3、使用Lucene实现千度搜索
1、新建Web项目
新建一个Web项目,我命名为SearchEngine,然后导入Java包:
除了上篇博客中的Jar包外,我还引入了 IKAnalyzer2012_FF.jar 包和struts2的相关包:
IKAnalyzer:是用来进行中文分词的一个jar包,他会把中文分词一个个合理的词来进行检索;
Struts2:一会儿搜索结果,使用Struts2展示到浏览器中;
2.准备数据源
我使用linux 命令 wget 爬了一个网站内的一部分html网页,同样将它放在一个纯英文的目录:
3、创建索引
新建一个类CreateIndex:
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.filefilter.TrueFileFilter;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import com.HtmlBeanUtil;
import com.model.HtmlBean; public class CreateIndex {
public static final String DATA_DIR="E:/data/engine/www.bjsxt.com";
public static final String INDEX_DIR="E:/data/engine/index";
public void createIndex() throws IOException{
FSDirectory dir = FSDirectory.open(new File(INDEX_DIR));
// 使用中文分词的jar包进行分词
IKAnalyzer analyzer = new IKAnalyzer(true);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_9, analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter writer = new IndexWriter(dir, config);
File file = new File(DATA_DIR);
Collection<File> files = FileUtils.listFiles(file, TrueFileFilter.INSTANCE, TrueFileFilter.INSTANCE);
for(File f : files){
// 将原数据源内的内容通过抓取,返回一个实体类方便存储
HtmlBean hb = HtmlBeanUtil.parseHtml(f);
if(hb!=null && hb.getTitle()!=null && !hb.getTitle().trim().equals("")){
Document doc = new Document();
// 存储三个内容,标题,内容,url (实际上内容可能会更多比如关键字,描述等)
doc.add(new TextField("title",hb.getTitle(), Store.YES));
doc.add(new TextField("content",hb.getContent(), Store.YES));
doc.add(new TextField("url",hb.getUrl(), Store.YES));
writer.addDocument(doc);
}
}
writer.close();
}
}
实体HtmlBean和HtmlBeanUtil:
public class HtmlBean {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
import java.io.File;
import java.io.IOException;
import net.htmlparser.jericho.Element;
import net.htmlparser.jericho.HTMLElementName;
import net.htmlparser.jericho.Source;
import com.model.HtmlBean;
public class HtmlBeanUtil {
public static HtmlBean parseHtml(File file){
try {
Source source = new Source(file);
Element title = source.getFirstElement(HTMLElementName.TITLE);
String content = source.getTextExtractor().toString();
HtmlBean hb = new HtmlBean();
if(title==null || title.getTextExtractor() == null){
return null;
}
hb.setTitle(title.getTextExtractor().toString());
hb.setContent(content);
String path = file.getAbsolutePath();
String url = "http://"+path.substring(15);
url = url.replace("\\", "/");
hb.setUrl("http://"+path.substring(15));
return hb;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
使用单元测试跑一下创建索引的方法,最后会得到这么几个索引数据库文件:
4、创建检索类SearchIndex:
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer; import com.model.HtmlBean;
import com.model.Page; public class SearchIndex {
public Page search(String keyWord,int pageNum,int pageSize) throws IOException, ParseException, InvalidTokenOffsetsException{
Directory dir = FSDirectory.open(new File(CreateIndex.INDEX_DIR));
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
// 使用中文分词器把用户输入的内容进行分词
Analyzer analyzer = new IKAnalyzer(true);
