Cuder - 用C++11封装的CUDA类
以前写cuda:初始化环境,申请显存,初始化显存,launch kernel,拷贝数据,释放显存。一个页面大部分都是这些繁杂但又必须的操作,有时还会忘掉释放部分显存。
今天用C++11封装了这些CUDA操作,然后就可以专注于写kernel代码了。.cu文件就像glsl shader文件一样简洁明了。
例如:./kernel.cu文件,里面只有一个fill函数用于填充数组A。
extern "C" __global__ void fill(int * A, int cnt){
const int gap = blockDim.x*gridDim.x;
for (int id = blockDim.x*blockIdx.x + threadIdx.x; id < cnt; id += gap)
A[id] = id * ;
};
下面的main.cpp演示了Cuder类的使用。
#include "Cuder.h"
const int N = ;
std::string get_ptx_path(const char*); int main(){
int A[N]; for (int i = ; i < N; ++i) A[i] = i; //为禁止随意创建CUcontext,将构造函数声明为private,安全起见禁用了拷贝构造函数和拷贝赋值运算符
redips::Cuder cuder = redips::Cuder::getInstance(); //添加并编译一个.cu文件[相当于glsl shader 文件],或者直接添加一个ptx文件。
//std::string module_file = "kernel.cu";
std::string module_file = get_ptx_path("kernel.cu");
cuder.addModule(module_file); //显存上申请一个大小为[sizeof(int)*N]的数组,并将其命名为["a_dev"],用于后面操作中该数组的标识;
//如果第三个参数不为null,还会执行cpu->gpu的数据拷贝
cuder.applyArray("a_dev", sizeof(int)*N, A); //运行["./kernel.cu"]文件中指定的["fill"]函数, 前两个参数设定了gridSize和blockSize
//{ "a_dev", N }是C++11中的initializer_list, 如果是字符串则对应前面申请的显存数组名,否则是变量类型
cuder.launch(dim3(, , ), dim3(, , ), module_file, "fill", { "a_dev", N }); //将["a_dev"]对应的显存数组拷贝回[A]
cuder.fetchArray("a_dev", sizeof(int)*N, A);
return ;
} std::string get_ptx_path(const char* cuFile){
std::string path = "./ptx/"; #ifdef WIN32
path += "Win32/";
#else
path += "x64/";
#endif #ifdef _DEBUG
path += "Debug/";
#else
path += "Release/";
#endif
return path + cuFile + ".ptx";
}
cuder.addModule(...)函数的参数是一个.cu文件或者.ptx文件。
1. 如果是.cu文件,该函数负责将函数编译成ptx代码。然后封装到CUmodule里。
2. 如果是.ptx文件,该函数只是将ptx封装到CUmodule里。
建议使用第二种方式,nvidia的optix就是这么做的。好处是在编译阶段编译总比运行时编译好,如果代码有错误编译时就会提示。这时需要两点配置:
2.a 在生成依赖项里添加cuda 编译器,然后相应的.cu文件设定为用该编译器编译。
2.b 设定将.cu文件生成到指定路径下的ptx文件,然后在程序中指定该ptx文件的路径。
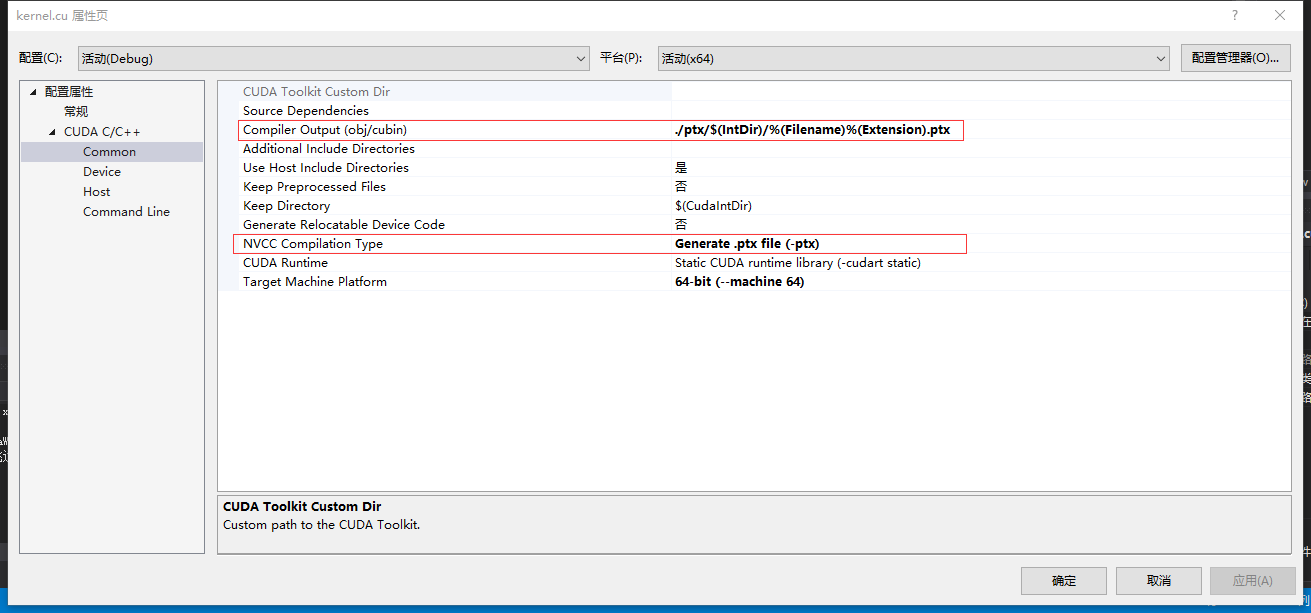
下面贴上Cuder.h的代码
#pragma once
#include <map>
#include <string>
#include <vector>
#include <cuda.h>
#include <nvrtc.h>
#include <fstream>
#include <sstream>
#include <iostream>
#include <cudaProfiler.h>
#include <cuda_runtime.h>
#include <helper_cuda_drvapi.h> namespace redips{
class Cuder{
CUcontext context;
std::map <std::string, CUmodule> modules;
std::map <std::string, CUdeviceptr> devptrs; Cuder(){
checkCudaErrors(cuCtxCreate(&context, , cuDevice));
}
void release(){
//for (auto module : modules) delete module.second;
for (auto dptr : devptrs) cuMemFree(dptr.second);
devptrs.clear();
modules.clear();
cuCtxDestroy(context);
}
public:
class ValueHolder{
public:
void * value = nullptr;
bool is_string = false;
ValueHolder(const char* str){
value = (void*)str;
is_string = true;
}
template <typename T>
ValueHolder(const T& data){
value = new T(data);
}
}; static Cuder getInstance(){
if (!cuda_enviroment_initialized) initialize();
return Cuder();
} //forbidden copy-constructor and assignment function
