Spring Cloud(8):Sleuth和Zipkin的使用
场景:
某大型电商网站基于微服务架构,服务模块有几十个。
某天,测试人员报告该网站响应速度过慢。排除了网络问题之后,发现很难进一步去排除故障。
那么:如何对微服务的链路进行监控呢?
Sleuth:
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。
根据系统大小不同,每一部分的结构又有一定变化。
譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分.
实时数据用于故障排查(troubleshooting):全量数据用于系统优化
数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性)
以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。
虽然每一部分都可能变得很复杂,但基本原理都类似。
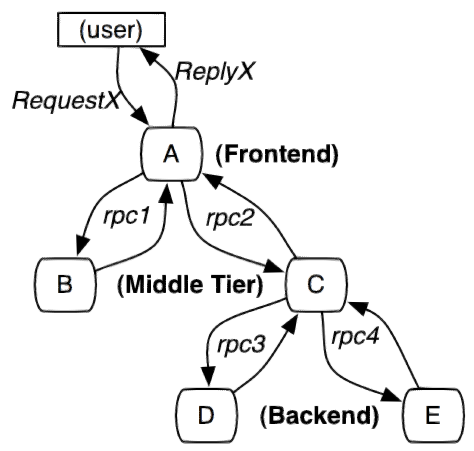
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始
到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。
每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。
这样,若干个有序的 span 就组成了一个 trace。
在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace。
把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。
附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务。
根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。
通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。
从而让我们可以很方便的理清各微服务间的调用关系。
此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
这是Spring Cloud Sleuth的概念图:
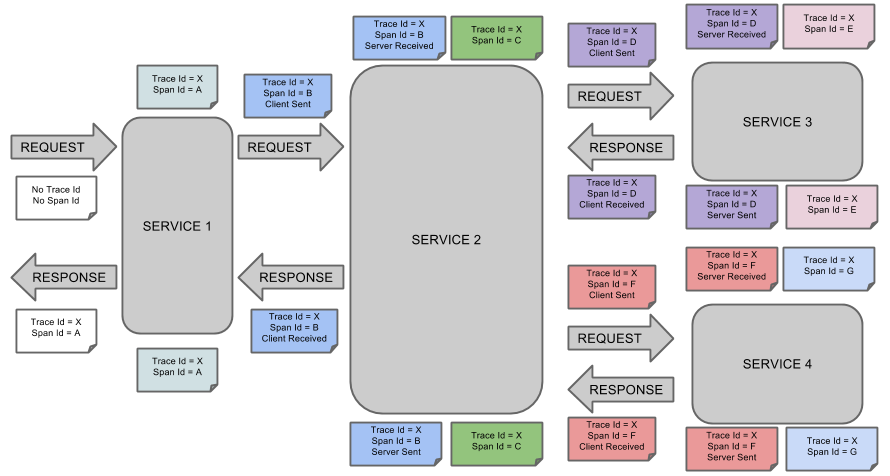
Sleuth的简单使用:
加入依赖
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-sleuth</artifactId>
- </dependency>
启动项目,发现会打印下面这些信息:
- [order-service,86028f5d0762bee1,d08375022720d818,false]
第一个参数:项目的名称,服务模块的名称:spring.application.name
第二个参数:TraceID:用来标识请求的一整条链路,一条链路只有一个TraceID
第三个参数:SpanID:基本的工作元,获取元数据
第四个参数:是否要把该信息输出到Zipkin服务中来收集和展示
ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源。
它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据
例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
快速上手
创建zipkin-server项目
项目依赖
- <dependencies>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-eureka</artifactId>
- </dependency>
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin-server</artifactId>
- </dependency>
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin-autoconfigure-ui</artifactId>
- </dependency>
- </dependencies>
启动类
- @SpringBootApplication
- @EnableEurekaClient
- @EnableZipkinServer
- public class ZipkinApplication {
- public static void main(String[] args) {
- SpringApplication.run(ZipkinApplication.class, args);
- }
- }
使用了@EnableZipkinServer注解,启用Zipkin服务。
配置文件
- eureka:
- client:
- serviceUrl:
- defaultZone: http://localhost:8761/eureka/
- server:
- port: 9000
- spring:
- application:
- name: zipkin-server
配置完成后依次启动示例项目:spring-cloud-eureka、zipkin-server项目。刚问地址:http://localhost:9000/zipkin/可以看到Zipkin后台页面
我采用了更方便快捷的方式:Docker
1、Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
- $ uname -r
2、使用 root 权限登录 Centos。确保 yum 包更新到最新。
- $ sudo yum update
3、卸载旧版本(如果安装过旧版本的话)
- $ sudo yum remove docker docker-common docker-selinux docker-engine
4、安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
- $ sudo yum install -y yum-utils device-mapper-persistent-data lvm2
5、设置yum源
- $ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo

6、可以查看所有仓库中所有docker版本,并选择特定版本安装
- $ yum list docker-ce --showduplicates | sort -r

7、安装docker
- $ sudo yum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0
- $ sudo yum install <FQPN> # 例如:sudo yum install docker-ce-17.12.0.ce

8、启动并加入开机启动
- $ sudo systemctl start docker
- $ sudo systemctl enable docker
9、验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
- $ docker version

