js的基础(平民理解的执行上下文/调用堆栈/内存栈/值类型/引用类型)
与以前的切图比较,现在的前端开发对js的要求似乎越来越高,在开发中,我们不仅仅是要知道如何运用现有的框架(react/vue/ng),
而且我们对一些基础的知识的依赖越来越大。
现在我们就用平民的方法讲解下执行上下文/调用堆栈/内存栈。
理解下 javascript 在执行中,javascript 引擎(v8) 对我们加载的代码做了写什么?
我们整一段非常简单的 js 代码来分析 v8 引擎和执行上下文/调用堆栈/内存栈的关系。
<script>
var a = 1;
function say() {
var c = 4
console.log(c)
console.log(a)
var d = 5
}
console.log(b)
console.log(a)
say()
var b = 2;
</script>
1、在 v8 引擎加载到这段代码
2、引擎解析代码,创建一个 全局执行上下文(调用堆栈/内存栈)
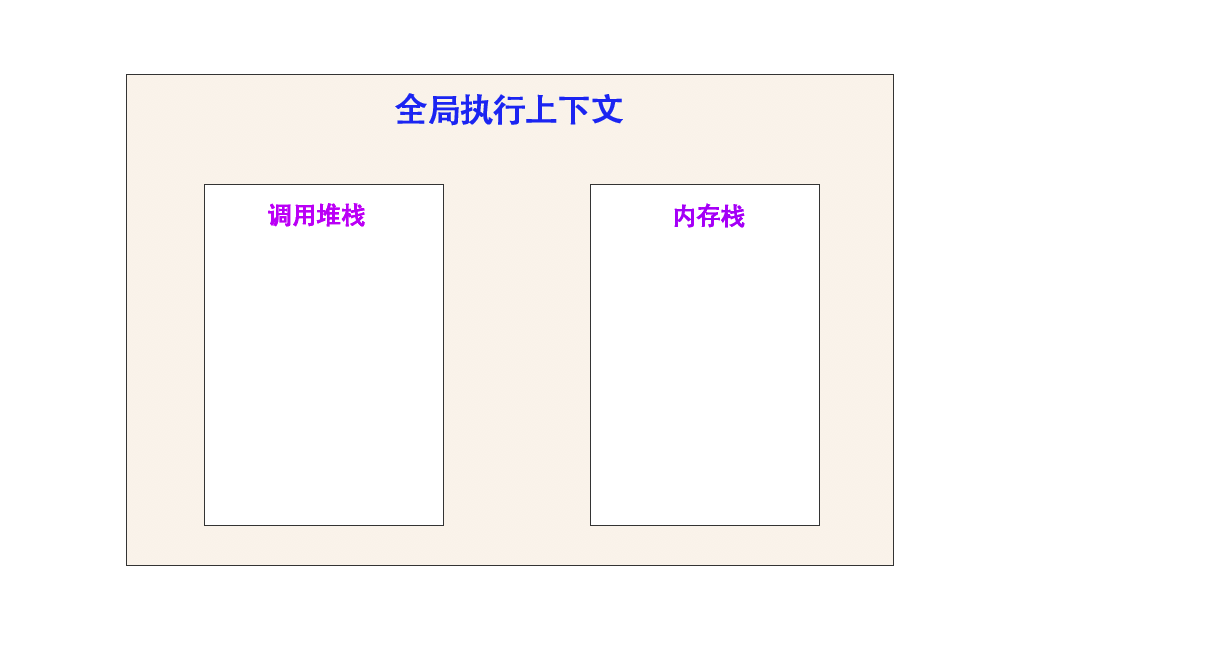
3、解析代码,将全局的所有的变量/声明函数添加到全局执行上下文的内存栈中。
这里会将 变量 a 和 b / 函数 say 添加到内存栈中。所有的全局的变量和函数都会添加进去
开始执行的样子:
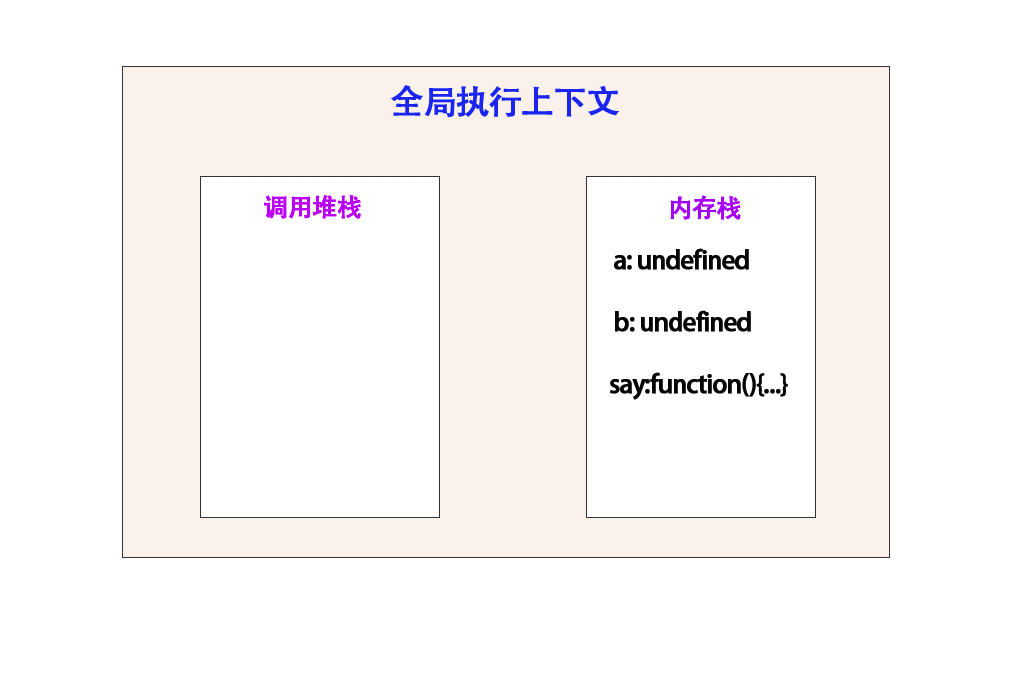
4.将全局的执行方法,都 push 到调用堆栈中
步骤 1 :
调用 console.log(b) 方法,执行到 console.log(b) 这一步的时候,全局执行上下文样子:
