Customer customer : list) {
System.out.println(customer.getOrders().size());
}
session.getTransaction().commit();
session.close();
}
}在List<Customer> list = session.createQuery("from Customer").list();这句代码上加上一个断点,然后以Debug的方式调试该程序,就能得出结论:会生成子查询,但是我们在查询订单时采用的是延迟加载。并在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_,
customer0_.name as name2_0_
from
t_customer customer0_
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.id as id1_1_1_,
orders0_.id as id1_1_0_,
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.money as money2_1_0_,
orders0_.receiverInfo as receiver3_1_0_
from
t_order orders0_
where
orders0_.c_customer_id in (
select
customer0_.id
from
t_customer customer0_
)第六种组合
首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SUBSELECT)
@LazyCollection(LazyCollectionOption.FALSE)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}然后以Debug的方式运行SetFetchTest单元测试类中的test2方法,就能得出结论:会生成子查询,在查询客户信息时,就会将订单信息也查询出来。并在Eclipse控制台打印如下sql语句:
Hibernate:
select
customer0_.id as id1_0_,
customer0_.name as name2_0_
from
t_customer customer0_
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.id as id1_1_1_,
orders0_.id as id1_1_0_,
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.money as money2_1_0_,
orders0_.receiverInfo as receiver3_1_0_
from
t_order orders0_
where
orders0_.c_customer_id in (
select
customer0_.id
from
t_customer customer0_
)第七种组合
首先将客户类的代码改为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SUBSELECT)
@LazyCollection(LazyCollectionOption.EXTRA)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}然后以Debug的方式运行SetFetchTest单元测试类中的test2方法,就能得出结论:在查询订单时,只会根据情况来确定是否要订单信息,如果不需要,例如我们程序中的size操作,那么就会发出select count(*) from Order where c_customer_id=?这样的语句。这时Eclipse控制台会打印:
Hibernate:
select
customer0_.id as id1_0_,
customer0_.name as name2_0_
from
t_customer customer0_
Hibernate:
select
count(id)
from
t_order
where
c_customer_id =?
10
Hibernate:
select
count(id)
from
t_order
where
c_customer_id =?
10
Hibernate:
select
count(id)
from
t_order
where
c_customer_id =?
0many-to-one或one-to-one上的fetch与lazy
set上的fetch与lazy主要是设置在获取到代表一的一方时,如何去查询代表多的一方。那么在<many-to-one>或<one-to-one>标签上如何设置fetch与lazy,然后去查询对方。对于我们的程序来说,就是在代表多的一方如何查询代表一的一方的信息。例如,获取到一个订单对象,要查询客户信息。
fetch可取值有:
- select:默认值,代表发送一条或多条简单的select语句
- join:发送一条迫切左外连接
lazy可取值有:
- false:不采用延迟加载
- proxy:默认值,是否采用延迟不由本方说了算,而是需要由另一方的类级别延迟策略来决定
- no-proxy:在此不讨论
第一种组合
首先修改Order类的代码为:
// 订单 ---- 多的一方
@Entity
@Table(name="t_order")
public class Order {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址
// 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
@Cascade(CascadeType.SAVE_UPDATE)
@Fetch(FetchMode.SELECT)
@LazyToOne(LazyToOneOption.PROXY)
private Customer c; // 描述订单属于某一个客户
public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
}
@Override
public String toString() {
return "Order [id=" + id + ", money=" + money + ", receiverInfo=" + receiverInfo + "]";
}
}然后将Customer类的类级别延迟策略置为lazy=true,此时Customer类变为:
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
@Proxy(lazy=true)
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SUBSELECT)
@LazyCollection(LazyCollectionOption.EXTRA)
private Set<Order> orders = new HashSet<Order>();
public Customer() {
}
public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
}
}接着在cn.itheima.test包下编写一个OneFetchTest单元测试类,并在该类中编写如下测试方法:
public class OneFetchTest {
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.得到一个订单
Order order = session.get(Order.class, 1);
// 2.得到订单对应的客户
Customer c = order.getC();
System.out.println(c.getName());
session.getTransaction().commit();
session.close();
}
}在Order order = session.get(Order.class, 1);这句代码上加上一个断点,然后以Debug的方式调试该程序,就能得出结论:会首先发送一条sql只查询订单信息,客户信息会延迟,只有真正需要客户信息时,才会发送sql来查询客户信息。并在Eclipse控制台打印如下sql语句:
Hibernate:
select
order0_.id as id1_1_0_,
order0_.c_customer_id as c_custom4_1_0_,
order0_.money as money2_1_0_,
order0_.receiverInfo as receiver3_1_0_
from
t_order order0_
where
order0_.id=?
