Ubuntu14.04+caffe+cuda7.5 环境搭建以及MNIST数据集的训练与测试
Ubuntu14.04+caffe+cuda 环境搭建以及MNIST数据集的训练与测试
一、ubuntu14.04的安装:
ubuntu的安装是一件十分简单的事情,这里给出一个参考教程:
http://jingyan.baidu.com/article/76a7e409bea83efc3b6e1507.html
二、cuda的安装:
1、首先下载nvidia cuda的仓库安装包(我的是ubuntu 14.04 64位,所以下载的是ubuntu14.04的安装包,如果你是32位的可以参看具体的地址,具体的地址是https://developer.nvidia.com/cuda-downloads)
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/cuda-repo-ubuntu1404_6.5-14_amd64.deb
下载完成之后可以使用如下命令安装它,注意文件名修改为cuda-repo-ubuntu1404_6.5-14_amd64.deb:
sudo dpkg -i cuda-repo-<distro>_<version>_<architecture>.deb
2、安装好仓库之后,就可以更新你的本地仓库。
sudo apt-get update
最后开始安装cuda以及显卡驱动(安装cuda的同时就会把显卡驱动也全部安装好,这个真的很方便。但是下载的时间有点长。)
sudo apt-get install cuda
3、安装完之后你需要设置环境变量:
$ export PATH=/usr/local/cuda-6.5/bin:$PATH
$ export LD_LIBRARY_PATH=/usr/local/cuda-6.5/lib64:$LD_LIBRARY_PATH
4、设置完毕之后,你还可以选择是否安装cuda附带的示例代码(<dir>表示你要安装的位置,你可以将<dir>替换成~),并编译它:
$ cuda-install-samples-6.5.sh <dir>
cd ~/NVIDIA_CUDA-6.5_Samples
然后进入bin目录,并运行devicequery
cd ~/NVIDIA_CUDA-6.5_Samples/bin
./ deviceQuery
如果出现下列显卡信息, 则驱动及显卡安装成功:
./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "GeForce GTX 670"
CUDA Driver Version / Runtime Version 6.5 / 6.5
CUDA Capability Major/Minor version number: 3.0
Total amount of global memory: 4095 MBytes (4294246400 bytes)
( 7) Multiprocessors, (192) CUDA Cores/MP: 1344 CUDA Cores
GPU Clock rate: 1098 MHz (1.10 GHz)
Memory Clock rate: 3105 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) > deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Version = 6.5, NumDevs = 1, Device0 = GeForce GTX 670
Result = PASS
具体的安装过程可以参考英文。
http://docs.nvidia.com/cuda/cuda-getting-started-guide-for-linux/index.html
三、安装OpenCV:
这个尽量不要手动安装, Github上有人已经写好了完整的安装脚本:https://github.com/jayrambhia/Install-OpenCV下载该脚本,进入Install-OpenCV-master/Ubuntu/2.4 目录, 给所有shell脚本加上可执行权限
chmod +x *.sh
然后安装最新版本 (当前为2.4.9)
sudo ./opencv2_4_9.sh
脚本会自动安装依赖项,下载安装包,编译并安装OpenCV。整个过程大概半小时左右。
四、安装其他依赖项
sudo apt-get install build-essential libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
五、下载caffe,关于MKL:
1、下载caffe
http://download.csdn.net/download/jiangcunyeyu/8329829
下载后直接解压解压在你的工程路径内,无需安装。
2、关于MKL
MKL是intel的收费数学计算库,获取是一件十分蛋疼的事情,如果你有时间,自己百度教程安装.MKL不是必须的,OpenBLAS和atlas都可以替代之,并且这两个库的安装和使用十分简单。自己百度教程。
安装ATLAS
sudo apt-get install libatlas-base-dev
六、安装caffe所需的python相关包:
首先安装pip和python-dev (系统默认有python环境的, 不过我们需要的使python-dev)
sudo apt-get install python-dev python-pip
然后cd到caffe所在路径执行如下命令安装编译caffe python wrapper 所需要的额外包
for req in $(cat requirements.txt); do sudo pip install $req; done
七、编译caffe:
进入caffe根目录, 首先复制一份Makefile.config
cp Makefile.config.example Makefile.config
然后修改里面的内容,主要需要修改的参数包括
CPU_ONLY 是否只使用CPU模式,没有GPU没安装CUDA的同学可以打开这个选项BLAS (使用intel mkl还是OpenBLAS)DEBUG 是否使用debug模式,打开此选项则可以在eclipse或者NSight中debug程序
完成设置后, 开始编译
make all -j4
make test
make runtest
-j4注意 -j4 是指使用几个线程来同时编译, 可以加快速度, j后面的数字可以根据CPU core的个数来决定。
编译pycaffe:
make pycaffe
然后基本就全部安装完拉.