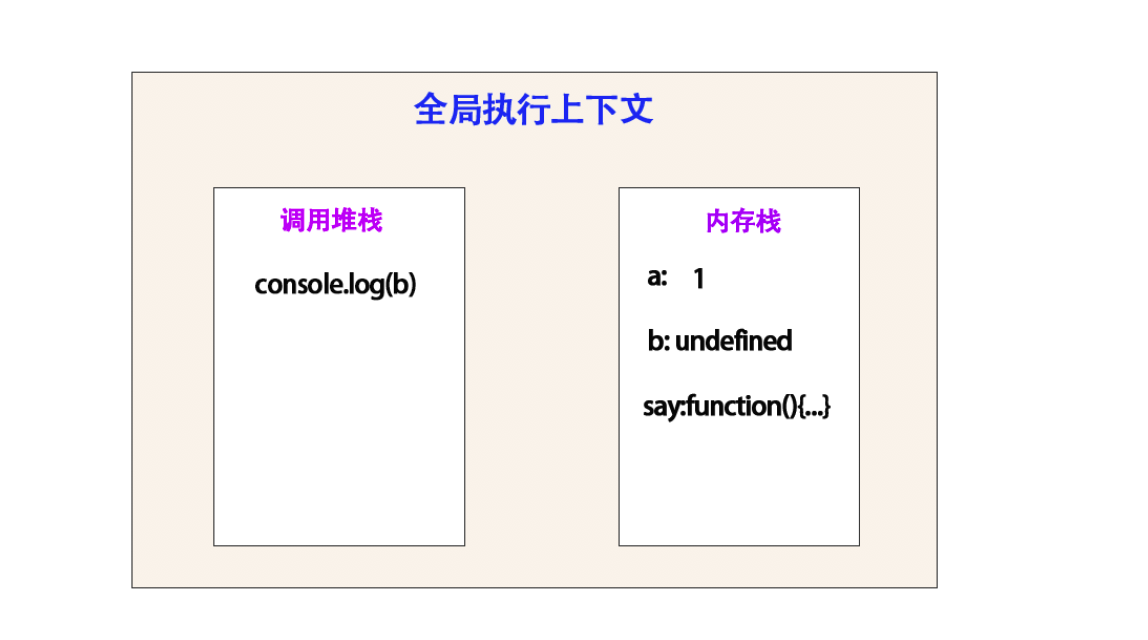
在从开始执行到这里的过程中,我们对一些变量做了赋值 a = 1 , b 并为赋值,仍是 undefined 。
这里打印的是一个 undefined
这里就是为什么会出现 变量提升 的原因
这里 console.log(b) 执行完成后,会直接 pop 弹出 调用堆栈。
步骤 2 :
调用 console.log(a) , 在console.log(b) 到 console.log(a) 并未有任何赋值操作。
所以内存栈中未有任何变化。
但是调用堆栈里面会有变化,在这里面console.log(b)已经执行完成,会被 pop 推出栈,然后到了console.log(a),试图样子:
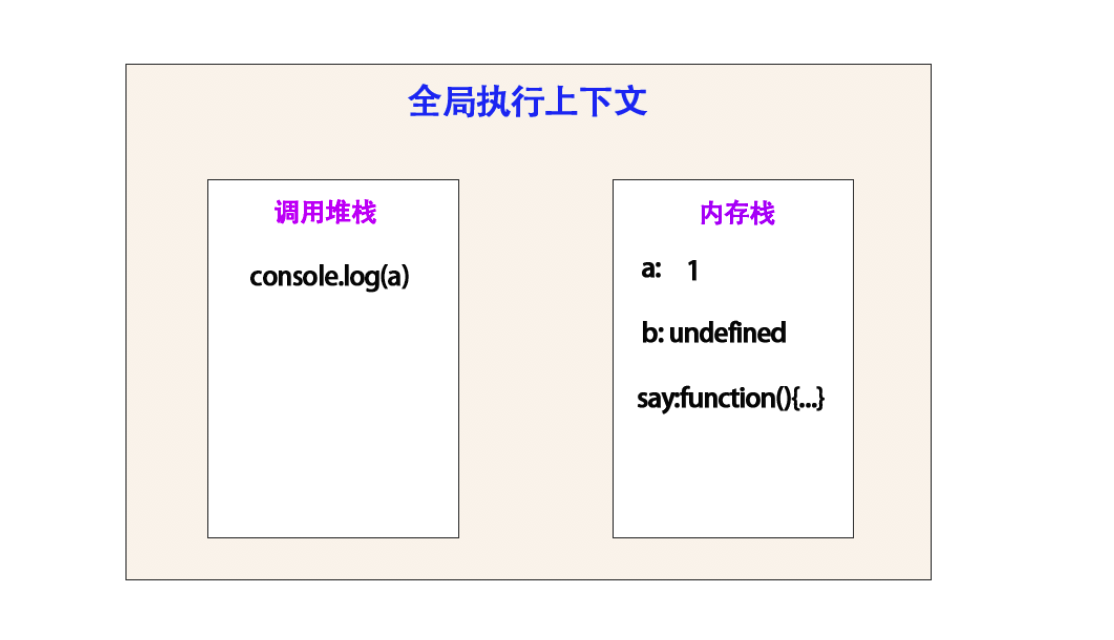
