CRNN中英文字符识别
参考GitHub源码:https://github.com/YoungMiao/crnn
应demo大师文章要求,我再补充下,推荐下,这个平台挺好
1.环境搭建
1.1 基础环境
- Ubuntu14.04 + CUDA
- opencv2.4 + pytorch + lmdb +wrap_ctc
安装lmdb apt-get install lmdb
1.2 安装pytorch
pip,linux,cuda8.0,python2.7:pip install http://download.pytorch.org/whl/cu80/torch-0.1.12.post2-cp27-none-linux_x86_64.whl
参考:http://pytorch.org/
1.3 安装wrap_ctc
git clone https://github.com/baidu-research/warp-ctc.git`
cd warp-ctc
mkdir build; cd build
cmake ..
make
GPU版在环境变量中添加
export CUDA_HOME="/usr/local/cuda"
cd pytorch_binding
python setup.py install
参考:https://github.com/SeanNaren/warp-ctc/tree/pytorch_bindings/pytorch_binding
1.4 注意问题
- 缺少cffi库文件 使用
pip install cffi安装 - 安装pytorch_binding前,确认设置CUDA_HOME,虽然编译安装不会报错,但是在调用gpu时,会出现wrap_ctc没有gpu属性的错误
2. crnn预测(以21类中英文为例)
模型地址:链接:https://eyun.baidu.com/s/3dEUJJg9 密码:vKeD
运行/contrib/crnn/demo.py
原始图片为:

识别结果为: 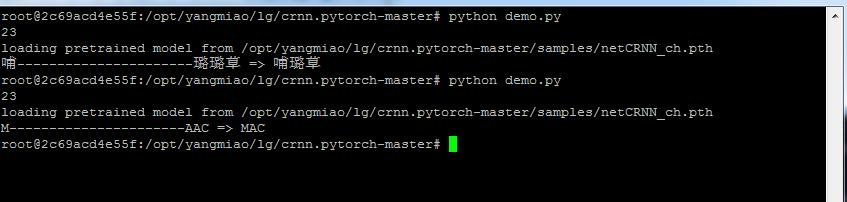
# 加载模型
model_path = './samples/netCRNN_9_112580.pth'
# 需识别的图片
img_path = './data/demo.png'
# 识别的类别
alphabet = 'ACIMRey万下依口哺摄次状璐癌草血运重'
# 设置模型参数 图片高度imgH=32, nc, 分类数目nclass=len(alphabet)+1 一个预留位, LSTM设置隐藏层数nh=128, 使用GPU个数ngpu=1
model = crnn.CRNN(32, 1, 22, 128, 1).cuda()
替换模型时,注意模型分类的类别数目
3、程序实现(crnn 训练(以21类中英文为例))
注意:--------------------------------------
请补充完整个实现过程,以下实现,没有说到具体的实现过程,应该把具体的代码说清楚,思路说清楚。数据怎样清洗的,怎样建模的等等
1. 数据预处理
运行/contrib/crnn/tool/tolmdb.py
# 生成的lmdb输出路径
outputPath = "./train_lmdb"
# 图片及对应的label
imgdata = open("./train.txt")
2. 训练模型
运行/contrib/crnn/crnn_main.py
python crnn_main.py [--param val]
--trainroot 训练集路径
--valroot 验证集路径
--workers CPU工作核数, default=2
--batchSize 设置batchSize大小, default=64
--imgH 图片高度, default=32
--nh LSTM隐藏层数, default=256
--niter 训练回合数, default=25
--lr 学习率, default=0.01
--beta1
--cuda 使用GPU, action='store_true'
--ngpu 使用GPU的个数, default=1
--crnn 选择预训练模型
--alphabet 设置分类
--Diters
--experiment 模型保存目录
--displayInterval 设置多少次迭代显示一次, default=500
--n_test_disp 每次验证显示的个数, default=10
--valInterval 设置多少次迭代验证一次, default=500
