TCP协议深度刨析
这篇文章主要是详细说明TCP的拥塞控制,因为它对于我们理解整个TCP/IP协议栈非常重要,但我
个人能力有限,其中引用了很多网上其他博主的文章,在下文引用处都有说明,主要是让整篇文章能够连贯,
不至于让所有知识点分散到网络中不同文章中,另外也加入很多自己的理解,仅希望能尽可能将这些复杂的
问题说明白,再次非常感谢这些道友的用心贡献,另外也希望每位学习者,能够耐心思考,浮躁是无法深入
其中的,同时更希望更多道友们能多多指教,让更多深入学习者少走点弯路。
在说明TCP拥塞控制前,先说明: 下面的有部分内容是摘自 “锐一网络”分享的三篇关于TCP的文章,连接如下:
http://www.a166.com/bases/2875.html
http://www.a166.com/bases/2879.html
http://www.a166.com/bases/2880.html
这三篇文章写得非常好,是关于TCP相当不错参考文章,但其中还有一些内容没有展开说明,而这些内容
也是理解整个TCP通信的关键之一,因此下面的内容会综合这三篇文章,以及其它的一些参考资料,加上自己
对网络的理解,尽可能将这些问题说明白。
net.ipv4.tcp_no_metrics_save=1
此选项是设置TCP连接缓存信息是否保存的,当Client与Server之间经过TCP三次握手建链后,
此信息会被缓存在Route Cache(路由缓存)中,其信息包含initcwnd,initrwnd,以及经过查表
(FIB: Forward Information Base:转发信息表)转发的路由信息,这些信息
在整个通信过程中会被重用,并且动态维护,主要动态更新的内容就是cwnd和rwnd,
它就是下面即将展开说明的TCP拥塞控制,也称为TCP慢启动,TCP滑动窗口机制等。
在展开说明前,先说下在Linux上手动调整initcwnd和initrwnd的方式:
ip route change IPAddr initcwnd 10 initrwnd 10
最初默认是1,从99年4月RFC2581中规定将其修改为4,13年4月RFC6928中规定其最大值可为10,它是什么?
简单说就是TCP在封装数据时,能封装的最大数据段的个数,一段数据最大是1460字节,但通常达不到这么大,
1024可能是最常见的,这主要由Server端应用程序决定,比如你可以百度网盘下载时抓包,或浏览器下载时抓包
看看; 而TCP最大段大小决定了,Server端一次最多能给Client发送多少数据,Linux默认是4,即Server端在给
Client发送数据时,向数据包中装4个最大1460字节的数据后,就不能在继续装了,就必须开始封装TCP报文了,
但事实上这样说是不对的,这是为了方便理解,没有区分应用层和TCP层,IP层而说的:
真实过程是:HTTP应用或其它应用层程序,将自己的数据按照一定的规范组织成数据,然后编码完成后,交给TCP层,
TCP层对其添加TCP报文首部,并检查数据包大小,若超过最大段大小(MSS:1460字节),则会拆分该数据报文,
拆分主要是为了TCP首部,IP首部,链路层首部字段在加入到TCP报文前面后,不至于整个数据包大于MTU(1500字节),
MTU是整个Internet通信的标准数据包大小,若超过它,发送设备必须将其拆分,否则只能丢弃!但是这不是绝对的,
因为若你是在一个私有网络中,其中的所有网络设备都有你控制,你完全可以调整它们的MTU大小,到最大1Gbyte,
早期是65536字节,这就涉及到TCP的窗口大小了和中间网络设备的缓存区大小,为了不混淆,再此不在深入展开;
现在对MTU有所了解后,就可以继续了,因为我们肯定不是内部自己玩,是需要向Client提供服务的,因此MTU是
不会改的;
接着上面说,数据包最大只能是1500字节,但是我们抓包看到的数据包很大,远远大于1500字节了,特别是下载
流量,这是为何?其实就是前面说的TCP分段,IP分片,即将一个大包拆分成多个小包,一次发送出去,每个
IP报文在进入到网线上变成比特流(电脉冲)经过中间网络设备,主要是路由器在选择到达目标的路径时,
需要根据不同的网络状态,这就是网络拥塞状况,会将不同IP分片发送到不同的路径上进行传输,因此就
出现了先发到数据包后到,后发动数据包先到的随机情况出现,当数据包到达目标端后,网卡会将收到的
IP报文发给内核,内核最终借助TCP/IP协议栈将IP分片组合成完整的TCP报文,最终交给上层应用。
在上面了解的基础上,在来展开TCP拥塞控制:
为何要说TCP拥塞控制?