Cuder(const Cuder&) = delete;
Cuder& operator= (const Cuder& another) = delete; Cuder(Cuder&& another){
this->context = another.context;
another.context = nullptr;
this->devptrs = std::map<std::string, CUdeviceptr>(std::move(another.devptrs));
this->modules = std::map<std::string, CUmodule>(std::move(another.modules));
}
Cuder& operator= (Cuder&& another) {
if (this->context == another.context) return *this;
release();
this->context = another.context;
another.context = nullptr;
this->devptrs = std::map<std::string, CUdeviceptr>(std::move(another.devptrs));
this->modules = std::map<std::string, CUmodule>(std::move(another.modules));
return *this;
} virtual ~Cuder(){ release(); }; public:
bool launch(dim3 gridDim, dim3 blockDim, std::string module, std::string kernel_function, std::initializer_list<ValueHolder> params){
//get kernel address
if (!modules.count(module)){
std::cerr << "[Cuder] : error: doesn't exists an module named " << module << std::endl; return false;
}
CUfunction kernel_addr;
if (CUDA_SUCCESS != cuModuleGetFunction(&kernel_addr, modules[module], kernel_function.c_str())){
std::cerr << "[Cuder] : error: doesn't exists an kernel named " << kernel_function << " in module " << module << std::endl; return false;
}
//setup params
std::vector<void*> pamary;
for (auto v : params){
if (v.is_string){
if (devptrs.count((const char*)(v.value))) pamary.push_back((void*)(&(devptrs[(const char*)(v.value)])));
else{
std::cerr << "[Cuder] : error: launch failed. doesn't exists an array named " << (const char*)(v.value) << std::endl;;
return false;
}
}
else pamary.push_back(v.value);
} cudaEvent_t start, stop;
float elapsedTime = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, ); bool result = (CUDA_SUCCESS == cuLaunchKernel(kernel_addr,/* grid dim */gridDim.x, gridDim.y, gridDim.z, /* block dim */blockDim.x, blockDim.y, blockDim.z, /* shared mem, stream */ , , &pamary[], /* arguments */));
cuCtxSynchronize(); cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "[Cuder] : launch finish. cost " << elapsedTime << "ms" << std::endl;
return result;
}
bool addModule(std::string cufile){
if (modules.count(cufile)){
std::cerr << "[Cuder] : error: already has an modules named " << cufile << std::endl;;
return false;
} std::string ptx = get_ptx(cufile); if (ptx.length() > ){
CUmodule module;
checkCudaErrors(cuModuleLoadDataEx(&module, ptx.c_str(), , , ));
modules[cufile] = module;
return true;
}
else{
std::cerr << "[Cuder] : error: add module " << cufile << " failed!\n";
return false;
}
}
void applyArray(const char* name, size_t size, void* h_ptr=nullptr){
if (devptrs.count(name)){
std::cerr << "[Cuder] : error: already has an array named " << name << std::endl;;
return;
}
CUdeviceptr d_ptr;
checkCudaErrors(cuMemAlloc(&d_ptr, size));
if (h_ptr)
checkCudaErrors(cuMemcpyHtoD(d_ptr, h_ptr, size));