--saveInterval 设置多少次迭代保存一次模型, default=500
--adam 使用adma优化器, action='store_true'
--adadelta 使用adadelta优化器, action='store_true'
--keep_ratio 设置图片保持横纵比缩放, action='store_true'
--random_sample 是否使用随机采样器对数据集进行采样, action='store_true'
示例:python /contrib/crnn/crnn_main.py --tainroot [训练集路径] --valroot [验证集路径] --nh 128 --cuda --crnn [预训练模型路径]
修改/contrib/crnn/keys.py中alphabet = 'ACIMRey万下依口哺摄次状璐癌草血运重'增加或者减少类别
- 注意事项
训练和预测采用的类别数和LSTM隐藏层数需保持一致
4、项目结构
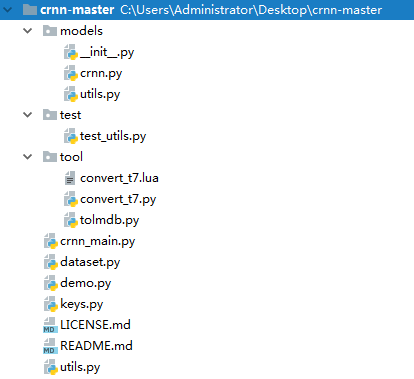
从上往下大概说明下
1.crnn.py是crnn网络结构模块
#双向的LSTM
class BidirectionalLSTM(nn.Module)
#CRNN网络
class CRNN(nn.Module)
crnn网络设计:
CRNN由CNN+BiLSTM+CTC构成:
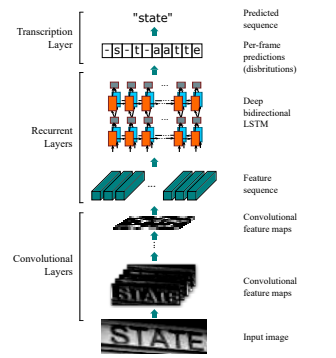
网络结构:
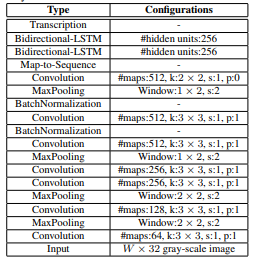
input: 输入文字块,归一化到
32*w即height缩放到32,宽度按高度的比率缩放,也可以缩放到自己想要的宽度,训练时为批次训练,缩放到[32,Wmax]),示例为(32,128)经过两个conv层和两个poling层,conv3层时数据大小为256*8*32,两个pooling层步长为2
pooling2层步长为(2,1),(个人看法:作者使用的英文训练,英文字符的特征是高大于宽的特征,倘若使用中文训练,建议使用(2,2),我的代码中默认为(2,2),示例以(2,1)为例,所以此时输出为256*4*33
bn层不改变输出的大小(就是做个归一化,加速训练收敛),p3层时,w+1,所以pooling3层时,输出为512*2*34
conv7层时,kernel 为22,stride(1,1) padding(0,0)
Wnew = (2 + 2 * padW - kernel ) / strideW + 1 = 1
Hnew = 33
所以conv7层输出为5121*33后面跟两个双向Lstm,隐藏节点都是256
Blstm1输出33*1256
Blstm2输出 33*1*5530 5530 = 字符个数 + 非字符 = 5529 + 1
最终的输出结果直观上可以想象成将128分为33份,每一份对应5530个类别的概率
2.tolmdb.py生成训练lmdb数据模块
- 输入图片list的文档,大概格式如下
3.crnn_main.py主程序模块
- 增加了对类别增删的增量训练,line104~line117
4.dataset.py数据加载模块 - class alignCollate:按照比例缩放w
- class randomSequentialSampler:随机采样batch
5.utils.py编解码模块
5、数据部分
数据获取方法有两种:
- 生成自然场景文本
GitHub:https://github.com/ankush-me/SynthText - 生成常规文本:
GitHub:https://github.com/YoungMiao/synthdata-zh
有时间在记录两种方法
CRNN中英文字符识别
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
CRNN中英文字符识别的更多相关文章
- gameUnity 网络游戏框架
常常在想,有没有好的方式,让开发变得简单,让团队合作更加容易. 于是,某一天 动手写一个 架构, 目前版本 暂定 0.1 版本.(unity5.0.0f4 版本以上) 我打算 开源出来 0.1有什么功 ...
- 【OCR技术系列之七】端到端不定长文字识别CRNN算法详解
在以前的OCR任务中,识别过程分为两步:单字切割和分类任务.我们一般都会讲一连串文字的文本文件先利用投影法切割出单个字体,在送入CNN里进行文字分类.但是此法已经有点过时了,现在更流行的是基于深度学习 ...