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?第二种组合
首先Order类的代码不用修改,只将Customer类的类级别延迟策略置为lazy=false,即在Customer类上加上@Proxy(lazy=false)注解。
然后以Debug的方式运行OneFetchTest单元测试类中的test1方法,就能得出结论:当查询订单时,就会将客户信息也查询到,原因是Customer类的类级别延迟策略为false,也就是立即查询。而且在Eclipse控制台打印如下sql语句:
Hibernate:
select
order0_.id as id1_1_0_,
order0_.c_customer_id as c_custom4_1_0_,
order0_.money as money2_1_0_,
order0_.receiverInfo as receiver3_1_0_
from
t_order order0_
where
order0_.id=?
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?第三种组合
首先将Order类的代码修改为:
// 订单 ---- 多的一方
@Entity
@Table(name="t_order")
public class Order {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址
// 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
@Cascade(CascadeType.SAVE_UPDATE)
@Fetch(FetchMode.SELECT)
@LazyToOne(LazyToOneOption.FALSE)
private Customer c; // 描述订单属于某一个客户
public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
}
@Override
public String toString() {
return "Order [id=" + id + ", money=" + money + ", receiverInfo=" + receiverInfo + "]";
}
}然后以Debug的方式运行OneFetchTest单元测试类中的test1方法,就能得出结论:当查询订单时,不会对客户信息进行延迟,会立即查询客户信息。而且在Eclipse控制台打印如下sql语句:
Hibernate:
select
order0_.id as id1_1_0_,
order0_.c_customer_id as c_custom4_1_0_,
order0_.money as money2_1_0_,
order0_.receiverInfo as receiver3_1_0_
from
t_order order0_
where
order0_.id=?
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?提示:这种组合不用理Customer类的类级别延迟策略。
第四种组合
首先将Order类的代码修改为:
// 订单 ---- 多的一方
@Entity
@Table(name="t_order")
public class Order {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址
// 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
@Cascade(CascadeType.SAVE_UPDATE)
@Fetch(FetchMode.JOIN)
@LazyToOne(LazyToOneOption.FALSE)
private Customer c; // 描述订单属于某一个客户
public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
}
@Override
public String toString() {
return "Order [id=" + id + ", money=" + money + ", receiverInfo=" + receiverInfo + "]";
}
}然后以Debug的方式运行OneFetchTest单元测试类中的test1方法,就能得出结论:如果fetch的值为join,那么lazy将失效,这时会发送一条迫切左外连接来查询,也就立即查询。而且在Eclipse控制台打印如下sql语句:
Hibernate:
select
order0_.id as id1_1_0_,
order0_.c_customer_id as c_custom4_1_0_,
order0_.money as money2_1_0_,
order0_.receiverInfo as receiver3_1_0_,
customer1_.id as id1_0_1_,
customer1_.name as name2_0_1_
from
t_order order0_
left outer join
t_customer customer1_
on order0_.c_customer_id=customer1_.id
where
order0_.id=?这种组合当然也就不需要搭理Customer类的类级别延迟策略了。
批量抓取
我们在查询多个对象的关联对象时,可以采用批量抓取方式来对程序进行优化。要想实现批量抓取,可以在映射配置文件中通过batch-size属性来设置,也可以使用注解@BatchSize(size=4)来设置,其中size表示一次抓取的条数。
先查询客户,然后再查询订单
首先检查两个PO类的代码是否如下:
客户类
@Entity
@Table(name="t_customer")
@Proxy(lazy=true)
public class Customer { @Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名 // 描述客户可以有多个订单
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Fetch(FetchMode.SELECT)
@LazyCollection(LazyCollectionOption.TRUE)
private Set<Order> orders = new HashSet<Order>(); public Customer() { } public Customer(Integer id, String name) {
super();
this.id = id;
this.name = name;
} public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
} @Override
public String toString() {
return "Customer [id=" + id + ", name=" + name + "]";
} }订单类
@Entity
@Table(name="t_order")
public class Order { @Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址 // 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
@Cascade(CascadeType.SAVE_UPDATE)
private Customer c; // 描述订单属于某一个客户 public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
} @Override
public String toString() {
return "Order [id=" + id + ", money=" + money + ", receiverInfo=" + receiverInfo + "]";
} }
为了查询出所有用户的订单信息,我在cn.itheima.test包下编写一个BatchFetchTest单元测试类,并在该类中编写如下测试方法:
// 演示批量抓取
public class BatchFetchTest {
// 查询出所有用户的订单信息
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.得到所有客户
List<Customer> list = session.createQuery("from Customer").list();
// 2.得到客户的订单信息
for (Customer customer : list) {
System.out.println(customer.getOrders().size());
}
session.getTransaction().commit();
session.close();
}
}运行以上方法,可发现Eclipse控制台打印如下:
Hibernate:
select
customer0_.id as id1_0_,
customer0_.name as name2_0_
from
t_customer customer0_
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.id as id1_1_0_,
orders0_.id as id1_1_1_,
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.money as money2_1_1_,
orders0_.receiverInfo as receiver3_1_1_
from
t_order orders0_
where
orders0_.c_customer_id=?
