Redis数据结构:字典(hash表)
使用场景:
# set person name "tom"
# set person name "jerry"
1. 字典结构:
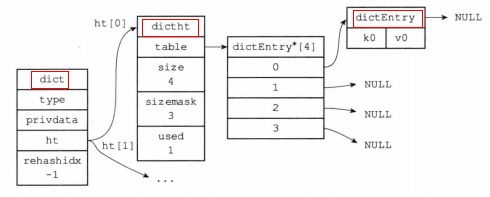
- 哈希表数据结构
- typedef struct dictht {
- //哈希表数组,存的是哈希值
- dictEntrry **table;
- //哈希表大小(table的大小)
- unsigned long size;
- //哈希表大小掩码,用于计算索引值,总是等于size-1
- unsigned long sizemask;
- //该哈希表已有节点的数量
- unsigned long used;
- } dictht;
- 哈希表节点数据结构
- typedef struct dictEntry {
- //键
- void *key;
- //值
- union {
//值可以是一个指针- void *val;
- //也可以是一个uint64_t整数
- uint64_tu64;
- //也可以是int64_t整数
- int64_ts64;
- } v;
- //指向下个哈希表节点,形成链表,用来使用拉链法解决哈希冲突
- struct dictEntry *next;
- } dictEntry;
- 字典数据结构
- typedef struct dict {
- //类型特定函数(保存了一些操作特定类型键值对函数)
- dictType *type;
- //私有数据(保存了传给特定函数的一些参数)
- void *privdata;
- //哈希表(一般使用ht[0]哈希表,ht[1]是在rehash时使用)
- dictht ht[];
- //rehash 索引(记录了rehash的进度,不rehash时,值为-1)
- int trehashidx;
- } dict;
2. 哈希算法:
当添加一个新键值时,会先根据键计算出哈希值和索引值,然后将新键值节点放到指定索引上(dictEntry*[index])。
计算哈希值:hash = dict -> type -> hashFunction(key);
计算索引值:index = hash & dict -> ht[x].sizemask;
3. 解决哈希冲突:
当键冲突时,使用next指针将新键连接起来。注意:为了速度考虑,程序会将新节点添加到链表的表头位置。
4. rehash:
随着数据的增多和减少,为了让哈希表的负载因子维持在一个合理的范围,需要对哈希表进行扩展和收缩。
负载因子:load_factor = ht[0].used / ht[0].size
rehash扩展触发条件:
1). 服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且负载因子大于等于1。
2). 服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且负载因子大于等于0.5。
rehash收缩触发条件:负载因子小于0.1。
步骤如下:
1). 在没有rehash时,字典只使用ht[0]。在rehash时,程序会对ht[1]分配空间。
扩展:ht[1]的大小为第一个大于等于ht[0].used * 2的2^n (2的n次方幂);
收缩:ht[1]的大小为第一个大于等于ht[0].used的2^n;
2). 将ht[0]的所有数据全部rehash到ht[1]上面,rehash指的是重新计算键的哈希值和索引值,然后放到ht[1]的指定位置上。
3). 当ht[0]上的数据全部迁移到ht[1]后,释放ht[0],将ht[1]置为ht[0],并在ht[1]上新建一个空的哈希表,为下一次rehash做准备。
5. 渐进式rehash(rehash的优化,触发条件由负载因子决定,如上)
当哈希表的键值对数量巨大时,一次rehash会非常耗时,为了避免对服务器性能造成影响,服务器采用分批次、渐进式的将ht[0]里面的键值对慢慢的rehash到ht[1]。
步骤:
1)为ht[1]分配空间,字典同时持有ht[0]和ht[1]。
2)字典中设置一个计数器rehashidx,当值为0时,表示rehash开始。
3)在rehash期间,每次增删改查时,程序还会顺带将ht[0]在rehashidx索引上的所有键值对rehash到ht[1],当rehash完成后,rehashidx增一。(这里是将table上对应的某条索引值指向的数据节点链表迁移到ht[1]中,th[0].table[rehashidx]数据就空了)
4)随着操作的不断执行,ht[0]上的所有键值对都会被rehash到ht[1]上,这时rehashidx为-1,表示rehash完成。
注意:
1)在rehash执行期间,新数据会保存到ht[1]里面,而ht[0]不进行添加操作,这样,ht[0]里的数据会逐渐迁移到ht[1],直到ht[0]清空。
2)在rehash执行期间,查找某个键时,会先从ht[0]中查找,如果没找到就去ht[1]里面查找。
Redis数据结构:字典(hash表)的更多相关文章
- 【数据结构】Hash表
[数据结构]Hash表 Hash表也叫散列表,是一种线性数据结构.在一般情况下,可以用o(1)的时间复杂度进行数据的增删改查.在Java开发语言中,HashMap的底层就是一个散列表. 1. 什么是H ...