这里打印 a 是 1
结束完成之后,console.log(a) 会被弹出栈。
步骤 3:
调用 say() 函数,将 say() push 的调用堆栈中。
创建一个新的 say 的执行上下文。
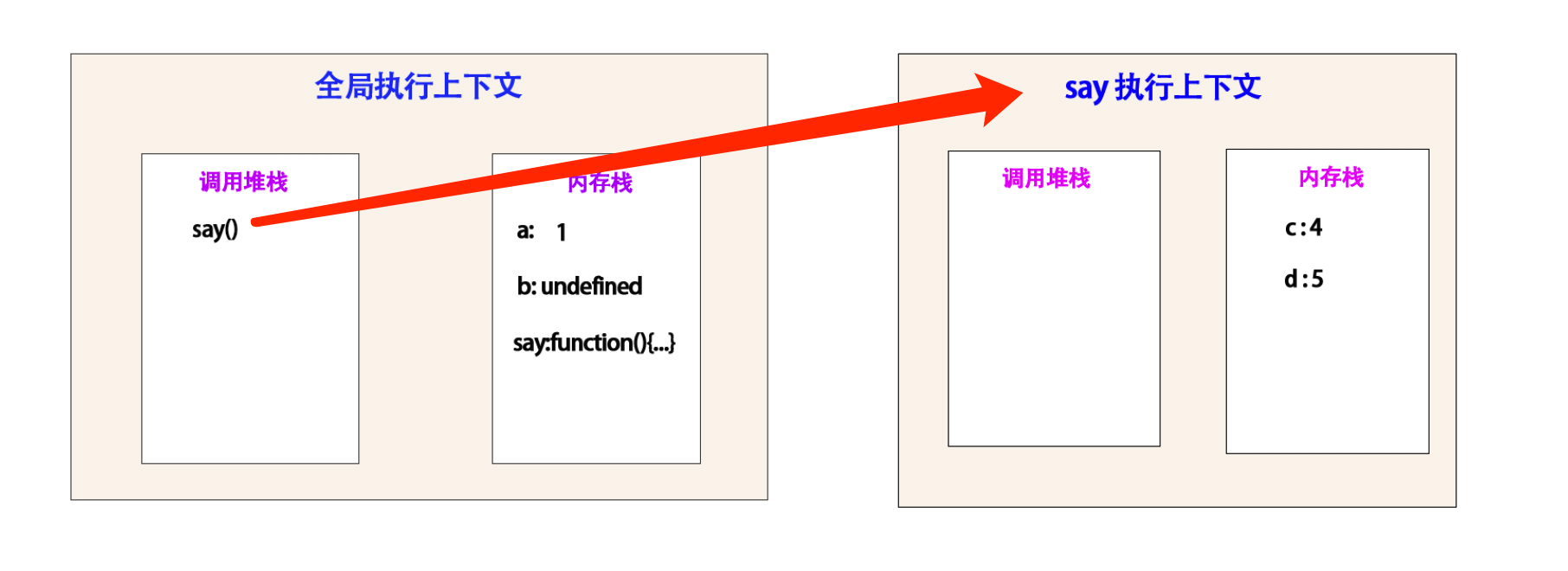
这里为 say 重新创建了一个 执行上下文 。并且将它内部的 变量和函数推入它对应的 内存栈 中。
将 c : 4 , d : 5 推到 内存栈中。
步骤 4 :
解析 say 函数,并且执行内部的 console.log(c) , console.log(a) 。
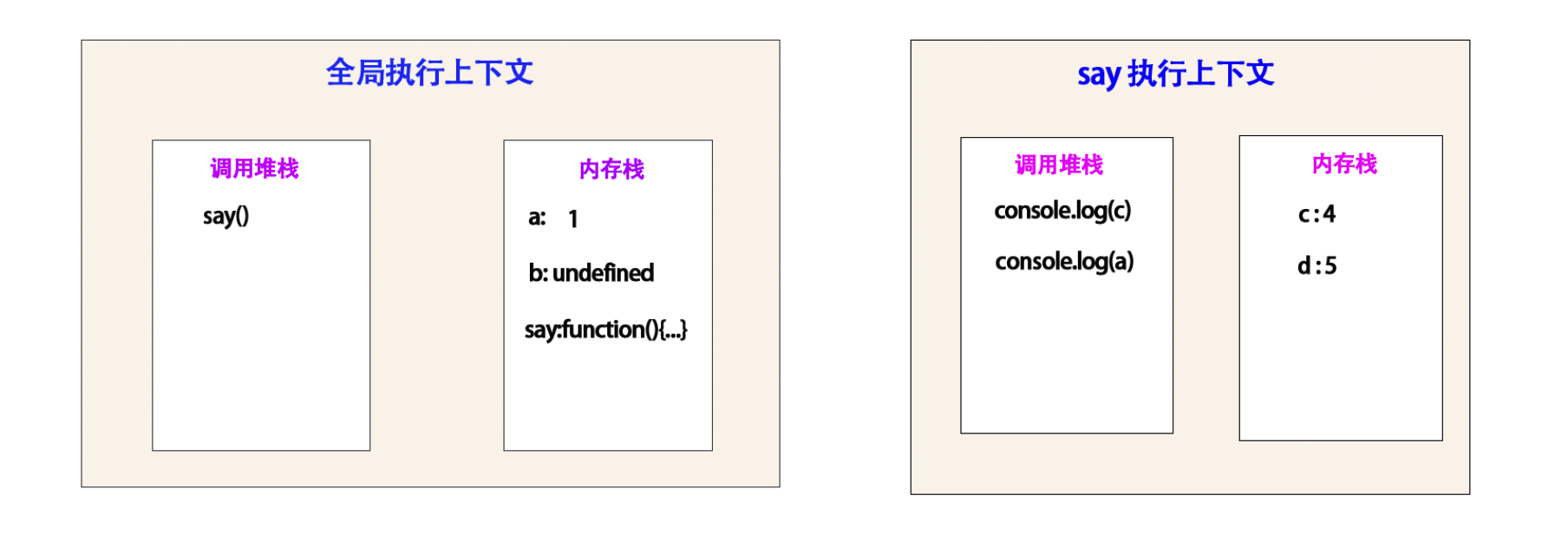
这里堆栈一次执行 console.log(c) , console.log(a) .
