求 LCA 的三种方法
(YYL: LCA 有三种求法, 你们都知道么?)
(众神犇: 这哪里来的傻叉...)
1. 树上倍增
对于求 LCA, 最朴素的方法是"让两个点一起往上爬, 直到相遇", "如果一开始不在同一深度, 先爬到同一深度". 树上倍增求 LCA 的方法同样基于这个道理, 只不过利用了倍增思想从而加速了"向上爬"的操作. 也就是说, 每次向上爬的高度不是 1, 而是 2 的幂.
我们用 $f(i, j)$ 表示从节点 $i$ 向上爬 $2^j$ 的高度所到达的节点, 则 $f(i, 0)$ 就代表节点 $i$ 的父节点. 那么对于任意的 $f(i, j), j > 0$, 有
$f(i, j) = f(f(i, j-1), j-1)$.
当我们要求两点的 LCA 时, 先让它们到同一高度. 这个过程我们使用二进制拆分来加速. 比如当两点高度相差 $5$ 时, $(5)_{10} = (101)_2$, 那么我们就让高度较小的那个节点先往上爬 $2^2 = 4$ 步, 再往上 $2^0 = 1$ 步. 此时两点即在同一高度.
如果爬到同一高度后两点相同, 显然这个点就是它们的 LCA, 直接返回即可.
如果两点不同, 就一起往上爬. 这是一个无限逼近的过程, 直到找到它们的 LCA 的子节点为止. 详见代码.
for (int i = ; i <= n; ++i)
lg[i] = lg[i - ] + ( << lg[i - ] + == i); int lca(int x, int y) {
if (dep[x] < dep[y])
swap(x, y);
while (dep[x] > dep[y])
x = f[x][lg[dep[x] - dep[y]]];
if (x == y)
return x;
for (int k = lg[dep[x]]; k >= ; --k)
if (f[x][k] != f[y][k])
x = f[x][k], y = f[y][k];
return f[x][];
}
(上面的代码预先算出了 $log_2 (n)$ 的值, 从而简化了代码.)
2. Tarjan 算法
Tarjan 算法建立在 DFS 的基础上.
假如我们正在遍历节点 x, 那么根据所有节点各自与 x 的 LCA 是谁, 我们可以将节点进行分类: x 与 x 的兄弟节点的 LCA 是 x 的父亲, x 与 x 的父亲的兄弟节点的 LCA 是 x 的父亲的父亲, x 与 x 的父亲的父亲的兄弟节点的 LCA 是 x 的父亲的父亲的父亲... 将这些类别各自归入不同的集合中, 如果我们能够维护好这些集合, 就能够很轻松地处理有关 x 节点的 LCA 的询问. 显然我们可以使用并查集来维护.
Tarjan 算法的大致步骤如下:
1. 遍历 x 节点的子节点. 对于 x 节点的每个子节点, 该子节点遍历结束之后, 将其整棵子树合并到 x, 并保证合并之后祖先为 x;
2. 将 x 标记为已遍历;
3. 处理有关 x 的询问. 对于询问 (x, y), 如果 y 节点已遍历, 则 x 与 y 的 LCA 就是 y 节点所在集合的祖先; 否则, 将其推迟到遍历 y 时再处理.
代码如下:
void tarjan(int u) {
fa[u] = u;
int i, v;
for (i = ; i < tree[u].size(); i++) {
v = tree[u][i];
tarjan(v);
fa[findset(v)] = u;
}
vis[u] = true;
for (i = ; i < query[u].size(); i++) {
if (vis[query[u][i]]) {
cnt[findset(query[u][i])]++;
}
}
}
(对于保证合并之后集合祖先为 x 这一步骤, 网络上的代码大多使用了一个 ancestor 数组来记录集合的祖先是谁. 原因是如果使用并查集的带秩合并, 合并两个集合之后不好确定根节点到底是谁. 但是带秩合并在有路径压缩的情况下作用有限, 所以这里取消了带秩合并而直接使用 fa[findset(v)] = u 来保证集合的祖先为 u.)
3. LCA 转 RMQ
树上的一些问题可以转化为对树的 DFS 序列的操作. 比如对于这样一棵树:
(图片来自 http://scturtle.is-programmer.com/posts/30055.html)
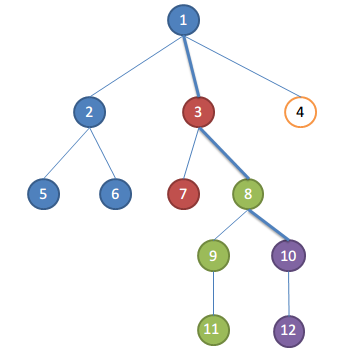
对于以 3 这个节点为根的整棵子树, 其 DFS 序列为: 3 7 3 8 9 11 9 8 10 12 10 8 3.
假如我们要询问 7 和 12 的 LCA, 我们找到 7 和 12 分别第一次出现的位置, 然后在这一个区间内找到深度最小的那个节点, 也就是节点 3, 显然它就是 7 和 12 的 LCA.