因为TCP拥塞控制是影响TCP通信的关键点,只有清楚拥塞控制机制,才能理解TCP是如何运行的,
才能清楚网络慢的表象之下究竟发生了什么事导致网络慢的,以及如何去根据实际情况去优化TCP传输的关键。
拥塞控制的历史背景:
早在1984年 John Nagle就提出了一个被称为"拥塞崩溃"的现象,他是说 在一个负载较轻的网络中,一切都很正常,
一旦当网络处于繁忙状态时,很可能在几秒内瞬间瘫痪,这个问题的成因大概是这样的,在TCP/IP协议栈中规定A给B发包,
B必须在RTO(重传超时)内回应ACK报文给A,否则A将认为网络发送丢包了,于是又会给B发送上一个报文的副本,然后
又开始等待RTO超时,但是A和B根本不知道这时候他俩之间的网络正在发生什么事,而繁忙的网络就是在这个时候产生了问题,
因为网络中所有的路由器交换机它们都有处理能力上线,当它们处理不过来时会将数据包先缓存在自己的高速缓存中,
但是当高速缓存存满了,还是有更多的报文源源不断的发来时,它们只能采取丢失报文,以便保护网络不至于瘫痪,
让网络能够继续运行,但早期TCP/IP协议中并没有任何控制机制,能让A和B知道网络的繁忙状态,A和B只是知道我发的
报文丢包了,我就再重发一份,于是就出现恶性循环,中间的交换机路由器一旦丢包,就会马上有大量发包者收不到ACK,
于是它们开始疯狂的重传,导致中间的路由器交换机压力越来越大,最终导致网络在出现大量丢包后几秒内瞬间崩溃;
针对这种情况,John Nagle在1984年首次使用自己开发的算法尝试解决福特汽车公司的网络拥塞问题(RFC 896).
该问题的具体描述如下:
若我们的应用程序每次产生1个字节的数据,就发送出去一个数据包,在典型情况下,传送一个只拥有1个字节
有效数据的数据包,却要花费40个字节长的包头(IP头20字节 + TCP头20字节)的额外开销,这种有效载荷(payload)
利用率极其低下的情况被统称为愚蠢窗口症侯群(Silly Window Syndrome)可以看到,这种情况对于轻负载的网络来说,
可能还可以接受,但是对于重负载的网络而言,就极有可能承载不了而轻易的发生拥塞瘫痪,针对上面提到的这个状况,
Nagle算法的改进在于:
若发送端欲多次发送包含少量字符的数据包(一般情况下,后面统一称长度小于MSS的数据包为小包,等于MSS的包为
大包,为了某些对比说明,还有中包,即大包和小包之间的包),则发送端会先将第一个小包发送出去,而将后面到达的
少量字符数据都缓存起来而不立即发送,直到收到接收端对前一个数据包报文段的ACK确认、或当前字符属于紧急数据,
或者积攒到了一定数量的数据(比如缓存的字符已经达到数据报文段的最大长度)等多种情况才将其组成一个较大的数据包
发送出去。这样就能很大程度上减少发送到网络中的数据包数量。TCP中Nagle算法默认是启用的,但是它并不是适合
任何情况,对于实时性要求很高的应用来说,它就非常不适合,比如:ssh,telnet,还有网络游戏程序中体现的最为突出,
因为服务器要实时跟踪Client的鼠标移动,来驱动画面的不同动作,若采用Nagle算法将会导致Client程序运行缓慢。
而对于实时性要求不高的应用来说,它的效率就非常高效,而且可提供网络的利用率。
但是Nagle算法并没有真正解决网络拥塞问题,1986年,随着加入网络的节点数量(5000+)及类型日益增多,
ARPANET网络中发生了一系列拥塞崩溃故障。个别情况下,容量每下降千分之一,网络就有可能完全瘫痪。为了
解决这些问题,1988年TCP加入了很多机制,以便控制双向发送数据的速度,比如流量控制、拥塞控制和拥塞预防机制。
这些就是 Van Jacobson和Michael J.Karels撰文描述的这些问题的几种算法解决方案:慢启动、拥塞预防、快速重发和
快速恢复。这4种算法很快被写进了TCP规范。事实上,正是由于这几种算法加入TCP,才让因特网在20世纪80年代末
到90年代初流量暴增时免于大崩溃。要理解慢启动,最好看一个例子。
假设纽约有一个客户端(B),尝试从位于伦敦的服务器(A)上取得一个文件。
首先,三次握手,而且在此期间双方互相通过ACK分组通告自己的接收窗口(rwnd)大小(即: 自己一次能接收多少数据),
在发送完最后一次ACK分组后,就可以交换应用数据了。

实际上此时A和B它俩互相交换了接收窗口大小(rwnd),指定就是Windows Size,这个值是不断调整的,也是TCP慢启动
调整的主要值。当A和B都知道对方一次能接受的最大数量后,是按照rwnd来传输数据吗?