devptrs[name] = d_ptr;
}
void fetchArray(const char* name, size_t size,void * h_ptr){
if (!devptrs.count(name)){
std::cerr << "[Cuder] : error: doesn't exists an array named " << name << std::endl;;
return;
}
checkCudaErrors(cuMemcpyDtoH(h_ptr, devptrs[name], size));
} private:
static int devID;
static CUdevice cuDevice;
static bool cuda_enviroment_initialized;
static void initialize(){
// picks the best CUDA device [with highest Gflops/s] available
devID = gpuGetMaxGflopsDeviceIdDRV();
checkCudaErrors(cuDeviceGet(&cuDevice, devID));
// print device information
{
char name[]; int major = , minor = ;
checkCudaErrors(cuDeviceGetName(name, , cuDevice));
checkCudaErrors(cuDeviceComputeCapability(&major, &minor, cuDevice));
printf("[Cuder] : Using CUDA Device [%d]: %s, %d.%d compute capability\n", devID, name, major, minor);
}
//initialize
checkCudaErrors(cuInit()); cuda_enviroment_initialized = true;
}
//如果是ptx文件则直接返回文件内容,如果是cu文件则编译后返回ptx
std::string get_ptx(std::string filename){
std::ifstream inputFile(filename, std::ios::in | std::ios::binary | std::ios::ate);
if (!inputFile.is_open()) {
std::cerr << "[Cuder] : error: unable to open " << filename << " for reading!\n";
return "";
} std::streampos pos = inputFile.tellg();
size_t inputSize = (size_t)pos;
char * memBlock = new char[inputSize + ]; inputFile.seekg(, std::ios::beg);
inputFile.read(memBlock, inputSize);
inputFile.close();
memBlock[inputSize] = '\x0'; if (filename.find(".ptx") != std::string::npos)
return std::string(std::move(memBlock));
// compile
nvrtcProgram prog;
if (nvrtcCreateProgram(&prog, memBlock, filename.c_str(), , NULL, NULL) == NVRTC_SUCCESS){
delete memBlock;
if (nvrtcCompileProgram(prog, , nullptr) == NVRTC_SUCCESS){
// dump log
size_t logSize;
nvrtcGetProgramLogSize(prog, &logSize);
if (logSize>){
char *log = new char[logSize + ];
nvrtcGetProgramLog(prog, log);
log[logSize] = '\x0';
std::cout << "[Cuder] : compile [" << filename << "] " << log << std::endl;
delete(log);
}
else std::cout << "[Cuder] : compile [" << filename << "] finish" << std::endl; // fetch PTX
size_t ptxSize;
nvrtcGetPTXSize(prog, &ptxSize);
char *ptx = new char[ptxSize+];
nvrtcGetPTX(prog, ptx);
nvrtcDestroyProgram(&prog);
return std::string(std::move(ptx));
}
}
delete memBlock;
return "";
}
};
bool Cuder::cuda_enviroment_initialized = false;
int Cuder::devID = ;
CUdevice Cuder::cuDevice = ;
};
下面贴一下VS里面需要的配置
//include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.\include
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.\common\inc
//lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.\lib\x64 cuda.lib
cudart.lib
nvrtc.lib
Cuder - 用C++11封装的CUDA类的更多相关文章
- python+pytest接口自动化(11)-测试函数、测试类/测试方法的封装
前言 在python+pytest 接口自动化系列中,我们之前的文章基本都没有将代码进行封装,但实际编写自动化测试脚本中,我们都需要将测试代码进行封装,才能被测试框架识别执行. 例如单个接口的请求代码 ...
