ROC曲线和PR曲线
转自:http://www.zhizhihu.com/html/y2012/4076.html
分类、检索中的评价指标很多,Precision、Recall、Accuracy、F1、ROC、PR Curve......
一、历史
wiki上说,ROC曲线最先在二战中分析雷达信号,用来检测敌军。诱因是珍珠港事件;由于比较有用,慢慢用到了心理学、医学中的一些检测等应用,慢慢用到了机器学习、数据挖掘等领域中来了,用来评判分类、检测结果的好坏。
百科:ROC曲线指受试者工作特征曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和 特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特 异性均较高的临界值。
二、原理
这里就拿最经典的二分类(0、1)问题讨论吧,分类器分类之后,往往会得到对每个样本是哪一类的一个估计,像是LR模型就会将这个估计规范化到 【0,1】,根据这个估计,你选择一个阈值p_0,就可以将分类结果映射到0,1了;分类效果好不好跟真实的label比比就行了。
所以你手里有decision和label两个向量,用来做分类结果的评估。

要看ROC的原理,总离不开上面这个表格,ROC绘制的就是在不同的阈值p_0下,TPR和FPR的点图。所以ROC曲线的点是由不同的p_0所造成的。所以你绘图的时候,就用不同的p_0采点就行。
Precision-Recall曲线,这个东西应该是来源于信息检索中对相关性的评价吧,precision就是你检索出来的结果中,相关的比 率;recall就是你检索出来的结果中,相关的结果占数据库中所有相关结果的比率;所以PR曲线要是绘制的话,也是对cutoff进行遍历,这样也得到 了不同的precision和recall的点。例如你选择了一个cutoff,从而根据cutoff判别分类的结果1或0。1就是检索返回的结果,0就 是没有返回的结果。
数据库里有500条记录,其中50个是相关的(正样本),你通过一个cutoff,返回了75个1,其中只有45个是真正相关的;
那么在这个cutoff对应下的recall=45/50=0.9,precision=45/75=0.6。坐标就是(0.9,0.6),在这里绘制一个点吧。
可以看出TPR和Recall的形式是一样的,就是查全率了,FPR就是保证这样的查全率你所要付出的代价,就是把多少负样本也分成了正的了。
三、AUC的计算
为了更好的衡量ROC所表达结果的好坏,Area Under Curve(AUC)被提了出来,简单来说就是曲线右下角部分占正方形格子的面积比例;那么计算这个东西其实就很简单了,根据reference的 paper,有很多很多计算方法,这里推荐一种近似采样的方法:采样。
你的分类器能够将正例排在负例前面的概率是多少,也就是采样中正例的decision>负例的decision的概率。
从stackoverflow上看到的代码,R语言:
auc <- mean(sample(pos.decision,1000,replace=T) > sample(neg.decision,1000,replace=T)) ## or aucs <- replicate(2000,mean(sample(pos.decision,1000,replace=T) > sample(neg.decision,1000,replace=T)))
auc2 <- round(mean(aucs),4)
其实这个可以等价于对于不规则图形的面积的采样估计了。
四、ROC中最优的p_0的计算
简单理解下的话,保证TPR同时代价FPR要尽量的小,是不是可以建立max(TPR+(1-FPR))的模型,然后选p_0呢?
paper中有更加详细的方法。谁给详细介绍下?


五、ROC和PR曲线之间的关系和不同
当正负样本差距不大的情况下,ROC和PR的趋势是差不多的,但是当负样本很多的时候,两者就截然不同了,ROC效果依然看似很好,但是PR上反映 效果一般。解释起来也简单,假设就1个正例,100个负例,那么基本上TPR可能一直维持在100左右,然后突然降到0.
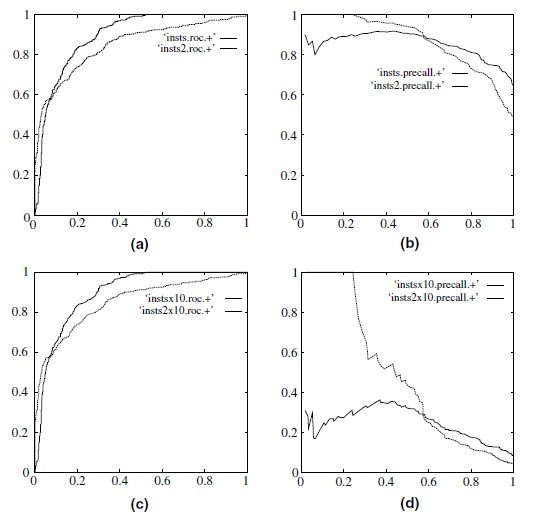
ROC and precision-recall curves under class skew. (a) ROC curves, 1:1; (b) precision-recall curves, 1:1; (c) ROC curves, 1:10 and (d) precisionrecall
六、具体例子和代码
(1)数据集
用的libsvm的那个270个样本的数据集,用LR模型做了一下:
0.688312721844616 1
0.461679176682519 0
0.405016268379421 1
0.693999977303342 0
0.391868684948981 0
0.526391961908057 0
0.570470938139219 1
0.708771207269333 1
0.700976655664182 1
0.713584109310541 1
0.545180177320974 0
0.646156295395112 0
0.347580513944893 0
0.391577777998607 1
....
(2)ROC曲线和PR曲线
R语言的ROCR绘制的图形:

代码:
library(ROCR)
a=read.table("toy.txt")
a <- as.matrix(a)
pred <- prediction(a[,1], a[,2])
perf <- performance(pred,"tpr","fpr")
auc.tmp <- performance(pred,"auc")
auc <- as.numeric(auc.tmp@y.values)
auc <- round(auc, 4)
plot(perf,colorize=TRUE,lwd=5,xlab="FPR",ylab="TPR", main=paste("AUC=",auc*100,"%"))
grid(5, 5, lwd = 1)
lines(par()$usr[1:2], par()$usr[3:4], lty=2, lwd=2, col="grey")
自己写代码绘制图像和估算AUC的值,AUC和ROCR包计算的还是很接近的:

a <- read.table("toy.txt")
a <- as.matrix(a)
label <- a[,2]
decision <- a[,1]
ngrids <- 100
TPR <- rep(0, ngrids)
FPR <- rep(0, ngrids)
p0 <- rep(0, ngrids)
for(i in 1:ngrids)
{
p0[i] <- i/ngrids
pred_label <- 1*(decision > p0[i])
TPR[i] <- sum(pred_label * label) / sum(label)
FPR[i] <- sum(pred_label * (1-label)) / sum(1-label)
}
## compute AUC
pos.decision <- decision[which(label == 1)]
neg.decision <- decision[which(label == 0)]
auc <- mean(sample(pos.decision,1000,replace=T) > sample(neg.decision,1000,replace=T))
## or
aucs <- replicate(2000,mean(sample(pos.decision,1000,replace=T) > sample(neg.decision,1000,replace=T)))
auc2 <- round(mean(aucs),4)
plot(FPR, TPR, col=4,lwd=5, type="l", main=paste("AUC=",auc2*100,"%"))
grid(5, 5, lwd = 1)
points(c(0,1), c(0,1), type="l", lty=2, lwd=2, col="grey")
##
cut.op <- p0[which(TPR-FPR == max(TPR-FPR))]
PR曲线:

</pre>
a <- read.table("toy.txt")
a <- as.matrix(a) label <- a[,2]
decision <- a[,1] ngrids <- 100 P <- rep(0, ngrids)
R <- rep(0, ngrids)
p0 <- rep(0, ngrids)
A <- rep(0, ngrids) for(i in 0:ngrids)
{
p0[i] <- i/ngrids
pred_label <- 1*(decision > p0[i])
R[i] <- sum(pred_label * label) / sum(label)
P[i] <- sum(pred_label * label) / sum(pred_label)
A[i] <- sum((pred_label == label)*1)/nrow(a)
} plot(R, P, col=4,lwd=5, type="l",xlab="Recall",ylab="Precision", main="PR Curve")
grid(5, 5, lwd = 1) accuracy <- max(A)
<pre>
七、Reference
[1]Tom Fawcett:An introduction to ROC analysis
[2]Jesse Davis,Mark Goadrich:The Relationship Between Precision-Recall and ROC Curves
[3]https://en.wikipedia.org/wiki/Receiver_operating_characteristic
[4]http://baike.baidu.com/view/42249.htm
补充:当正负类样本差数量距很大时,ROC的就不能很好的反应分类器的真实性能了,这时候PR将是更好的选择。
证明:当FP的数量有比较大的变化时,FP_rate= FP / N 因为N很大,所以FP_rate不会有很大变化。
但是PR=TP /TP +FP ,它可以捕获到这个差异,所以效果会更好。
ROC曲线和PR曲线的更多相关文章
- ROC曲线、PR曲线
在论文的结果分析中,ROC和PR曲线是经常用到的两个有力的展示图. 1.ROC曲线 ROC曲线(receiver operating characteristic)是一种对于灵敏度进行描述的功能图像. ...
- 精确率与召回率,RoC曲线与PR曲线
在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢? 首先,我们需要搞清楚几个拗口 ...
- ROC曲线 VS PR曲线
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- 【ROC曲线】关于ROC曲线、PR曲线对于不平衡样本的不敏感性分析说引发的思考
ROC曲线 在网上有很多地方都有说ROC曲线对于正负样本比例不敏感,即正负样本比例的变化不会改变ROC曲线.但是对于PR曲线就不一样了.PR曲线会随着正负样本比例的变化而变化.但是没有一个有十分具体和 ...
- ROC曲线和PR曲线绘制【转】
TPR=TP/P :真正率:判断对的正样本占所有正样本的比例. Precision=TP/(TP+FP) :判断对的正样本占判断出来的所有正样本的比例 FPR=FP/N :负正率:判断错的负样本占所 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- P-R曲线及与ROC曲线区别
一.P-R曲线 P-R曲线刻画查准率和查全率之间的关系,查准率指的是在所有预测为正例的数据中,真正例所占的比例,查全率是指预测为真正例的数据占所有正例数据的比例. 即:查准率P=TP/(TP + FP ...
- 查全率(Recall),查准率(Precision),灵敏性(Sensitivity),特异性(Specificity),F1,PR曲线,ROC,AUC的应用场景
之前介绍了这么多分类模型的性能评价指标(<分类模型的性能评价指标(Classification Model Performance Evaluation Metric)>),那么到底应该选 ...
- PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
作为机器学习重要的评价指标,标题中的三个内容,在下面读书笔记里面都有讲: http://www.cnblogs.com/charlesblc/p/6188562.html 但是讲的不细,不太懂.今天又 ...
随机推荐
- <item.../>元素可指定如下常用属性
android:id:为菜单项指定一个唯一表实.android:title:指定菜单项的标题.android:icon:指定菜单项的图标.android:alphabeticShortcut:为菜单项 ...
- Linux 安装字体
把XP下的字体C:\WINDOWS\FONTS\simsun.ttc(也就是宋体,大小为10M),把他重命名为 simsun.ttf 拷贝simsun.ttf 字体到 /usr/share/fonts ...
- 判断UserAgent是否为手机
, ))) { return true; } return false; }
- EF 5.0 帮助类 增删改查
原文地址:http://www.cnblogs.com/luomingui/p/3362813.html EF 5.0 帮助类 加入命名空间: using System; using System.D ...
- 《深度解析SDN》学习小结
SDN(软件定义网络),顾名思义,通过软件来控制或驱动整个网络.SDN的核心概念有两个,第一是转发面与控制面的分离:第二是开放的可编程接口.另外,SDN强调集中式控制,通过软件来控制整个网络,但这并不 ...
- 使用python进行接口测试(二)
之前使用过urllib和urllib2做接口测试,在做的途中,感觉使用urllib2直接进行的get,post 请求并没有那么好用.作为测试人员,所需要的测试工具应当以方便为第一要务,测试的耗时只要是 ...
- javaweb笔记2之HTTP协议
1 什么是http协议 是浏览器客户端 和 服务器端 数据传输的 格式规范: 2 查看http协议 (1)用火狐的firebug插件查看 (2)使用谷歌的Ghome查看(审查元素-> ...
- html中的banner自适应屏幕代码
<html> <head> <title>Title</title> <style> .bannerbox { width:100%; po ...
- android学习笔记---63-PopupWindow,泡泡窗口的实现
转载http://blog.csdn.net/lidew521/article/details/8976627 PopupWindow是一个可以显示在当前Activity之上的浮动容器,PopupWi ...
- POJ 2449 Remmarguts' Date (SPFA + A星算法) - from lanshui_Yang
题目大意:给你一个有向图,并给你三个数s.t 和 k ,让你求从点 s 到 点 t 的第 k 短的路径.如果第 k 短路不存在,则输出“-1” ,否则,输出第 k 短路的长度. 解题思路:这道题是一道 ...