10
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.id as id1_1_0_,
orders0_.id as id1_1_1_,
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.money as money2_1_1_,
orders0_.receiverInfo as receiver3_1_1_
from
t_order orders0_
where
orders0_.c_customer_id=?
10
Hibernate:
select
orders0_.c_customer_id as c_custom4_1_0_,
orders0_.id as id1_1_0_,
orders0_.id as id1_1_1_,
orders0_.c_customer_id as c_custom4_1_1_,
orders0_.money as money2_1_1_,
orders0_.receiverInfo as receiver3_1_1_
from
t_order orders0_
where
orders0_.c_customer_id=?
0上述代码操作,当我们执行时,首先发出一条sql来查询所有客户信息,然后根据客户的id来查询订单信息,因为有三个客户,所以发送了三条sql,完成了查询订单信息的操作。以上一共执行了四条sql语句来完成操作,这就引出了一个N+1的经典问题。这里,就可以采用批量抓取来解决N+1问题。
我们不仅可以在客户类映射配置文件中的<set>标签上配置batch-size,如下: 
而且也可使用注解@BatchSize(size=3)来进行配置,即需要在Customer类中的orders属性上加上@BatchSize(size=3)注解。
这样再次运行test1方法,就可发现Eclipse控制台打印如下: 
提示:size的值要根据你当前的环境来设置,但是它的值不要太大,最好不要超过50。
先查询订单,然后再查询客户
为了查询出所有的订单,然后根据订单再查询出客户信息,我在BatchFetchTest单元测试类再编写如下测试方法:
public class BatchFetchTest {
// 查询出所有的订单,然后根据订单再查询出客户信息
@Test
public void test2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.得到所有订单
List<Order> list = session.createQuery("from Order").list();
// 2.得到客户信息
for (Order order : list) {
System.out.println(order.getC().getName());
}
session.getTransaction().commit();
session.close();
}
}运行以上方法,可发现Eclipse控制台打印如下:
Hibernate:
select
order0_.id as id1_1_,
order0_.c_customer_id as c_custom4_1_,
order0_.money as money2_1_,
order0_.receiverInfo as receiver3_1_
from
t_order order0_
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
t_customer customer0_
where
customer0_.id=?订单一共有两种,在查询时会首先发送一条sql查询出所有订单,然后再根据订单查询出所有客户,一共3条语句完成。这时也出现同样的N+1问题,当然也可以采用批量抓取来解决这个N+1问题。
注意:订单与客户,客户它是一个主表,订单是一个从表。在设置批量抓取时都是在主表中设置。故我们不仅可以在客户类映射配置文件中的<class>标签上配置batch-size,如下: 
而且也可使用注解@BatchSize(size=10)来进行配置,即需要在Customer类上加上@BatchSize(size=10)注解。
这样再次运行test2方法,就可发现Eclipse控制台打印如下: 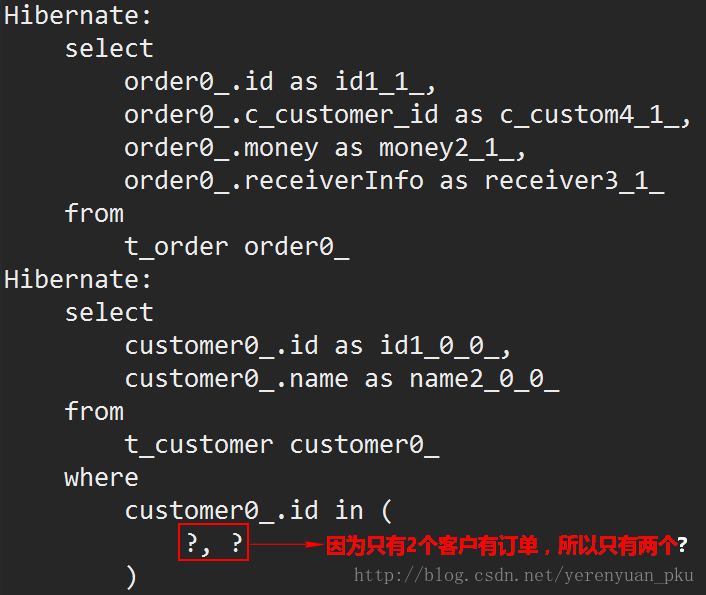
总结
无论是根据哪一方来查询另一方,在进行批量抓取时,都是在父方设置。如果是要查询子方信息,那么我们是在父方那个映射配置文件的<set>标签上来设置batch-size属性,如果是从子方来查询父方,也是在父方那个映射配置文件的<class>标签上设置batch-size属性。
父方与子方的区分:有外键的表是子方(从表),关联方就是父方(主表)。
(转)Hibernate的优化方案的更多相关文章
- Hibernate的优化方案
使用参数绑定 使用绑定参数的原因是让数据库一次解析SQL,对后续的重复请求可以使用生成好的执行计划,这样做节省CPU时间和内存. 避免SQL注入. 尽量少使用NOT 如果where子句中包含not关键 ...
