第三章:Hadoop简介及配置Hadoop-1.2.1,hbase-0.94.13集群
前面给大家讲了怎么安装Hadoop,肯定会有人还是很迷茫,装完以后原来就是这个样子,但是怎么用,下面,先给大家讲下Hadoop简介:大致理解下就OK了
hadoop是一个平台,提供了庞大的存储和并行计算的能力.
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。Hadoop的核心内容是HDFS和MpReduce.Hadoop项目结构有一下9中:
Common:是Hadoop其他子项目提供支持的常用工具。
Avro:是用于数据序列化的系统。
MapReduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
HDFS:是一个分布式文件系统。
Chukwa:是开源的数据收集系统,用于监控和分析大型分布式系统的数据
Hive:最早是由Facebook设计的,是一个建立在Hadoop基础之上的数据仓库。hive也可以提供查询但是它是非实时的,离线查询,hive不能提供实时查询,
他需要hadoop的mapreduce计算,hive把普通的sql语句转换成mapreduce程序计算,让那些不懂java但是懂sql的人能够参与到hadoop中。hive将
表的信息存放在metastore中,默认是dubey数据库中,真正的数据存放在hdfs中。
HBase:hbase是hadoop的数据库,提供了毫秒级别的数据查询,是一个分布式,面向列的开源数据库.HBase做实时查询
Pig:是一个对大型数据集进行分析,评估的平台。
ZooKeeper:是一个分布式应用所设计的开源协调服务。
Hadoop的API地址:http://hadoop.apache.org/docs/current/api/
hadoop体系结构:先介绍HDFS的体系结构:
HDFS采用主从(master/slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成,其中NameNode作为主服务器,管理文件系统
的命名空间和客户端对文件的访问操作;集群中DataNode管理存储的数据。HDFS允许用户以文件形式存储数据。
介绍MapReduce的体系结构:
MapReduce是一种并行编程模式。MapReduce框架是由一个单独运行在主节点的jobtracker和运行在每个集群从节点的tasktracker共同组成的。主节点
负责调度构成一个作业的所有任务,这些任务分布在不同的节点上,主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。
重点讲下:配置Hadoop集群,hbase集群
一.首先,先搭建四台小集群,虚拟机的话,创建四个
下面为这四台机器分别分配IP地址及相应的角色:集群有个特点,四台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去,我这四台的用户名都是hadoop,主机名随意起
192.168.0.10-----master(主机),nameNode,jobtracker----master(主机名)
192.168.0.11-----slave1(从机),dataNode,tasktracker-----slave1(主机名)
192.168.0.12-----slave2(从机),dataNode,tasktracker-----slave2(主机名)
192.168.0.13-----slave3(从机),dataNode,tasktracker-----slave3(主机名)
如果用户名不一致,你就要创建一个用户组,把用户放到用户组下面:
sudo addgroup hadoop 创建hadoop用户组
sudo adduser -ingroup hadoop one 创建一个one用户,归到hadoop组下
二.由于用户是普通用户,没有root一些权限,所以修改hadoop用户权限
用root权限,修改sudoers文件
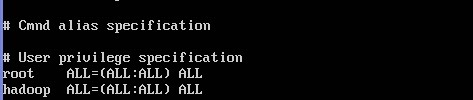
nano /etc/sudoers 打开文件,修改hadoop用户权限,如果你创建的是one用户,就one ALL=(ALL:ALL) ALL
三.要在这四台机子上均安装jdk,ssh,并配置好环境变量,四台机子都是这个操作::
做好准备工作,下载jdk-7u3-linux-i586.tar 这个软件包
1.sudo apt-get install openssh-server 下载SSH
ssh 查看,代表安装成功
tar zxvf jdk-7u3-linux-i586.tar.gz 解压jdk
2.sudo nano /etc/profile,在最下面加入这几句话,保存,这是配置java环境变量