其实不是,rwnd可理解为A和B通信传输数据的理想值,而实际上A和B之间的网络错综复杂,瞬息万变,无法按照固定
的大小来发送数据包,这也是TCP拥塞控制被提出的原因,如何解决?
cwnd就被提出了,它是窗口拥塞大小,A和B之间通信是不交换这个值,默认Linux系统上initcwnd就是该变量的默认值,
在实际传输数据时,TCP/IP协议栈实际是按照rwnd和cwnd之中选出最小值来作为初次数据传输的最大值,那这样的话,
cwnd似乎还是固定值呀?但实际上cwnd的值是变化的,它基于TCP慢启动来逐渐指数递增的,当增加到一定程度后,
就会线性递增,这就是TCP慢启动算法中的AIMD(加法增大乘法减小)。
https://blog.csdn.net/jtracydy/article/details/52366461 摘录如下:
1. 乘法减小:无论在慢启动阶段还是在拥塞控制阶段,只要网络出现超时,就是将cwnd置为1,ssthresh置为cwnd的一半,
然后开始执行慢启动算法(cwnd<ssthresh)。
2. 加法增大:当网络频发出现超时情况时,ssthresh就下降的很快,为了减少注入到网络中的分组数,而加法增大是指执行
拥塞避免算法后,是拥塞窗口缓慢的增大,以防止网络过早出现拥塞。
这两个结合起来就是AIMD算法,是使用最广泛的算法。拥塞避免算法不能够完全的避免网络拥塞,通过控制拥塞窗口
的大小只能使网络不易出现拥塞。
TCP慢启动 和 TCP拥塞控制
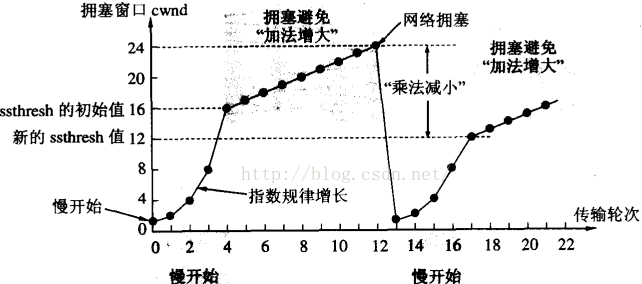
cwnd: 它的默认值就是开头说的4个段,随后增加就是8,16,这样递增,如下图,指数递增是有限度的,当达到慢启动
门限(ssthresh)的变量值时,TCP慢启动就结束了,它就会转为线性增加,即每次增加1个段,当出现丢包(网络拥塞),就会
出现惩罚,即乘法减小,这个阶段就属于TCP拥塞控制。
下面两张图从我的理解上来看都不完全精确:
我的分析如下:
第一张图很清楚的描述了TCP慢启动和TCP拥塞控制,但是我需要知道 TCP是贪婪递增,减半惩罚,即当出现丢包时,
TCP会根据当前cwnd的最大值,砍掉一半后,延时后再次尝试发送数据包,这时需要注意,若当前cwnd砍半后,其值
没有小于初始慢启动门限值,TCP是不会再次进入慢启动的,第二张图中描述的就是这种场景,此时TCP只会进入TCP
拥塞控制阶段,即减半后,每次增加1个段,来重新尝试当前链路的最大可用带宽,直到再次丢包时,又会砍半。
这里需要注意:按第二张图的理解,你可能会想,我在130的时候丢包了,砍半到60,那我又增长到130,又砍半到60,
这不就是死循环了吗?其实不是,因为网络是动态的,也许在丢包时,是因为瞬间峰值导致中间设备丢包,但峰值过后,
网络带宽再次恢复到正常水平,这时就可能在130时,不会丢包,而是继续增加,还有可能是,还没到130,在90时,
就已经再次丢包了,那这时砍半就是45了,若低于慢启动门限ssthresh,则会将cwnd强制修改为1,因为若不修改的话,
在慢启动期间,它是指数增长,45x2就又回到90了,那就没有TCP慢启动就没有意义了,所以必须将其cwnd设置为1,
这就为啥说下面两张图都不精确,因为他们其实看到角度不同,若当前网络带宽很小,就会出现第一张图的情况,
当网络出口带宽很大,就会出现第二张图的情况,所以我们需要注意,网络是动态,它不是静止不动!
为何TCP慢启动要指数增长? 因为A和B建链初期,谁也不知道我们之间的网络状况如何,那发多大数据包合适?
大家都不知道,那就一个办法,尝试!先按默认值4 来发,发送一会儿后,发现不丢包,说明当前网络状态很好,
接着就将数据发送量翻倍,在发送一会儿看看,若依然没有丢包,继续翻倍,当到达ssthresh时,停止翻倍递增,
改为线性递增,也是一样,直到丢包。

下面这篇文章介绍了TCP慢启动对应用程序的影响:
https://blog.csdn.net/guangyinglanshan/article/details/79027849
他是从开发的角度来说明TCP慢启动的,很有参考价值,因为他会让你知道,TCP慢启动的过程是非常快,
仅有几十毫秒,那为啥要关注TCP慢启动那?他也说了TCP慢启动对自己应用的影响,所以,在这里我们需要
关注它,知道它是什么,才能知道在什么环境下,我需要关闭TCP慢启动,什么时候需要启用它。
接着我们来说慢启动有什么影响?
从上文开发的视角知道了TCP慢启动只有几十毫秒,但你要想象一下,当你的用户达到1万,10万,1亿....