- Hibernate检索策略(抓取策略)(Hibernate检索优化)
一.查询方法中get方法采用策略是立即检索,而load方法采用策略是延迟检索,延迟检索是在使用数据时才发送SQL语句加载数据 获取延迟加载数据方式:1.使用的时候,如果Customer c=sessi ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 大表优化方案(长文)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- [转帖] 数据库用优化方案 https://segmentfault.com/a/1190000006158186
Mysql大表优化方案 当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部 ...
- Tomcat 配置详解/优化方案
转自:http://blog.csdn.net/cicada688/article/details/14451541 Service.xml Server.xml配置文件用于对整个容器进行相关的配置 ...
- 一个网站完整详细的SEO优化方案
根据自己的个人经验完成了这篇文章,希望对SEOer有点帮助,高手直接跳过,请勿喷水... 一个完整的SEO优化方案主要由四个小组组成: 一.前端/页编人员 二.内容编辑人员 三.推广人员 四.数据分析 ...
- mysql 性能优化方案
网 上有不少MySQL 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- iOS界面跳转的一些优化方案
原文地址: http://blog.startry.com/2016/02/14/Think-Of-UIViewController-Switch/ iOS界面跳转的一些优化方案 App应用程序开发, ...
随机推荐
- Ubuntu 16.04安装设备管理器Hardinfo和lshw设备信息命令
安装: sudo apt-get install hardinfo 启动: 实际上这些信息都可以通过lshw进行查看,参考:https://linux.die.net/man/1/lshw
- Ubuntu 16.04安装Adobe AIR
安装: wget -O adobe-air.sh http://drive.noobslab.com/data/apps/AdobeAir/adobe-air.sh chmod +x adobe-ai ...
- 《深入理解PHP内核》
http://www.php-internals.com/ http://www.cnblogs.com/zcy_soft/category/252731.html
- python supervisor进程监控工具的使用
supervisor —— a process control system 另外一个类似 supervisor的工具,因为supervisor 不兼容python3, !!! Circus Proc ...
- 战术网络安全检查表 | Symantec Connect
"知己知彼,百战不殆: 不知彼而知己,一胜一负: 不知彼,不知己,每战必殆." 孙子(中国古代军事家). 孙子的话在今日仍能够使我们产生共鸣. 机构只有了解敌人和自己优缺点才能在持 ...
- datatables接口
/*资源表格接口*/ var dataTableHeader=function(elem,unSorts,defaultSort,screens,status,toggleVis,ipAddress, ...
- oracle11g 手工建库步骤
#create oracle instance parameter vi initkevin.or db_name='kevin' memory_target=0 sga_max_size=5G sg ...
- Android资源文件命名规范
在复杂Android应用的开发中,资源文件的规范命名非常重要,能帮助设计人员和开发人员减小沟通成本.资源的名字尽量力求准确,可以适当长一些,但换回的价值是值得的. 关于WCC的Android开发,资源 ...
- 【模板】 倍增lca
虽然很基础,但是还是复习了一下,毕竟比树剖好写... 代码: #include<iostream> #include<cstdio> #include<cmath> ...
- 【转载】HashMap实现原理浅析
HashMap和Hashtable的区别 两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全Hashtable的实现方法里面都添加了synchronized关键字来确保线程 ...