执行完成之后会被弹出来。
打印 4 , 5 。
步骤 5 :
当 say () 执行完毕后,回收内存栈已经调用栈。
完成!!
前端 javascript的 堆栈理解
在理解这些时候,我们可以先看下 值类型 和 引用类型,值类型 和 引用类型 的存储方式来区分前端的堆栈。
值类型/原始类型 : undefined 、null 、number 、string 、boolean
引用类型/堆类型 : object 、function 、array
值类型 :
保存在内存栈中,分配固定的空间,所以保存的值是不可变的。
js 代码执行的或者某个方法执行的时候,都会有自己独立的执行上下文,其中包括内存栈和调用栈,该执行上下文中定义的值类型就会保存在该内存栈中。
当该方法执行结束,这个内存栈就会销毁,值类型也随之移除
值类型的特点:
1、任何方法都无法改变值类型的
var name = 'xiao';
name.toUpperCase(); // 输出 'XIAO'
console.log(name); // 输出 'xiao'
该字符串调用了 toUpperCase() 方法,但是并未改变 name 的值
2、相同类型的值类型的比较是它们值的比较
相同类型的值类型在比较时候,只有它们的值相等,则它们才相等。
3、值类型都存放在内存栈中
上面已经介绍过了。
4、保存的是值本身的值,不是指向的地址。
引用类型:
值保存在堆内存中,占用的空间也不固定,所以保存的值是可以变的
当我们创建一个对象的时候,我们会将该对象保存在运行的内存堆中,以便与反复利用。
当被某一个变量引用的时候,会给变量该内存堆中的该对象的地址,并且把该对象的地址保存在内存栈中,而不是该对象的本身
当引用该变量所在的方法或者是执行上下文执行结束的时候,并不会销毁,只有在没有被任何引用的时候,该对象才会被销毁。
这里的这种销毁方法就是垃圾回收中的一种,叫做标记回收
标记回收( 以对象为例,当这个对象每被引用一次,就在该对象的标记上面 +1 ,当某一个引用该对象的变量不引用了就 -1 ,当
标记为 0 的时候,被系统检测到之后,就会销毁。 )
引用类型的特点:
1、引用类型的值是可变的
var obj = {a:1}
obj.b = 2
2、引用类型在内存栈中保存对象地址,在堆内存中保存对象的本身
3、引用类型的比较(===),是比较它们保存的对象的堆内存地址
4、引用类型的赋值,当给某一个变量复制的时候,实际是将该对象的堆内存地址复制给变量
总结 :
前端的基础(闭包,原型,作用域),在这里我们只要理解了执行上下文,我们就可以很好的区分作用域和闭包,
因为它们都相当于一个方法,当它们执行的时候,都会相应的创建自己的执行上下文,并且有自己的内存栈和调用栈。
当它们执行的时候都会对应的运用自己的内存中的变量。
值类型和引用类型的区分,我们能很快的作出类型的比较。
通过变量的存储方式来区分每一个变量的种类和功能。
js的基础(平民理解的执行上下文/调用堆栈/内存栈/值类型/引用类型)的更多相关文章
- JS底层知识理解之执行上下文篇
JS底层知识理解之执行上下文篇 一.什么是执行上下文(Execution Context) 执行上下文可以理解为当前代码的执行环境,它会形成一个作用域. 二.JavaScript引擎会以什么方式去处理 ...
