Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货!
特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择)。
ChiSqSelector用于使用卡方检验来选择特征(降维)。即来特征选择。
我这里,采取手动创建。(但是,这仅仅是为了初学者。我不建议,最好用maven)
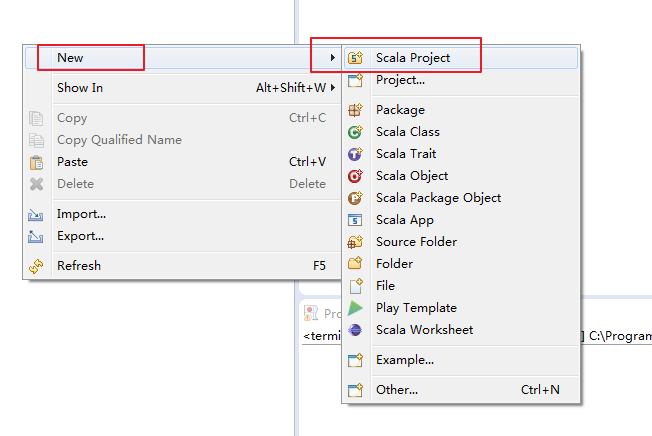





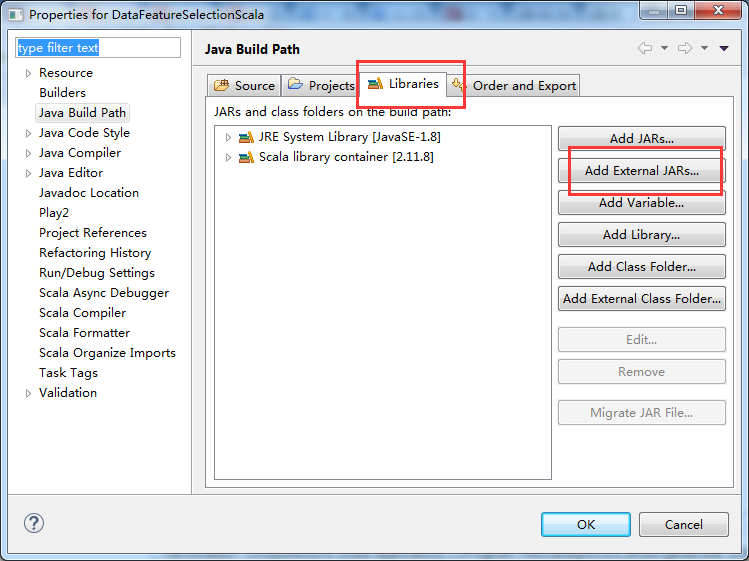


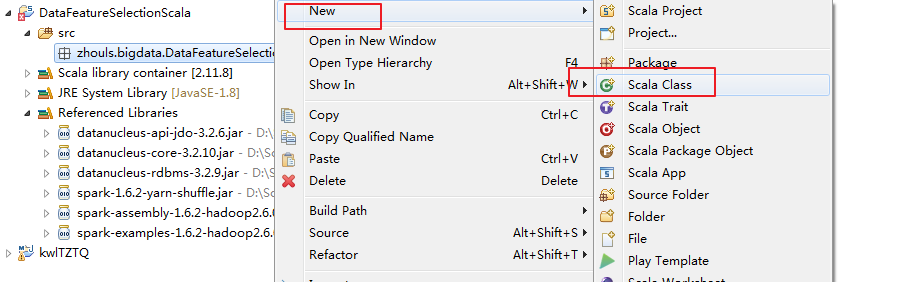

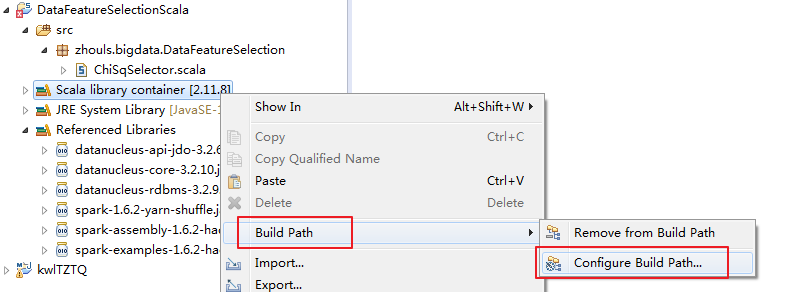


完整代码
ChiSqSelector .scala
package zhouls.bigdata.DataFeatureSelection import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.feature.ChiSqSelector//导入mi里的特征选择里的ChiSqSelector算法
import org.apache.spark.mllib.linalg.Vectors//特征向量 /**
* By zhouls
*/
object ChiSqSelector extends App { val conf = new SparkConf().setMaster("local").setAppName("ChiSqSelector")
val sc = new SparkContext(conf) val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._ //构造数据集
val data = Seq(
(, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = sc.parallelize(data).toDF("id", "features", "clicked")//将构造的数据集,转成DF,即DataFrame
df.select("id", "features","clicked").show() //使用卡方检验,将原始特征向量(特征数为4)降维(特征数为3)
val selector = new ChiSqSelector().setNumTopFeatures().setFeaturesCol("features").setLabelCol("clicked").setOutputCol("selectedFeatures") val result = selector.fit(df).transform(df)
result.show() }
由

变成

Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)的更多相关文章
- Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). VectorSlicer用于从原来的特征 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货! SparkSQL数据源:从各种数据源创建DataFrame 因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的 ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- rpm的gpg key
1 gpg 这是一种公钥.私钥机制. 2 rpm包的格式 rpm包由四部分构成,lead.signature.header和archive构成. 这里的签名(signature)是加密了的,也就是说, ...
- MessageBox_ swt
SWT有不同类型的对话框.有些对话框具有特殊的属性. MessageBox messageBox = new MessageBox(shell, SWT.OK|SWT.CANCEL); if (mes ...
- 微信小程序 navigateTo 传对象参数
当微信小程序navigateTo传入参数是个object时,请使用JSON.strtingify将object转化为字符串,代码如下: wx.navigateTo({ url: '../sendChe ...
- table 中的thead tbody
通过thead 下的tr 设置样式以及 tbody 下的 tr 设置样式 避免冲突 <table> <thead> <tr> <td> </td& ...
- centreon问题总结
1.SNMP TABLE ERROR : Requested table is empty or does not exist 这是SNMP的服务端查询客服端失败,失败的原理是权限不足 解决办法: v ...
- Why is an 'Any CPU' application running as x86 on a x64 machine?
It's likely that you linked some assemblies that are not Any CPU, but include native code (or are ...
- 关于js的值传递和引用传递
最近在弄一个东西,明明就很简单的.不知道为啥有个坑,双向绑定,不过当有个数组为空时,它不会发送空的数组,而是不发送.这就坑爹了.导致老是删不掉. 处理了下,改成验证为空时,发送'[]‘字符串.成功.但 ...
- 子元素margin带动父元素拖动
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- oracle实例的内存(SGA和PGA)调整,优化数据库性能
一.名词解释 (1)SGA:SystemGlobal Area是OracleInstance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池.数据缓冲区.日志缓冲区. (2) ...
- ES6 模板编译
顾名思义,就是用反引号编写一个模板字符串, 用echo将模板转为javascrip表达式字符串, 用正则将基础字符串转为想要字符串 将代码封装在函数中返回: 注: 用到es6属性${} var tem ...