八、MNIST数据集训练以及测试:
1、训练:
在Caffe安装目录之下,首先获得MNIST数据集:
cd data/mnist
sh get_mnist.sh
生成mnist-train-lmdb/ 和 mnist-test-lmdb/,把数据转化成lmdb格式(注意这里要从caffe根目录运行,不然会报错,不懂自己读一读creat_mnist.sh):
sh examples/mnist/create_mnist.sh
训练网络(同上,从caffe根目录运行):
sh examples/mnist/train_lenet.sh
下图(盗图):
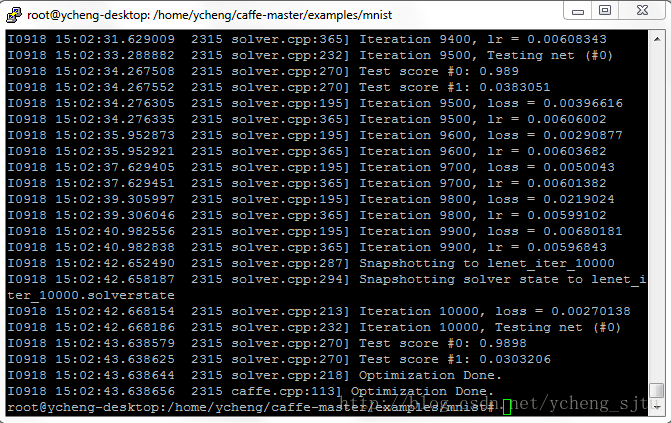
2、测试:
当所有数据都训练好之后,接下来就是如何将模型应用到实际数据了:
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel -gpu=0
如果没有GPU则使用
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel
test:表示对训练好的模型进行Testing,而不是training。其他参数包括train, time, device_query。-model=XXX:指定模型prototxt文件,这是一个文本文件,详细描述了网络结构和数据集信息。结果如下:
Ubuntu14.04+caffe+cuda7.5 环境搭建以及MNIST数据集的训练与测试的更多相关文章
- faster-rcnn(testing): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3+opencv3.0+matlabR2014a环境搭建记录
python版本的faster-rcnn见我的另一篇博客: py-faster-rcnn(running the demo): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3 ...
- py-faster-rcnn(running the demo): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3+python2.7环境搭建记录
第一次写博客,以此纪念这几天安装caffe,跑faster-rcnn的血泪史.在此特别感谢网络各路大神,来自全球各地,让我能从中汲取营养,吸取经验,总结规律. faster-rcnn分为matlab版 ...
- ubuntu14.04下嵌入式工作环境搭建
昨天作死一不小心把小红帽home目录下的东西删光了.跟着国嵌的视频学了这么久,对linux也算是有些熟悉,就决定自己在ubuntu下搭建一个工作环境.整个过程还算比较顺利,不过也有些小波折.下面把这次 ...
- ubuntu14.04.32 vmware11开发环境搭建
win7 64 vmware11 ubuntu14.04.32 在vmaware上安装ubuntu,自定义安装,选择区域为上海,这样数据源就会自动设置为中国,获取网络数据会较快,也可以安装完之后改变 ...
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- Ubuntu14.04 Server Apache2+subversion环境搭建
自从工作后,发现之前的代码开发太随便啦,于是经过不到两年的工作积累,打算在自己开发软件的过程中好好管理自己的项目.于是打算搭建自己的项目服务器,去年搭建过一次,但是由于没有记录,现在需要再来一遍,好多 ...
- ubuntu14.04 qt4 C++开发环境搭建
preFace:文章包括gnome,vnc-server,qt4安装配置及集成; apt-get update && apt-get upgrade; <一,组件软件包安装> ...
- Caffe+Ubuntu14.04+CUDA7.5 环境搭建(新人向)指南
序 本文针对想学习使用caffe框架的纯新手,如果文中有错误欢迎大家指出. 由于我在搭建这个环境的时候参考了许多网上的教程,但是没有截图,所以文中图片大多来源于网络. 本文没有安装matlab的步骤, ...
- unbuntu16.04上python开发环境搭建建议
unbuntu16.04上python开发环境搭建建议 2017-12-20 10:39:27 推荐列表: pycharm: 可以自行破解,但是不推荐,另外也不稳定 pydev+eclipse: ...
随机推荐
- Docker 如何把镜像上传到docker hub
1 首先你得准备一个hub 的帐号, 去 https://hub.docker.com 注册吧! 2 在hub那里新建一个仓库, 这个就类似于github那边的..create ---> cre ...
- System.in中的read()方法
大家先来看例如以下这个程序 public class TestInputStream { public static void main(String args[]) throws IOExcepti ...
- 剑指 offer set 14 打印 1 到 N 中 1 的个数
总结 1. 假设 n == 2212, 算法分为两个步骤. 第一步, 将这个 2212 个数分为 1~ 212, 213 ~ 2212 2. 第一部分实际上是将 n 的规模缩小到 212. 假如知道如 ...
- [UIImage _isCached]: message sent to deallocated instance
本文转载至 http://zhuhaibobb.blog.163.com/blog/static/2744006720124191633375/ 这几天做了个APP打开20份钟左右就强制退 ...
- IOS 7 自定义的UIAlertView不能在iOS7上正常显示
本文转载至 http://blog.csdn.net/hanbing861210/article/details/13614405 众所周知,当伟大的iOS7系统发布后,表扬的一堆.谩骂的也一片,而对 ...
- My97DatePicker设置,包括隐藏 清空,设置最大日期等 转载
My97DatePicker是一款非常灵活好用的日期控件.使用非常简单. 1.下载My97DatePicker组件包 2.在页面中引入该组件js文件: <script type=&quo ...
- 自动交互式脚本--expect
我们经常会遇到一些需要与服务器程序打交道的场景,比如,从登陆某个服务器,然后进行某项工作.这很平常,但是如果把这个工作自动化进行,你就需要一个程序能自动做你要告诉机器的事情,这样,我们的expect就 ...
- 【BZOJ2905】背单词 fail树+DFS序+线段树
[BZOJ2905]背单词 Description 给定一张包含N个单词的表,每个单词有个价值W.要求从中选出一个子序列使得其中的每个单词是后一个单词的子串,最大化子序列中W的和. Input 第一行 ...
- mysql如何用sql添加字段如何设置字符集和排序规则
alter table pay_company add sms_code2 varchar(16) CHARACTER SET UTF8 COLLATE utf8_general_ci DEFAULT ...
- 设置PYTHONIOENCODING
PYTHONIOENCODING=utf8