基数增大后,这几十毫秒是多少那?在这么多访问量的情况下,这几十毫秒内,所有连接都不能完全使用出口
带宽的全量,而且TCP的慢启动是对所有上层应用其作用的,除非你不使用TCP来建立网络通信的虚电路。
下面是从理论计算的视角来说TCP慢启动的延时:
假设客户端和服务器的接收窗口为65535字节(64KB),而初始的拥塞窗口为4段(RFC2581)
说明:
接收窗口就是上面TCP数据包结构图中Windows Size,WindosSize只是一个控制Payload部分实际有多大的开关,
Payload是我们真正传输的数据区,WindowSize默认是16bit,经过计算2的16次方,就是65535,MSS(最大段大小)是
1460字节,必须知道一个网络传输的数据包最大是1500(MTU)大小,1460+40(TCP头+IP头+链路头)=MTU.
MTU大小的数据包是实际在网络中传输的单个包大小,但Payload的大小最大是65536字节,因此就需要在TCP和IP
层做分片,实际是IP层分片的,分片后单个上层的大包就变成了多个标准小包,这就是为啥,我要强调!
知道了这些后,接着来说滑动窗口机制中的窗口扩大因子:
window_scaling: 此TCP选项叫 窗口扩大因子, 它仅在TCP连接初始化时有效,即: 在A要和B建立TCP会话时,
A在发送SYN包时,设定后,双方通过协商接收通告窗口扩大因子数后,两端后续TCP会话将使用,
该扩大因子来提高两端数据吞吐量。一般通告窗口大小是16位,即最大为65535字节。
窗口: 可简单理解为它决定了最大报文段长度(Max Segment Size,MSS).
但实际上TCP窗口大小不止16位,若要提高TCP通信的吞吐量,可以调整窗口扩大因子,
假定TCP头部中接收通告的窗口大小为N,窗口扩大因子(Offset:移位数)是M, 则TCP报文段的实际
接收通告窗口大小是N*2^M, 而M的取值范围0~14。所以TCP最大支持的报文段是0~1G.
1G=N*2^M = 2^16 * 2^14 = 2^30字节
启用方式: echo 1 > /proc/sys/net/ipv4/tcp_window_scaling
有了以上基础后,我们在来看下面的公式:
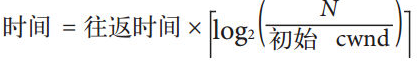

第二张图描述的是,当TCP的Payload达到最大65535字节后,约为45个段,默认Linux的拥塞窗口大小
cwnd是4,这是1999年4月RFC2581中规定的,最早是1个段,所以当你看到有文章说cwnd=1,也不要见怪,
因为他说的是99年之前的规定; 经过第二个计算公式,就可以知道从TCP慢启动到最大段传输,大概是需要224毫秒。
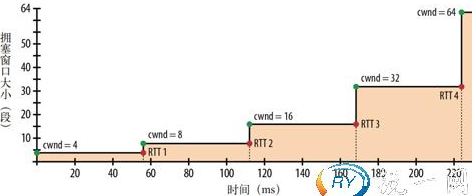
为减少增长到拥塞窗口的时间,可以减少客户端与服务器之间的往返时间。
一种方式: 把服务器部署到地理上靠近客户端的地方。
第二种方式: 就把初始拥塞窗口大小增加到RFC 9828规定的10段,也就是前面说的initcwnd=10,initrwnd=10.
从上面的计算可大概知道,慢启动导致客户端与服务器之间经过几百毫秒才能达到接近最大速度的问题,
对于大型流式下载服务的影响倒不显著,因为慢启动的时间可以分摊到整个传输周期内消化掉。可是,对于
很多HTTP连接,特别是一些短暂、突发的连接而言,常常会出现还没有达到最大窗口请求就被终止的情况。
换句话说,很多Web应用的性能经常受到服务器与客户端之间往返时间的制约。因为慢启动限制了可用的吞吐量,
而这对于小文件传输非常不利。慢启动重启除了调节新连接的传输速度,TCP还实现了SSR(Slow-StartRestart,
慢启动重启)机制。
这种机制会在连接空闲一定时间后重置连接的拥塞窗口。道理很简单,在连接空闲的同时,网络状况
也可能发生了变化,为了避免拥塞,理应将拥塞窗口重置回“安全的”默认值。毫无疑问,SSR对于那些会
出现突发空闲的长周期TCP连接(比如HTTP的keep-alive连接)有很大的影响,因为虽然Server和Client
之间的TCP虚电路没有拆除,但是因为Client有一段时间没有访问Server了,这时间可能是2分钟以上,
Client和Server之间的网络状况是什么样,它俩都不知道,因此为了避免出现网络拥塞,Server会将cwnd
重置为默认的initcwnd,rwnd也是,这是为了避免这种默认行为,在Linux可以修改内核参数:
sysctl -w net.ipv4.tcp_slow_start_after_idle=0
来关闭,这需要根据实际情况来确定。
在一个就是要回到文章开头,tcp_no_metrics_save,此参数其实也需要注意,因为
Client和Server之间的网络是动态的,cwnd就是动态,而此参数是开启route cache的,而此缓存会缓存
Server去往Client的路由信息,以及TCP重新连接时一些默认值,这些默认值就包含cwnd,因为路由缓存
是有期限的,可能二三分钟,在这段时间Linux为了避免总是查询FIB(路由转发表),以及总是要去获取TCP
建链时的一些默认参数,它会将这些参数缓存起来,这样本身是好的,但是对于网络不稳定的环境来说,
影响就很大,特别是移动网络,即移动客户端。因为此路由缓存数据会对使用此条路由缓存的所有新建
TCP连接都有效,原本想优化网络,结果因为偶尔的丢包,导致该Client后续新的TCP连接逼迫使用这些
默认参数,而若不使用route cache,那么与该Client后续新的TCP连接就不会使用缓存中的cwnd值,而是
使用initcwnd。但你也要知道,关闭route cache的影响是,每次路由转发都有查询FIB,这对性能是会带来
影响的,因此要权衡利弊。这也就是有时候为何要关闭它的原因。
在来补充一点:关于选择确认SACK的说明:
SACK: Selective Acknowledgment(SACK, 选择性确认):它在TCP选项部分,当kind=4,5时才有效.