记 DFS 序列为 $S[1...2n]$, 节点 $x$ 在序列 $S$ 中第一次出现的位置为 $E[x]$, 用 $RMQ(L, R)$ 表示序列 $S$ 中深度最小的那个节点. 则
$LCA(u, v) = RMQ(E[u], E[v])$
代码略. DFS + RMQ 的普通做法即可(ST, 线段树等等).
求 LCA 的三种方法的更多相关文章
- 清空StringBuilder的三种方法及效率
清空StringBuilder的三种方法及效率 大家知道对于字符串频繁拼接是使用stringbuilder.Append方法比使用string+=方法效率高很多,但有时需要清空stringbuilde ...
- mysql分表的三种方法
先说一下为什么要分表当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.根据个人经验,mysql执行一 ...
- java 获取随机数的三种方法
方法1(数据类型)(最小值+Math.random()*(最大值-最小值+1))例:(int)(1+Math.random()*(10-1+1))从1到10的int型随数 方法2获得随机数for (i ...
- 三种方法实现PCA算法(Python)
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目 ...
- 使用三种方法求解前N个正整数的排列
本篇博文给大家介绍前N个正整数的排列求解的三种方式.第一种是暴力求解法:第二种则另外声明了一个长度为N的数组,并且将已经排列过的数字保存其中:第三种方式则采用了另外一种思路,即首先获取N个整数的升序排 ...
- 三种方法实现Hadoop(MapReduce)全局排序(1)
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序.但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序.基于此,本文提供三 ...
- 数组k平移三种方法(java)
上代码,本文用了三种方法实现,时间复杂度不一样,空间复杂度都是o(1): public class ArrayKMove { /** * 问题:数组的向左k平移,k小于数组长度 * @param ar ...
- 服务器文档下载zip格式 SQL Server SQL分页查询 C#过滤html标签 EF 延时加载与死锁 在JS方法中返回多个值的三种方法(转载) IEnumerable,ICollection,IList接口问题 不吹不擂,你想要的Python面试都在这里了【315+道题】 基于mvc三层架构和ajax技术实现最简单的文件上传 事件管理
服务器文档下载zip格式 刚好这次项目中遇到了这个东西,就来弄一下,挺简单的,但是前台调用的时候弄错了,浪费了大半天的时间,本人也是菜鸟一枚.开始吧.(MVC的) @using Rattan.Co ...
- Python使用三种方法实现PCA算法[转]
主成分分析(PCA) vs 多元判别式分析(MDA) PCA和MDA都是线性变换的方法,二者关系密切.在PCA中,我们寻找数据集中最大化方差的成分,在MDA中,我们对类间最大散布的方向更感兴趣. 一句 ...
随机推荐
- java classloader原理深究
前面已经写过一篇关于java classloader的拙文java classloader原理初探. 时隔几年,再看一遍,觉得有些地方显得太过苍白,于是再来一篇: 完成一个Java类之后,经过java ...
- 简单易用的分页类实例代码PHP
<?php /*********************************************** * @类名: page * @参数: $myde_total - 总记录数 * $m ...
- HttpGet/HttpPost请求方法
/// <summary> /// HttpGet请求 /// </summary> /// <param name="url">HttpGet ...
- linux文件的一些特殊权限
一些特殊权限 虽然我们通常看到一个八进制的权限掩码用三位数字来表示,但是从技术层面 上来讲,用四位数字来表示它更确切些. 为什么呢?因为,除了读取,写入,和执 行权限之外,还有其它的,较少用到的权限设 ...
- 修饰器Decorator
类的修饰 许多面向对象的语言都有修饰器(Decorator)函数,用来修改类的行为.目前,有一个提案将这项功能,引入了 ECMAScript. @testable class MyTestableCl ...
- ACM ICPC Central Europe Regional Contest 2013 Jagiellonian University Kraków
ACM ICPC Central Europe Regional Contest 2013 Jagiellonian University Kraków Problem A: Rubik’s Rect ...
- meta标签中的http-equiv属性使用介绍
meta是html语言head区的一个辅助性标签.也许你认为这些代码可有可无.其实如果你能够用好meta标签,会给你带来意想不到的效果,meta 标签的作用有:搜索引擎优化(SEO),定义页面使用 ...
- spring mvc:视图解析器
ModelAndView对象中的view对象,可以使用字符串来让Spring框架进行解析获得适合的视图.而解析View的就是ViewResolver技术. ViewResolver的定义如下: pub ...
- 关于.net4.0中的Action委托
在使用委托时,若封装的方法无返回值,并且参数在0-7个,可考虑使用.Net4.0中的Action委托,建议使用系统自带的,减少自定义 public delegate void Action<in ...
- underscore || lodash
1.http://www.css88.com/archives/5443 (underscore) let list = _.filter(record.orderGoodsList, item =& ...