- 使用Python基于VGG/CTPN/CRNN的自然场景文字方向检测/区域检测/不定长OCR识别
GitHub:https://github.com/pengcao/chinese_ocr https://github.com/xiaofengShi/CHINESE-OCR |-angle 基于V ...
- 字符识别OCR原理及应用实现
字符识别OCR原理及应用实现 文本是人类最重要的信息来源之一,自然场景中充满了形形色色的文字符号.光学字符识别(OCR)相信大家都不陌生,就是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过 ...
- Tesseract-OCR字符识别简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程.Tesseract:开源的OCR识别引擎,初期Tesseract引擎 ...
- ThinkPHP+Smarty模板中截取包含中英文混合的字符串乱码的解决方案
好几天没写博客了,其实有好多需要总结的,因为最近一直在忙着做项目,但是困惑了几天的Smarty模板中截取包含中英文混合的字符串乱码的问题,终于解决了,所以记录下来,需要的朋友看一下: 出现乱码的原因: ...
- [修正] Firemonkey 中英文混排折行问题(移动平台)
问题:FMX 在移动平台的文字显示并非由该平台的原生 API 来显示,而是由 FMX.TextLayout.GPU 来处理,也许是官方没留意到中文字符的问题,造成在中英文混排折行时,有些问题. 适用: ...
- [连载]《C#通讯(串口和网络)框架的设计与实现》- 13.中英文版本切换设计
目 录 第十三章 中英文版本切换设计... 2 13.1 不用自带的资源文件的理由... 2 13.2 配置文件... 2 13.3 语言 ...
- Excel—分离中英文字符
1.如下图: 2.提取中文字符为: 3.提取应为字符为: 4.说明: 该方法的原理利用了LENB和LEN计算方法的不同,LEN计算字符数,中英文都算作一个字符:LENB计算字节数,中文算两个字节,英文 ...
随机推荐
- JavaScript设计模式与开发实践——读书笔记1.高阶函数(下)
上部分主要介绍高阶函数的常见形式,本部分将着重介绍高阶函数的高级应用. 1.currying currying指的是函数柯里化,又称部分求值.一个currying的函数会先接受一些参数,但不立即求值, ...
- 通过wifi上网,桥接模式下virtualBox虚拟机无法连上网的解决办法
https://jingyan.baidu.com/article/948f59242e601dd80ff5f929.html
- PHP -- 简单表单提交
网上看博文,一步步入门~~ 简单表单,简单提交 @_@!! <?php //php代码部分开始 echo "<html>"; echo "<hea ...
- Codeforces Beta Round #9 (Div. 2 Only) C. Hexadecimal's Numbers dfs
C. Hexadecimal's Numbers 题目连接: http://www.codeforces.com/contest/9/problem/C Description One beautif ...
- hihocoder1310 岛屿
hihocoder1310 岛屿 题意: 中文题意 思路: dfs,面积和数量都很好求,问题在岛屿形状上,感觉让人比较麻烦,用vector保存各个点,只要两个岛之间每个点距离一样就好了,这里的形状的定 ...
- bosondata/chrome-prerender: Render JavaScript-rendered page as HTML/PDF/mhtml/png/jpeg using headless Chrome
bosondata/chrome-prerender: Render JavaScript-rendered page as HTML/PDF/mhtml/png/jpeg using headles ...
- CMSIS-SVD Schema File Ver. 1.0
<?xml version="1.0" encoding="UTF-8"?> <!-- date: 07.12.2011 Copyright ...
- mysql sql长度限制解决
mysql sql长度限制解决 今天发现了一个错误: Could not execute JDBC batch update 最后发现原因是SQL语句长度大于1M,而我机器上的mysql是 ...
- 牛客网java基础知识
1.java把表示范围大的数转换为表示范围小的数,需要强制类型转换. Java中,数据类型分为基本数据类型(或叫做原生类.内置类型)和引用数据类型.原生类型为基本数据类型int和布尔值可以相互转换吗? ...
- 介紹 IIS 8 全新的 HttpPlatformHandler 模組與 ASP.NET 5 Beta8 重大變更
HttpPlatformHandler 是一個支援 IIS 8 與 IIS 8.5 的原生模組 (native module),主要使用於 Microsoft Azure Websites 網站服務中 ...