即TCP通信时,会出现丢包,所以就有了TCP重传机制.
早期TCP重传:假如A给B发了一组包,序号从1百~2百,结果传递过程中150~165丢了,B确认了149,然后
确认了166及以后的,而A端则从150开始重传150~200的所有的包。这就造成了资源浪费.
新TCP重传:依然上上面的情况,假如现在丢了120~133,155~170都丢了,这时B确认时,它会告诉A,我
收到了这些连续段,191,134; 154,171; 简单说明下:SACK方式 通过告诉A(发送方)我收到
连续块的左边沿(EdgeOfBlock) 和 下一个连续块的右边沿,它两之间就是丢失的连续块。
这样A通过对比自己的发送块,就知道给B重传哪些包了。这种机制就叫SACK.
注: 实际中类似 “191,134”这样的序列号每个占4字节,一对是8字节,最多能有4组。
要启用SACK,Linux上可以使用:
echo 1 > /proc/sys/net/ipv4/tcp_sack
SACK对大流量的文件传输可能是否非常有利的,但对于小包就并不一定合适了,所以在TCP拥塞控制中,还提出了
一种解决方案叫TCP快速重传和TCP快速恢复
下面TCP快速重传和快速恢复,摘自: https://blog.csdn.net/jtracydy/article/details/52366461
快速重传:
快重传算法要求首先接收方收到一个失序的报文段后就立刻发出重复确认,而不要等待自己发送数据时才
进行捎带确认。接收方成功的接受了发送方发送来的M1、M2并且分别给发送了ACK,现在接收方没有收到M3,
而接收到了M4,显然接收方不能确认M4,因为M4是失序的报文段。如果根据可靠性传输原理接收方什么都不做,
但是按照快速重传算法,在收到M4、M5等报文段的时候,不断重复的向发送方发送M2的ACK,如果接收方一连收到
三个重复的ACK,那么发送方不必等待重传计时器到期,即RTO超时,由于发送方尽早重传未被确认的报文段。

快恢复:
当发送方连续接收到三个确认时,就执行乘法减小算法,把慢启动开始门限(ssthresh)减半,但是接下来并不
执行慢开始算法。
此时不执行慢启动算法,而是把cwnd设置为ssthresh的一半, 然后执行拥塞避免算法,使拥塞窗口缓慢增大。
其实这是应该的,因为你可以想象一下,网络本身就是不稳定,出现偶尔丢包也是正常,并且现在有3个报文都收到了,
只丢了一个说明当前网络负载并没有到达峰值,只是出现了中间路由器的RED(Random Early Detection ,随机提前检测,
或叫Random Early Drop(随机提前丢包) ),RED可简单理解为中间路由器发现当前网络有发送拥塞的趋势,因此为了
避免这种趋势持续恶化,它会随机根据每个连接流量所占用的带宽,来随机丢弃部分数据包;因此TCP拥塞控制会在
这个时候,不需要等待RTO超时,而是延时一会儿马上重传丢失的M3,接着会进入快速恢复阶段,即TCP的拥塞控制
阶段,每次只增加1个段。
另外,还需要说明 在真实网络中数据包不能顺序到达目标并非偶然,这是源于下面这种情况:
假如A给B发送了一个大包,此包在进入网线时,已经被拆分为4个小包,在网络传输的过程中,在经过路由器时,
M1,先到,路由器经M1解封装到IP层,查看源IP和目标IP,然后计算查询路由缓存,若没有查到,就查询路由表,找到后,
路由器会将该路由信息缓存在高速缓存中,因为网络数据包在传输时,具有集中性,即一个数据流到来后,其后往往都是
连续的数据流,因此路由器缓存后,就会马上将M1转发出去,接着对M2解包,发现是相同的流量,直接转发,但是此时
路由器突发发现自己的邻接关系出现问题了,我的对方路由器在hello心跳包超时前没有发过来,那么此时路由器将认为
我的邻居出故障了,于是只能从自己的邻接表中重新计算次优路由,当计算完成后,它会继续后续的报文转发,这时假如
对M3解包后,经过路由计算发现它应该走新的路由,因此就将它转发到新的路由路径上传输,M4也一样,假如M3和M4
到达下一跳前,又经过了做了多网口绑定的交换机,在经过多网口隧道时,这些数据包可能被负载均衡到不同的网口发出,
假如M3和M4分别被负载到两个接口上,由于不同网口上的缓存队列长度不同,就导致M3和M4可能不能同时到达对端,
所以可能出现M4先出来,M3出来的情况,在到达路由器时,M4就有可能排队在M3之前,转发到目标后,就有可能出现
M4先到,M3后倒地情况,所以TCP快速恢复和TCP快速重传并非一定是丢包,也可能是乱序,因此这些具体会在什么
情况用,我的理解也不深,但可以肯定,TCP/IP协议栈会自动处理这种情况。
接着说当A和B第一次建立连接时,两端都会使用自身系统的默认值来交换rwnd(Linux上是initrwnd),随后的通信过程
中每个ACK报文中都会携带该值,而随后携带的rwnd实际是cwnd的值,因为rwnd需要实时反映当前A和B之间的网络负载
状态,只有这样才能避免网络出现拥塞丢包后,双方都能感知到,并且调整自己发送数据包的大小和速度,其实这就是
TCP的滑动窗口机制,为何是双方?