- jdbc 11: 封装自己的jdbc工具类
jdbc连接mysql,封装自己的jdbc工具类 package com.examples.jdbc.utils; import java.sql.*; import java.util.Resour ...
- MySQL JDBC事务处理、封装JDBC工具类
MySQL数据库学习笔记(十)----JDBC事务处理.封装JDBC工具类 一.JDBC事务处理: 我们已经知道,事务的概念即:所有的操作要么同时成功,要么同时失败.在MySQL中提供了Commit. ...
- DAO设计模式实现数据库的增删改查(进一步封装JDBC工具类)
DAO设计模式实现数据库的增删改查(进一步封装JDBC工具类) 一.DAO模式简介 DAO即Data Access Object,数据访问接口.数据访问:故名思义就是与数据库打交道.夹在业务逻辑与数据 ...
- 转:轻松把玩HttpClient之封装HttpClient工具类(一)(现有网上分享中的最强大的工具类)
搜了一下网络上别人封装的HttpClient,大部分特别简单,有一些看起来比较高级,但是用起来都不怎么好用.调用关系不清楚,结构有点混乱.所以也就萌生了自己封装HttpClient工具类的想法.要做就 ...
- .NET3.5中JSON用法以及封装JsonUtils工具类
.NET3.5中JSON用法以及封装JsonUtils工具类 我们讲到JSON的简单使用,现在我们来研究如何进行封装微软提供的JSON基类,达到更加方便.简单.强大且重用性高的效果. 首先创建一个类 ...
- MySQL数据库学习笔记(十一)----DAO设计模式实现数据库的增删改查(进一步封装JDBC工具类)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- MySQL数据库学习笔记(十)----JDBC事务处理、封装JDBC工具类
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- JAVA中封装JSONUtils工具类及使用
在JAVA中用json-lib-2.3-jdk15.jar包中提供了JSONObject和JSONArray基类,用于JSON的序列化和反序列化的操作.但是我们更习惯将其进一步封装,达到更好的重用. ...
随机推荐
- java中static学习总结
<<java编程思想>>: 1.static方法就是没有this的方法. 2.在static方法内部非静态方法. 3.在没有创建对象的前提下,可以通过类本身来调用static修 ...
- 根据View找控制器
- (UIViewController*)viewController { for (UIView* next = [self superview]; next; next = next.superv ...
- subclipse 和 eclipse结合遇到的问题
subclipse是eclipse的一个SVN插件.但是我在使用的时候不断的报出下面的错误: the applet is attempting to access the "exists&q ...
- nginx: 添加文件下载目录
修改nginx.conf,添加如下行: location /file/ { alias /usr/share/nginx/html/file/; add_header Content-di ...
- 闲聊ROOT权限——ROOT权限的前世今生
近期工作一直非常忙.居然慢慢地疏远了CSDN的博客,然而在工作中遇到问题,又会被多次的引导至CSDN,故笔者抽出时间也将自己学习的成果与大家分享在这里,希望能帮助到须要帮助的人. 本文将从几个方面,由 ...
- VS2012调试执行,网页打不开
360修复漏洞篇 TODO 修复了漏洞.vs2012在firefox和ie中都打不开 解决思路:360漏洞修复→已安装漏洞→卸载刚刚安装的漏洞 就可以解决 忽略漏洞 正常打开.
- C 基础 全局变量
/** 被static修饰的局部变量 1.只有一份内存, 只会初始化一次 2.生命周期会持续到程序结束 3.static改变了局部变量的生命周期, 但是不能改变局部变量的作用域 被static修饰的全 ...
- 跟我一起写Makefile:概述
什么是makefile?也许非常多Winodws的程序猿都不知道这个东西.由于那些Windows的集成开发环境(integrateddevelopment environment,IDE)都为你做了这 ...
- InnoDB: Error: log file .\ib_logfile0 is of different size 0 10485760 bytes
启动WAMP Server的时候报例如以下的错误: 140618 23:12:32 [Note] Plugin 'FEDERATED' is disabled. 140618 23:12:32 Inn ...
- The Breakpoint will not currently be hit. No executable code associated with this line
首先.请确认solutin的属性 C/C++->General-> Debug Information Format 选择Program Database(/Zi) Linking-> ...