QueryParser parser = new QueryParser(Version.LUCENE_4_9, "title", analyzer);
Query query = parser.parse(keyWord);
//format 用来制定要高亮显示的词的样式
SimpleHTMLFormatter format = new SimpleHTMLFormatter("<font color='red'>","</font>");
Highlighter high = new Highlighter(format ,new QueryScorer(query));
// pageNum*pageSize 控制显示的最大条数
TopScoreDocCollector results = TopScoreDocCollector.create(pageNum*pageSize, false);
searcher.search(query, results);
// 检索出来想要的结果的条数,可以实现分页
TopDocs topDocs = results.topDocs((pageNum-1)*pageSize, pageNum*pageSize);
Page page = new Page();
page.setPageNum(pageNum);
page.setPageSize(pageSize);
page.setTotalCount(topDocs.totalHits);
ScoreDoc[] docs = topDocs.scoreDocs;
List<HtmlBean> list = new ArrayList<HtmlBean>();
for(ScoreDoc scoreDoc : docs){
Document document = reader.document(scoreDoc.doc);
String title = document.get("title");
String content = document.get("content");
String url = document.get("url");
//获取到检索的结果以后,可以使用Highlighter获取高亮效果
title = high.getBestFragment(analyzer, "title", title);
content = high.getBestFragment(analyzer, "content", content);
HtmlBean hb = new HtmlBean();
hb.setTitle(title);
hb.setContent(content);
hb.setUrl(url);
list.add(hb);
}
// 计算记录的总页数
if(page.getTotalCount() <= pageSize){
page.setTotalPageCount(1);
}else{
if(page.getTotalCount() % pageNum == 0){
page.setTotalPageCount(page.getTotalCount() / pageSize);
}else{
page.setTotalPageCount(page.getTotalCount() / pageSize + 1);
}
}
page.setList(list);
return page;
}
}
同时我还用到了一个Page的实体,用来存放并返回查到的结果:
import java.util.List;
public class Page {
private long totalCount;
private int pageSize;
private int pageNum;
private long totalPageCount;
private List<HtmlBean> list;
public long getTotalCount() {
return totalCount;
}
public void setTotalCount(long totalCount) {
this.totalCount = totalCount;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getPageNum() {
return pageNum;
}
public void setPageNum(int pageNum) {
this.pageNum = pageNum;
}
public List<HtmlBean> getList() {
return list;
}
public void setList(List<HtmlBean> list) {
this.list = list;
}
public long getTotalPageCount() {
return totalPageCount;
}
public void setTotalPageCount(long totalPageCount) {
this.totalPageCount = totalPageCount;
}
}
5、页面呈现内容
页面呈现内容,由于过于简单就不描述太多了;
Struts.xml和web.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.1//EN" "http://struts.apache.org/dtds/struts-2.1.dtd">
<struts>
<constant name="struts.118n.encoding" value="UTF-8"></constant>
<constant name="struts.action.extension" value="do"></constant>
<package name="pages" namespace="/pages" extends="struts-default">
<action name="engine_*" class="com.actions.SearchEngineAction" method="{1}">
<result name="message">/WEB-INF/message.jsp</result>
<result name="index">/index.jsp</result>
</action>
</package>
</struts>
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" id="WebApp_ID" version="3.0">
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<display-name>SearchEngine</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
</web-app>