因为当A是web服务器时,B请求数据,是A给B发更多数据。 但若B登录网站后,上传图片,视频时,就是B给A发送
更多数据了。所以通信双方的缓冲区大小和之间的网络状态就是瓶颈点,当双方接受缓冲区不足时,它们都会给对方发送
一个很小窗口大小的ACK报文,即rwnd值很小,接近于0,但不能是0 的报文,这样对方就知道我不能按照当前的速度
继续给对方发送数据了,我要等待对方应用层处理完缓冲区中的数据后,在给它发送数据,这时发送方就会延时发送数据。
为何rwnd不能为0?因为很多应用,特别是HTTP这种应用,当它要发送数据给对方时,有三种方式:
1. A给B发送一个文件,发送完,A就直接关闭连接,B发现和A的连接断了,就知道数据传输完了。
2. A告诉B,我给你传的文件有多大,你只要接收完这么大的数据,就算数据传输完成。
3. A无法告诉B,我给传的文件有多大,因为这个文件也许需要动态生成,也许需要压缩传输等待,在创建文件之前
A是无法知道文件的实际大小的,那怎么传文件?先在A上把文件生成,计算大小告诉B?这样可以,但也许在
今天的Web服务器上,是不可能实现了,因为面对成千上万的用户,一个用户生成一个文件1k,10万那?
1000万那?所以就有了分块传输,我告诉你,我要分块传输数据给你,当你收到一个分块大小为0的块时,
就说明数据传输完成了,你就可以组合所有分块,完成文件拼接了。而这种分块传输在当今互联网上是应用
相当普遍的,因此若窗口大小为0,就意味这个报文是空的,全0填充64字节,那么很可能会影响这些应用。
最后再来说ECN
参考摘录: https://www.cnblogs.com/edisongz/p/6986527.html
上面这篇博客,博主总结的很认真,不过太概要了,对初学者来说还很难看懂。
下面这部分是摘自上面博客的,为了让整片文章完成,所以非常感谢博主的贡献。
通过在TCP和IP首部的修改,能解决以下问题:
1,所有的TCP发送端尽快感知中间路径的拥塞,主动减小cwnd;
2,对于在中间路由器中超过平均队列长度的TCP报文进行ECN标记,并继续进行转发,不丢弃报文,
避免了报文丢弃和发送端重传;
3,由于显式的标识拥塞的发生,不用再等待RTO超时(时间比较长)再重发数据,提升了时延敏感应用的直观感受。
4,与非ECN网络环境相比,网络利用率更高,不再是在过载和轻载之间来回震荡。
【注意: 到今天也不是所以设备都支持ECN的!】
下图为IP报文结构:
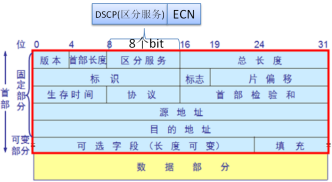
IP首部的TOS字段中的第7和8bit的res字段(保留字段)被重新定义为ECN字段,其中有四个取值,在RFC3168中描述,
00:代表该报文并不支持ECN,所以路由器的将该报文按照原始非ECN报文处理即可,即,过载丢包。
01和10:这两个值针对路由器来说是一样的,都表明该报文支持ECN功能,如果发生拥塞,则ECN字段的这两个
将修改为11来表示报文经过了拥塞,并继续被路由器转发。针对01和10的具体区别请参考RFC3168。
所以路由器转发侧要支持ECN,需要有以下新增功能:
• 1、 当拥塞发生时,针对ECN=00的报文,走原有普通非ECN流程,即,进行RED丢包。
• 2、 当拥塞发生时,针对ECN=01或ECN=10的报文,都需要修改为ECN=11,并继续转发流程。
• 3、 当拥塞发生时,针对ECN=11的报文,需要继续转发。
• 4、 为了保证与不支持ECN报文的公平性,在队列超过一定长度时,需要考虑对支持ECN报文的丢弃。
TCP报文就无需修改,只需要修改相应的拥塞避免标志位:
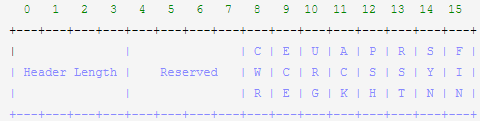
针对主机侧的修改,首部将bit8和bit9的res字段修改为CWR和ECE。在RFC3168中的设计如下:
• 1、 在TCP接收端收到IP头中的ECN=11标记,并在回复ACK时将ECE bit置1。并在后续的ACK中均将ECE bit置1。
• 2、 在TCP发送端收到ECE bit置1的ACK报文时,需要将自己的发送速率减半,并在发送下一个报文时,
