5种网络通信设计模型(也称IO模型)
1、基本概念
同步:同步函数一般指调用函数后,等到函数功能实现再返回,期间一直霸占的CPU,等待期间同一个线程无法执行其他函数
异步:异步函数指调用函数后,不管函数功能是否实现,立马返回;通过回调函数等告知函数功能完成
阻塞:调用某些函数阻塞是因为函数功能没有实现,主动放弃CPU,让其他线程的得以执行;当功能实现后,函数返回
非阻塞:调用某些函数不会进入阻塞,无论实现与否,都会返回结果
2、5种 IO 模型
阻塞模型
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待
特点:
当希望能够立即发送和接收数据,且处理的套接字数量比较少的情况下,使用阻塞模式来开发网络程序比较合适。
阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,其扩展性很差
非阻塞模型
程序框架如下:
while true {
for i in stream[]
{
if i has data
read until unavailable
}
}
特点:
不像阻塞模型需要为每个socket创建一个线程,非阻塞只需要一个线程,但是会一直占用CPU
复用模型
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞(根据实参规定最长进入阻塞时间,是否进入阻塞),但是和阻塞I/O所不同的的,这些函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作、多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
程序框架如下:
while true {
select(streams[])
for i in streams[] {
if i has data
read until unavailable
}
}
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
因为select()只会告诉我们有套接字可读或可写,没有指明是哪个套接字的哪个事件发生,所以需要遍历每个套接字,时间复杂度是O(n)。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:(有待重新组织语言)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
程序框架如下;
while true {
active_stream[] = epoll_wait(epollfd)
for i in active_stream[] {
read or write till unavailable
}
}
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知
epoll的优点:
2、效率提升,不是无差别轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数,时间复杂度为O(k),k为产生I/O事件的流的个数
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
select、poll、epoll 区别总结:
1、一个进程所能打开的最大连接数
|
select |
单个进程所能打开的最大连接数由FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。 |
|
poll |
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 |
|
epoll |
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接 |
2、FD剧增后带来的IO效率问题
|
select |
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 |
|
poll |
同上 |
|
epoll |
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 |
3、 消息传递方式
|
select |
内核需要将消息传递到用户空间,都需要内核拷贝动作 |
|
poll |
同上 |
|
epoll |
epoll通过内核和用户空间共享一块内存来实现的。 |
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
3、epoll 能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率
信号驱动模型
首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
异步模型
简介:数据拷贝的时候进程无需阻塞。
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作
比较
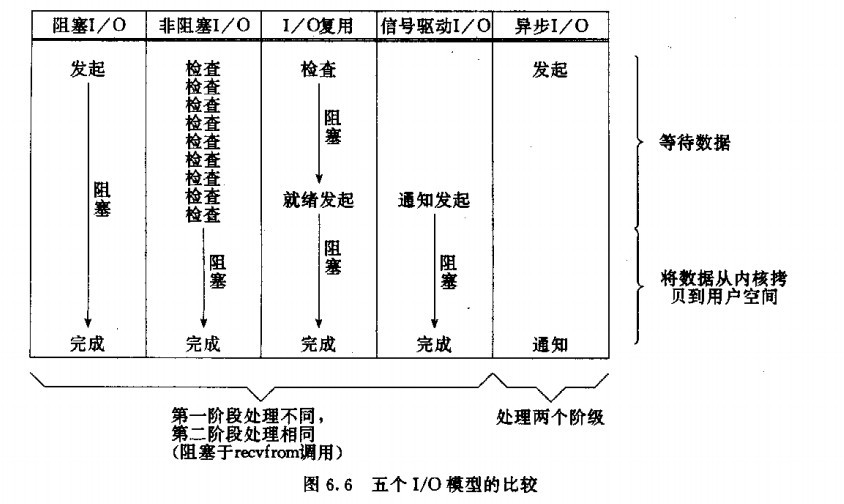
5种网络通信设计模型(也称IO模型)的更多相关文章
- Linux 网络编程的5种IO模型:异步IO模型
Linux 网络编程的5种IO模型:异步IO模型 资料已经整理好,但是还有未竟之业:复习多路复用epoll 阅读例程, 异步IO 函数实现 背景 上一讲< Linux 网络编程的5种IO模型:信 ...