Action:
import java.io.File;
import java.io.IOException;
import javax.servlet.http.HttpServletRequest;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.struts2.ServletActionContext;
import com.lucene.CreateIndex;
import com.lucene.SearchIndex;
import com.model.Page; public class SearchEngineAction {
private int pageNum;
private String keyword;
public String create(){
HttpServletRequest request = ServletActionContext.getRequest();
try {
File file = new File(CreateIndex.INDEX_DIR);
if(file.exists()){
for(File f : file.listFiles()){
f.delete();
}
file.delete();
file.mkdirs();
}
CreateIndex createIndex = new CreateIndex();
createIndex.createIndex();
request.setAttribute("message", "创建索引完成...");
} catch (Exception e) {
e.printStackTrace();
request.setAttribute("message", e.getMessage());
}
return "message";
} public String search() throws IOException, ParseException, InvalidTokenOffsetsException{
HttpServletRequest request = ServletActionContext.getRequest();
int pageSize = 10;
if(pageNum < 1){
setPageNum(1);
}
if(keyword!=null && !keyword.trim().equals("")){
SearchIndex search = new SearchIndex();
Page page = search.search(keyword, pageNum, pageSize); request.setAttribute("page", page);
request.setAttribute("keyword", keyword);
}
return "index";
} public int getPageNum() {
return pageNum;
} public void setPageNum(int pageNum) {
this.pageNum = pageNum;
} public String getKeyword() {
return keyword;
} public void setKeyword(String keyword) {
this.keyword = keyword;
}
}
页面展示:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>千度一下,你就知道</title>
<style type="text/css">
body{padding-left: 132px;padding-right: 132px;}
#keyword{width: 521px; height: 20px; padding: 9px 7px;font: 16px arial; border: 1px solid #b8b8b8; border-bottom: 1px solid #ccc;
vertical-align: top; outline: none; box-shadow: none;}
.s_btn { width: 100px; height: 40px; color: white; border: solid 1px #3385ff; font-size:13pt; letter-spacing: 1px;background: #3385ff;
border-bottom: 1px solid #2d78f4;outline: medium; -webkit-appearance: none; -webkit-border-radius: 0;}
h4{ font-weight: normal;}
</style>
</head>
<body>
<form action="/SearchEngine/pages/engine_search.do" method="post">
<di>
<input name="keyword" id="keyword" type="text" maxlength="100" autocomplete="off" value="${keyword }" />
<input type="submit" class="s_btn" value="千度一下" />
</div>
<hr />
<c:if test="${page != null }" >
<div>千度为您找到相关结果约${page.totalCount}个</div>
<c:forEach items="${page.list }" var="record">
<h4><a href="${record.url }" target="_black">${record.title }</a></h4>
<p>${record.content }
<br />
<a href="${record.url }" target="_black">${record.url }</a>
</p> </c:forEach>
<div>
<c:forEach var="i" begin="1" end="${page.totalPageCount }" step="1">
<a> ${i} </a>
</c:forEach>
</div>
</c:if>
</form>
</body>
</html>
运行一下看一下效果:
没有搜索的时候:

我们搜索一个比较复杂的词:“尚学堂java官方网站中国媒体报道培训机构” 这些词都是完全合在一起的,看看中文分词器能否给分出来:
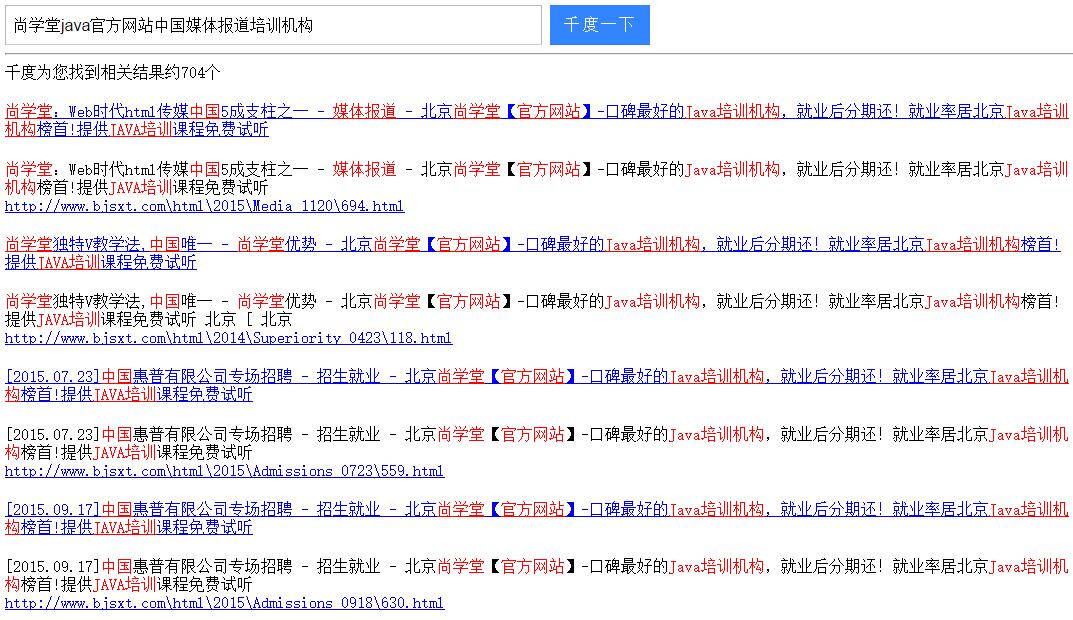

完全可以,把能够组合的词全显示出来了;
说明:在该DEMO中,我爬了尚学堂的网站,但这里没有要给他们打广告的意思哦!纯粹感觉好玩!