将CWR bit置1。
• 3、 在接收端收到CWR bit置1的报文时,后续的ECE bit将不再置1。直到再次收到IP首部ECN=11时,
重复上述过程。
• 4、 TCP发送端在收到一个ECE=1时,缩小发送窗口,并且在本次RTT时间内将不再再次缩小发送窗口。
• 5、 TCP接收端向发送端回应ACK时,如果该ACK是一个不带数据的“纯”ACK,那么必须IP首部ECN=00,
因为TCP没有机制对纯ACK进行响应,就无法针对纯ACK发送拥塞通知。【不是很理解】
• 6、 对于支持IP ECN的主机,TCP层在发送报文时需要将IP首部中的ECN置为01或10。
附录:
1. 上文中提到RTO(重传超时),RTO实际是通过RTT计算出来的,而RTT是Client和Server之间一个来回所需的时间。
RTT(Round Trip Time):是A给B发送数据包后,A开始计时,当A收到B回应的ACK后,计时结束;这个时间
就是往返时间,而RTO(Retransmission Time Out)是重传超时时间,当A发出数据包多久后,依然没有
收到B回应的ACK,此时则认为数据包可能丢失了,于是对该数据包进行重传。
RTO是通过RTT计算出来的,它两都是不断动态变化的。
若想深入对RTT和RTO进行了解,这篇文章说明的非常详细:
https://blog.csdn.net/whgtheone/article/details/80970292
若你对计算机计时不了解,可参考下面的说明:
上文中提到滴答,实际是计算机计算时间流失的方式,这里就已Linux系统来说明:
在Linux中系统时钟是根据时钟频率(英文中称为”tick“,它译为”滴答“),来确定多少个tick为1秒,
而这个跨度称为”时间解析度“。当然解析度越高其精准度就越高。
在早期Linux内核内部也是存在时钟频率的,如:
100Hz(赫兹):即CPU晶振100Hz则认为过去了 1秒,用tick来表示就是滴答了100次,转化为毫秒,
则10毫秒就是一次tick。
1000Hz:若将晶振1000Hz认为是1毫秒,并且将1毫秒认为是一次tick,则其时间解析度就会更精确。
Linux系统在记录时间时,就是根据tick的次数来计时的,当tick了1000次(以CPU主频为1000Hz来说),
就认为过去了1秒,当然这说的是系统时钟,而非硬件时间。
目前的CPU都是2GHz等等,其计算方式不变,但其时间解析度更加精确了。
2. 关于TCP8个标志位的简单说明:
SYN: 同步标记位
ACK: 确认标记位(包括三次握手中的确认及之后数据传输时的确认)
RST: 重置标记位(访问一个未打开的TCP端口时,服务器返回一个带RST标记位的响应)
PSH: 推标记位 (实时性要求比较高的时候都会加上PSH,比较快的发送出去,不往缓存中放,ssh,telnet,
ftp-command,对方收到也一样)
【延时敏感,需要加PUSH标记; 传输数据,延时不敏感,不需要加PUSH标记
该标记位的出现原因,参见上文中Nagle算法,此算法是为解决网络资源浪费,它将小数据包缓存起来,等积累到
一定大小或一定时间后,集中发送给对方,以便提高网络吞吐量。这就导致一些实时性很高的应用产生
了很大网络延时,所有在必要时可用关闭它.】
URG: 紧急标志位(TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。紧急指针指向包内数据段的
某个字节不进入接收缓冲就直接交给上层进程,余下的数据要进入接收缓冲。通信的时候网络故障问题引
起的数据没传完,会发送一个URG标记位)
FIN: 结束标记位 ( 发送端完成发送任务,双方都需要确认没有数据再发给对方 )
ECE 和 CWR: 这两个标志位较新,它们是为网络拥塞控制提供的一种解决方式,当AB双方通信时,检测到网络拥塞(一般是通过
丢包率和RTT(数据包往返时间)来判断的),这时一方会在TCP连接中将ECE置位,当对方收到报文后发现ECE置位了,
它将降低数据包的发送速率,到拥塞解除其中一方将发送CWR置位的包,告诉对方可以提高发送速率了.