- 网络IO模型 非阻塞IO模型
网络IO模型 非阻塞IO模型 同步 一件事做完后再做另一件事情 异步 同时做多件事情 相对论 多线程 多进程 协程 异步的程序 宏观角度:异步 并发聊天 阻塞IO 阻塞IO的问题 一旦阻塞就不能做其他 ...
- IO阻塞模型、IO非阻塞模型、多路复用IO模型
IO操作主要包括两类: 本地IO 网络IO 本地IO:本地IO是指本地的文件读取等操作,本地IO的优化主要是在操作系统中进行,我们对于本地IO的优化作用十分有限 网络IO:网络IO指的是在进行网络操作 ...
- [转载] Linux五种IO模型
转载:http://blog.csdn.net/jay900323/article/details/18141217 Linux五种IO模型性能分析 目录(?)[-] 概念理解 Lin ...
- (转载) Linux五种IO模型
转载:http://blog.csdn.net/jay900323/article/details/18141217 Linux五种IO模型及分析 目录(?)[-] 概念理解 Linux下 ...
- 浅聊Linux的五种IO模型
在日常 Coding 中,多多少少都会接触到网络 IO,就会想要深入了解一下.看了很多文章,总是云里雾里的感觉,直到读了<UNIX网络编程 卷1:套接字联网API>中的介绍后,才豁然开朗. ...
- 五种IO模型透彻分析
1.基础 在引入IO模型前,先对io等待时某一段数据的"经历"做一番解释.如图: 当某个程序或已存在的进程/线程(后文将不加区分的只认为是进程)需要某段数据时,它只能在用户空间中属 ...
- Linux五种IO模型(同步 阻塞概念)
Linux五种IO模型 同步和异步 这两个概念与消息的通知机制有关. 同步 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回.比如,调用readfrom系统调用时,必须等待IO操 ...
- 7.3 5种IO模型与IO复用
5种IO模型分别如下: 1.阻塞IO模型 当上层应用app1调用recv系统调用时,如果对等方没有发送数据(缓冲区没有数据),上层app1将阻塞(默认行为,被linux内核阻塞). 当对等方发送了数据 ...
随机推荐
- while read读取文本内容
读取文件给 while 循环 方式一: exec <FILE while read line do cmd done 方式二: cat FILE_PATH |while read line do ...
- shell基础 -- 入门篇
shell 英文含义是“壳”,这是相对于内核来说的,shell 也确实就像是内核的壳,通常来说,所有对内核的访问都要经由 shell .同时,shell 还是一门功能强大的编程语言.shell 是 L ...
- Yii2 配置request组件解析 json数据
在基础版本的config目录下 web.php 或者高级版config目录下的main.php中配置 'components' =>[ 'request' => [ 'parsers' = ...
- 详讲H5、WebApp项目中常见的坑以及注意事项
首先我们中会有一些常用的meta标签,如下: <!--防止手机中网页放大和缩小--> <meta name="viewport" content="wi ...
- 如何理解IPD+CMMI+Scrum一体化研发管理解决方案之Scrum篇
如何快速响应市场的变化,如何推出更有竞争力的产品,如何在竞争中脱颖而出,是国内研发企业普遍面临的核心问题,为了解决这些问题,越来越多的企业开始重视创新与研发管理,加强研发过程的规范化,集成产品开发(I ...
- HDU 5636 Shortest Path
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5636 题解: 1.暴力枚举: #include<cmath> #include<c ...
- 《我是一只IT小小鸟》 读书笔记
<我是一只IT小小鸟>讲述了IT人员的成长经历,邀请了许多名IT行业的职员,学生,研究生写了自己的亲身经历和人生感悟,以书中可以看到我国IT行业的快速进步,以及看到IT员在这条道路上的坎坷 ...
- Alpha 冲刺8
队名:日不落战队 安琪(队长) 今天完成的任务 登录的数据post. okhttp学习第二弹. 明天的计划 okhttp学习第三弹. 个人信息界面数据get. 还剩下的任务 个人信息数据get. 遇到 ...
- python基础(一)简单入门
一.第一个python程序 1.交互式编程 直接在命令行里面输入python即可进入python交互式命令行,linux下一样: 在 python 提示符中输入以下文本信息,然后按 Enter 键查看 ...
- Linux服务器启动后只读解决办法
今天处理一个服务器,远程死活连接不上,只好跑信息中心去看了下服务器. Linux服务器启动之后,提示: give root password for maintenance (or type cont ...