- 深入理解Redis 数据结构—字典
字典,又称为符号表.关联数组或映射,是一种用于保存键值对的抽象数据结构.在字典中,一个键可以和一个值进行关联,这些关联的键和值称为键值对.键值对中键是唯一的,我们可以根据键key通过映射查找或者更新对 ...
- java数据结构之hash表
转自:http://www.cnblogs.com/dolphin0520/archive/2012/09/28/2700000.html Hash表也称散列表,也有直接译作哈希表,Hash表是一种特 ...
- 【数据结构】Hash表简介及leetcode两数之和python实现
文章目录 Hash表简介 基本思想 建立步骤 问题 Hash表实现 Hash函数构造 冲突处理方法 leetcode两数之和python实现 题目描述 基于Hash思想的实现 Hash表简介 基本思想 ...
- Redis数据结构之跳跃表-skiplist
在Redis中,zset是一个复合结构: 使用hash来存储value和score的映射关系 使用跳跃表来提供按照score进行排序的功能,同时可以指定score范围来获取value列表 结构 zse ...
- 数据结构之hash表
哈希表是种数据结构,它可以提供快速的插入操作和查找操作.hash定义了一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法.由于通过更短的哈希值比用原始值 ...
- Redis数据结构之跳跃表
跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的. 一.跳跃表结构定义1. 跳跃表节点结构定义: 2. 跳跃表结构定义: 示例: 二.跳跃表节点中各种 ...
- Redis数据结构:跳跃表
1. 跳跃表是有序集合(zset)的底层实现之一: 2. 由zskiplist和zskiplistNode组成: 3. 每个跳跃表节点的层数都是1-32之间的随机数(每创建一个节点的时候,程序会随机生 ...
- 如何使用RedisTemplate访问Redis数据结构之Hash
Redis的Hash数据机构 Redis的散列可以让用户将多个键值对存储到一个Redis键里面. public interface HashOperations<H,HK,HV> Hash ...
- Redis数据类型之Hash(二)
前言: Redis hash是一个String类型的field和value的映射表.添加.删除操作复杂度平均为O(1),为什么是平均呢?因为Hash的内部结构包含zipmap和hash两种.hash特 ...
随机推荐
- spring cloud 转
http://blog.csdn.net/forezp/article/details/70148833 服务的注册与发现(Eureka) 服务注册(consul) 服务消费者(rest+ribbon ...
- POSIX 进程间通信 (可移植操作系统接口)
1.什么是POSIX标准 Portable Operating System Interface for Computing System. 他是一个针对操作系统(准确地说是针对类Unix操作系统)的 ...
- servlet的总结
tomcat在启动的时候 加载webapp下面的web.xml,加载里面定义的servlet. web.xml文件有两部分:servlet类定义和servlet映射定义每个被载入的servlet类都有 ...
- asp.net操作GridView添删改查的两种方法 及 光棒效果
这部份小内容很想写下来了,因为是基础中的基础,但是近来用的比较少,又温习了一篇,发现有点陌生了,所以,还是写一下吧. 方法一:使用Gridview本身自带的事件处理,代码如下(注意:每次操作完都得重新 ...
- 20145310 《Java程序设计》第9周学习总结
20145310 <Java程序设计>第9周学习总结 教材学习内容总结 本周主要进行第十六章和第十七章的学习. JDBC全名Java DataBase Connectivity,是java ...
- 轻谈Normalize.css
Normalize.css 是 * ? Normalize.css只是一个很小的CSS文件,但它在默认的HTML元素样式上提供了跨浏览器的高度一致性.相比于传统的CSS reset , Normali ...
- 可扩展多线程异步Socket服务器框架EMTASS 2.0 (转自:http://blog.csdn.net/hulihui)
可扩展多线程异步Socket服务器框架EMTASS 2.0 (转自:http://blog.csdn.net/hulihui) 0 前言 >>[前言].[第1节].[第2节].[第3节]. ...
- .NET数据库编程求索之路--1.引子
转载:[ 夏春涛 email: xchuntao@163.com blog: http://www.cnblogs.com/SummerRain ] 长期做.NET MIS系统开发,打交到最多还是数 ...
- 【前端】vue.js实现按钮的动态绑定
vue.js实现按钮的动态绑定 实现效果: 实现代码以及注释: <!DOCTYPE html> <html> <head> <title>按钮绑定< ...
- JavaConfig 使用Java代码进行显示配置
从Spring 3起,JavaConfig功能已经包含在Spring核心模块,它允许开发者将bean定义和在Spring配置XML文件到Java类中. 需要先加载spring-context 包 &l ...