- JS引擎是如何工作的?从调用堆栈到Promise
摘要: 理解 JS 引擎运行原理. 作者:前端小智 原文:JS引擎:它们是如何工作的?从调用堆栈到Promise,需要知道的所有内容 Fundebug经授权转载,版权归原作者所有. 为了保证可读性,本 ...
- 理解Javascript_02_执行上下文02
上一篇我们讲到在全局环境下的代码段中,执行上下文环境中如何处理数据: 变量.函数表达式——变量声明,默认赋值为undefined: this——赋值: 函数声明——赋值: 这篇文章讲关于函数执行上下文 ...
- 深入理解javascript执行上下文(Execution Context)
本文转自:http://blogread.cn/it/article/6178 在这篇文章中,将比较深入地阐述下执行上下文 - Javascript中最基础也是最重要的一个概念.相信读完这篇文章后,你 ...
- Js 作用域与作用域链与执行上下文不得不说的故事 ⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄
最近在研究Js,发现自己对作用域,作用域链,活动对象这几个概念,理解得不是很清楚,所以拜读了@田小计划大神的博客与其他文章,受益匪浅,写这篇随笔算是自己的读书笔记吧~. 作用域 首先明确一个概念,js ...
- 理解Javascript_02_执行上下文01
执行上下文又名执行上下文环境 JS中为什么会产生这个概念呢,先来看一下下面的这段代码: 通过执行发现,第一句代码报了ReferenceError,第二句和第三句代码是undefined,由于undef ...
- 深入理解JavaScript执行上下文、函数堆栈、提升的概念
本文内容主要转载自以下两位作者的文章,如有侵权请联系我删除: https://feclub.cn/post/content/ec_ecs_hosting http://blog.csdn.net/hi ...
- js 一些基础的理解
javascript(JS)的组成? DOM 文档对象模型 BOM 浏览器对象模型 ECMAScript javascript(JS)在页面中处理了什么事情? 特效交互 数据交互 逻辑操作 常见特效的 ...
- 30天C#基础巩固-----值类型/引用类型,泛型,空合并操作符(??),匿名方法
一:值类型/引用类型的区别 值类型主要包括简单类型,枚举类型,和结构体类型等,值类型的实例通常被分配在线程堆栈上面变量保存的内容是实例数据本身.引用类型被分配在托管堆上,变量保存的是地址.引 ...
随机推荐
- vuez init webStorm
<!-- * @description text !--> <template> <div>#[[$END$]]#</div> </templat ...
- docker环境安装
centos7安装docker环境 # step 1: 安装必要的一些系统工具 yum install -y yum-utils device-mapper-persistent-data lvm2 ...
- 自定义分隔符|/i|/x|/xs|需要转译
小骆驼 第八章 用正则表达式进行匹配 #!/usr/bin/envperl use strict; use warnings; $_ ="#adchbehnyhme3534f\nvdh5ej ...
- Supreme Number
A prime number (or a prime) is a natural number greater than 11 that cannot be formed by multiplying ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=15873837810484552531 中的1-14讲
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=1587383 ...
- 数组和String几种方法的需要注意的地方
array的方法总结 会更改原来的的数组 push.unshift方法,返回length.增加值得就返回length,其他返回该元素 pop,shift返回该元素 reverse返回该元素 splic ...
- JS获取粘贴内容
http://classjs.com/2013/03/05/js%E8%8E%B7%E5%8F%96%E7%B2%98%E8%B4%B4%E5%86%85%E5%AE%B9/ 思路:在编辑环境中,粘贴 ...
- 大数据学习——flume日志分类采集汇总
1. 案例场景 A.B两台日志服务机器实时生产日志主要类型为access.log.nginx.log.web.log 现在要求: 把A.B 机器中的access.log.nginx.log.web.l ...
- Leetcode 300.最长上升子序列
最长上升子序列 给定一个无序的整数数组,找到其中最长上升子序列的长度. 示例: 输入: [10,9,2,5,3,7,101,18] 输出: 4 解释: 最长的上升子序列是 [2,3,7,101],它的 ...
- HDU1757-A Simple Math Problem,矩阵快速幂,构造矩阵水过
A Simple Math Problem 一个矩阵快速幂水题,关键在于如何构造矩阵.做过一些很裸的矩阵快速幂,比如斐波那契的变形,这个题就类似那种构造.比赛的时候手残把矩阵相乘的一个j写成了i,调试 ...