Zipkin安装
执行命令:
- docker run -d -p 9411:9411 openzipkin/zipkin
然后访问http://[Docker机器的IP]:9411进入Zipkin可视Web界面
整合:
加入依赖
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-zipkin</artifactId>
- </dependency>
另外,Zipkin依赖包括了Sleuth依赖,可以删除上边引入的Sleuth依赖
配置Zipkin Server和该服务采样百分比(1为最大,生产环境不建议设置为1):
- spring.zipkin.base-url=http://[0.0.0.0]:9411/
- spring.sleuth.sampler.probability=1
访问Zipkin Server,刷新几次就会出现之前配置过的服务:
访问几次服务的接口,然后就可以针对某个服务进行链路分析
具体Zipkin界面的使用,不多做介绍了,中文界面操作不难

对请求链路进行追踪,就可以确定服务的哪一个模块更耗时,进而可以进行优化或者排BUG
因此,在开发环境中,部署Sleuth和Zipkin是比较重要的
以上部分内容参考博客:
http://www.cnblogs.com/jianliang-Wu/p/8945890.html
https://www.cnblogs.com/yufeng218/p/8370670.html
Spring Cloud(8):Sleuth和Zipkin的使用的更多相关文章
- Spring Cloud Edgware之后版本 Zipkin+Kafka整合
zipkin服务器端 1.依赖 <!-- zipkin server --> <dependency> <groupId>io.zipkin.java</gr ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- Spring cloud系列十四 分布式链路监控Spring Cloud Sleuth
1. 概述 Spring Cloud Sleuth实现对Spring cloud 分布式链路监控 本文介绍了和Sleuth相关的内容,主要内容如下: Spring Cloud Sleuth中的重要术语 ...
- 1 Spring Cloud Eureka服务治理
注:此随笔为读书笔记.<Spring Cloud微服务实战> 什么是微服务? 微服务是将一个原本独立的系统拆分成若干个小型服务(一般按照功能模块拆分),这些小型服务都在各自独立的进程中运行 ...
- Spring Cloud微服务实战阅读笔记(一) 基础知识
本文系<Spring Cloud微服务实战>作者:翟永超,一书的阅读笔记. 一:基础知识 1:什么是微服务架构 是一种架构设计风格,主旨是将一个原本独立的系统拆分成多个小型服务 ...
- 1 Spring Cloud Eureka服务治理(上)
注:此随笔为读书笔记.<Spring Cloud微服务实战>,想学习Spring Cloud的同伴们可以去看看此书,里面对源码有详细的解读. 什么是微服务? 微服务是将一个原本独立的系统拆 ...
- 1. Spring Cloud Greenwich SR2 概览
Spring Cloud provides tools for developers to quickly build some of the common patterns in distribut ...
- 1.入门篇十分钟了解Spring Cloud
文章目录 Spring Cloud入门系列汇总 为什么需要学习Spring Cloud 什么是Spring Cloud 设计目标与优缺点 设计目标 优缺点 Spring Cloud发展前景 整体架构 ...
- Spring Cloud 5分钟搭建教程(附上一个分布式日志系统项目作为参考) - 推荐
http://blog.csdn.net/lc0817/article/details/53266212/ https://github.com/leoChaoGlut/log-sys 上面是我基于S ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
随机推荐
- 正确使用MySQL JDBC setFetchSize()方法解决JDBC处理大结果集 java.lang.OutOfMemoryError: Java heap space
昨天在项目中需要对日志的查询结果进行导出功能. 日志导出功能的实现是这样的,输入查询条件,然后对查询结果进行导出.由于日志数据量比较大.多的时候,有上亿条记录. 之前的解决方案都是多次查询,然后使用l ...
- android 代码中及xml中设置透明
在布局文件的属性中,比如要设置一个LineaerLayout的背景为灰色透明.首先查RGB颜色表灰色是:#9E9E9E,AA代表透明,(透明度从00到FF,00表示完全透明),所以,设置其属性:and ...
- 洛谷 P2053 [SCOI2007]修车
题目描述 同一时刻有N位车主带着他们的爱车来到了汽车维修中心.维修中心共有M位技术人员,不同的技术人员对不同的车进行维修所用的时间是不同的.现在需要安排这M位技术人员所维修的车及顺序,使得顾客平均等待 ...
- [Python學習筆記] 抓出msg信件檔裡的附件檔案
想要把msg信件檔案的附件抓出來做處理,找到了這個Python 模組 msg-extractor 使用十分容易,但是這個模組是要在terminal裡執行,無法直接打在IDLE的編輯器上 所以稍微做了修 ...
- 如何处理Docker的错误消息request canceled:Docker代理问题
在本地安装Kubernetes时,遇到错误消息: request canceled while waiting for connection(Client.Timeout exceeded while ...
- Linux/Windows 实用工具简记
以下只是开发中可能用的比较多的工具,另外还有其他很多未曾提及的实用工具.Linux篇: 1.链接过程的调试:主要用于查看构建过程:如链接时加载的动态库以及运行时加载动态库过程的调试 支持LD_DEBU ...
- (译文)IOS block编程指南 4 声明和创建blocks
Declaring and Creating Blocks (声明和创建blocks) Declaring a Block Reference (声明一个block引用) Block variable ...
- 7-Java-C(小题答案)
1:58497 2:171700 3:145 4:i + j+2 == k+1 || i + k+2 == j+1 || k + j+2 == i+1 5:s + " " + (c ...
- 数组排序 sort
数组排序 this.dataShow = this.data.sort((a, b) => { return parseInt(a[this.innerOrderBy]) - parseInt( ...
- Eclipse 总是在编译的时候卡住
之前在开发Unieap项目的时候都是很正常,突然有一天早上总是出现Eclipse在编译的时候卡到34%的位置. 解决办法: 点击停止校验,一直卡在那里,首先在任务管理器杀死eclipse和javaw进 ...