关键Lucene 根据权重检索,其中有一个算法是TF-IDF算法,详细可查看这篇文章:
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
小结:在该文中做了一个史上最简陋的搜索引擎,但Lucene的强大是显而已见的,搜索速度也非常快;该小Demo还有很多功能需要补全,比如分页,比如按权重搜索等等等等等...有感兴趣的伙伴可以试着补充全一下,让千度搜索比百度搜索更NB(在梦中YY);
3、使用Lucene实现千度搜索的更多相关文章
- Lucene5.5.4入门以及基于Lucene实现博客搜索功能
前言 一直以来个人博客的搜索功能很蹩脚,只是自己简单用数据库的like %keyword%来实现的,所以导致经常搜不到想要找的内容,而且高亮显示.摘要截取等也不好实现,所以决定采用Lucene改写博客 ...
- Lucene.net站内搜索—6、站内搜索第二版
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—5、搜索引擎第一版实现
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—4、搜索引擎第一版技术储备(简单介绍Log4Net、生产者消费者模式)
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—3、最简单搜索引擎代码
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—2、Lucene.Net简介和分词
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—1、SEO优化
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.Net 站内搜索
Lucene.Net 站内搜索 一 全文检索: like查询是全表扫描(为性能杀手)Lucene.Net搜索引擎,开源,而sql搜索引擎是收费的Lucene.Net只是一个全文检索开发包(只是帮我们 ...
- 【Lucene3.6.2入门系列】第03节_简述Lucene中常见的搜索功能
package com.jadyer.lucene; import java.io.File; import java.io.IOException; import java.text.SimpleD ...
随机推荐
- UVA 10152-ShellSort(映射+栈)
题意: 给出一堆乌龟名字,乌龟能从本身位置爬到顶端. 要求求出从原本的顺序到目标顺序的最小操作.输出每次操作移到顶端的乌龟的名字. 解析:名字用映射对应编号,把目标状态的乌龟从上到下的编号按1到N编好 ...
- LeeCode-Insertion Sort List
Sort a linked list using insertion sort. /** * Definition for singly-linked list. * struct ListNode ...
- 2.x ESL第二章习题 2.8
题目 代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 3 ...
- hdu2208之搜索
唉,可爱的小朋友 Time Limit: 10000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- linux下vi命令大全(转载)
进入vi的命令 vi filename :打开或新建文件,并将光标置于第一行首 vi +n filename :打开文件,并将光标置于第n行首 vi + filename :打开文件,并将光标置于最后 ...
- SqlServer 数据库日志无法收缩处理过程
今天按常用方法收缩一个测试用的数据库日志,发现没法收缩! dbcc sqlperf(logspace) USE [dbname] GO ALTER DATABASE [dbname] SET ...
- Oracle 取上周一到周末日期的查询语句
-- Oracle 取上周一到周末的sql -- 这样取的是 在一周内第几天,是以周日为开始的 select to_char(to_date('20130906','yyyymmdd'),'d') f ...
- Android应用程序窗口(Activity)的绘图表面(Surface)的创建过程分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/8303098 在前文中,我们分析了应用程序窗口连 ...
- struts2的<constant/>标签使用
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts PUBLIC "-/ ...
- apache启动问题: Could not reliably determine the server's fully qualified domain name
[root@rusky]# service httpd startStarting httpd: httpd: apr_sockaddr_info_get() failed for ruskyhttp ...