注:
Windows Vista支持ECN(拥塞显式反馈协议)但默认关闭, 所以此功能不一定所有操作系统都支持。
注:Windows启用方式: netsh interface tcp set global ecncapability=enabled 。Linux默认支持.
TCP协议深度刨析的更多相关文章
- RouteReuseStrategy angular路由复用策略详解,深度刨析路由复用策略
关于前端路由复用策略网上的文章很多,大多是讲如何实现tab标签切换历史数据,至于如何复用的原理讲的都比较朦胧,代码样例也很难适用各种各样的路由配置,比如懒加载模式下多级嵌套路由出口网上的大部分代码都会 ...
- cors跨越深度刨析
解决跨域的方式JSOP,和CORS JSONP不做介绍了. CORS跨域: 参考阮一峰http://www.ruanyifeng.com/blog/2016/04/cors.html 官方:https ...
- DNS使用的是TCP协议还是UDP协议简析
DNS使用的是TCP协议还是UDP协议简析 DNS同时占用UDP和TCP端口53是公认的,这种单个应用协议同时使用两种传输协议的情况在TCP/IP栈也算是个另类.但很少有人知道DNS分别在什么情况 ...
- TCP 协议简析
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的.可靠的.基于字节流的通信协议,数据在传输前要建立连接,传输完毕后还要断开连接.它是个超级麻烦的协议, ...
- 简析TCP的三次握手与四次分手(TCP协议头部的格式,数据从应用层发下来,会在每一层都会加上头部信息,进行封装,然后再发送到数据接收端)good
2014-10-30 分类:理论基础 / 网络开发 阅读(4127) 评论(29) TCP是什么? 具体的关于TCP是什么,我不打算详细的说了:当你看到这篇文章时,我想你也知道TCP的概念了,想要更 ...
- TCP协议的3次握手与4次挥手过程【深度详解】
一.前沿 尽管TCP和UDP都使用相同的网络层(IP),TCP却向应用层提供与UDP完全不同的服务.TCP提供一种面向连接的.可靠的字节流服务.面向连接意味着两个使用TCP的应用(通常是一个客户和一个 ...
- TCP 协议中MSS的理解
在介绍MSS之前我们必须要理解下面的几个重要的概念.MTU: Maxitum Transmission Unit 最大传输单元MSS: Maxitum Segment Size 最大分段大小PPPoE ...
- tcp协议中mss的理解
在介绍MSS之前我们必须要理解下面的几个重要的概念.<blockquote>MTU: Maxitum Transmission Unit 最大传输单元MSS: Maxitum Segmen ...
- 【TCP协议】(3)---TCP粘包黏包
[TCP协议](3)---TCP粘包黏包 有关TCP协议之前写过两篇博客: 1.[TCP协议](1)---TCP协议详解 2.[TCP协议](2)---TCP三次握手和四次挥手 一.TCP粘包.拆包图 ...
随机推荐
- MySQL远程访问时非常慢的解决方案
服务器放在局域网内进行测试时,数据库的访问速度还是很快.但当服务器放到外网后,数据库的访问速度就变得非常慢. 后来在网上发现解决方法,my.cnf里面添加 [mysqld] skip-name-res ...
- bzoj1601【Usaco2008 Oct】灌水
1601: [Usaco2008 Oct]灌水 Time Limit: 5 Sec Memory Limit: 162 MB Submit: 1589 Solved: 1035 [Submit][ ...
- 《从零開始学Swift》学习笔记(Day 61)——Core Foundation框架之内存管理
原创文章,欢迎转载. 转载请注明:关东升的博客 在Swift原生数据类型.Foundation框架数据类型和Core Foundation框架数据类型之间转换过程中,尽管是大部分是能够零开销桥接,零开 ...
- IOS------Warning
本文转载至 http://blog.csdn.net/shijiucdy/article/details/8755667 处理警告: 1,Validate Project Settings(updat ...
- MapReduce算法形式二:去重(HashSet)
案例二:去重(shuffle/HashSet等方法)shuffle主要针对的是key去重HashSet主要针对values去重
- gitlab merge过程
基本步骤如下: 以我的分支为例 1.创建本地分支,命令 git checkout -b liuping_develop2.创建好分支后提交到远程 ,命令 git push origin liuping ...
- CH 5402 选课(分组背包+树形DP)
CH 5402 选课 \(solution:\) 很有讨论套路的一道题,利用树的结构来表示出不同课程之间的包含关系(这里还要建一个虚点将森林变成一颗打大树).然后用子树这个概念巧妙的消除了因为这些包含 ...
- filename extension
题目描述 Please create a function to extract the filename extension from the given path,return the extra ...
- safair 的css hack
在css里面使用[;attribute:value;] css参考如下: .header-share li{float: right; margin-left: 20px; [;width: 50px ...
- HDU 5438 Ponds
Ponds Time Limit: 1500/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Sub ...