验证jdk是否安装成功,敲命令
java -version 可以看到JDK版本信息,代表安装成功

3:配置SSH 免密码登陆,记住,这是在hadoop用户下执行的
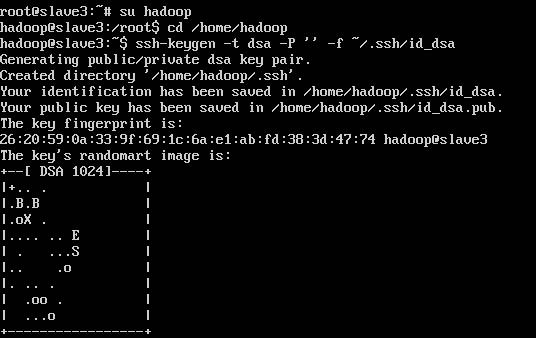
ssh-keygen -t dsa -P ' ' -f ~/.ssh/id_dsa
ssh-keygen代表生成密钥,-t代表指定生成的密钥类型,dsa代表密钥类型,-P代表提供密语,-f代表生成的密钥文件
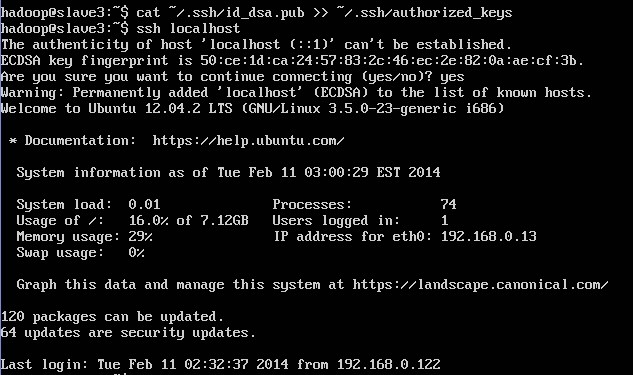
4.cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh localhost 没有让你输入密码就代表ssh装成功了
或者 ls .ssh/ 看看有没有那几个文件

5.这一步只需要主机master操作,复制秘钥到从机,这样可以无密码访问从机
cd .ssh
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh/
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh/
scp authorized_keys hadoop@slave3:/home/hadoop/.ssh/
chmod 644 authorized_keys 给秘钥赋予权限
ssh slave1 测试无密码访问主机slave1,第一次输入都要密码,以后就不需要了
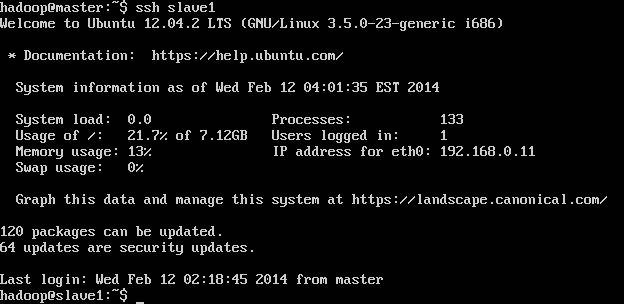
四.在这四台机子上分别设置/etc/hosts及/etc/hostname
hosts这个文件用于定于主机名与IP地址之间的对用关系
sudo -i 获取最高权限
nano /etc/hosts:
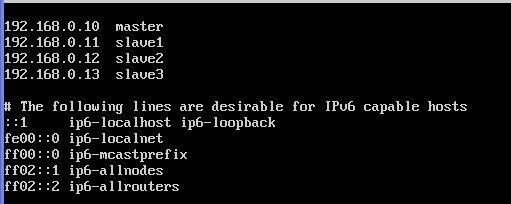
ctrl+o:保存,然后回车,ctrl+x:退出
hostname 这个文件用于定义主机名的,
注意:主机是主机名,从机就是从机名,例如:slave1在这里就是slave1

然后你可以输入:ping slave1,看能不能ping通
5,配置hadoop文件,这个配置只需要在主机master进行操作,从机的话,直接主机复制从机就OK了,但是从机会有一些改动,下面都有讲
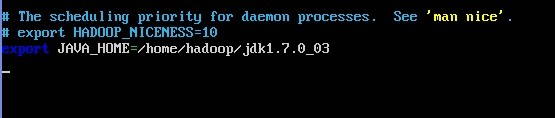
修改:conf/hadoop-env.sh,这个是配置jdk
sudo nano /home/hadoop/hadoop-1.1.2/conf/hadoop-env.sh
修改:conf/core-site.xml
sudo nano /home/one/hadoop-1.1.2/conf/core-site.xml

记住:tmp文件时需要手动创建的
mkdir /home/hadoop/tmp 创建tmp目录
sudo chmod 777 tmp/ 给tmp目录赋予权限
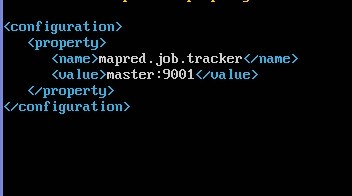
修改:conf/mapred-site.xml
sudo nano /home/one/hadoop-1.1.2/conf/mapred-site.xml
修改:/conf/hdfs-site.xml
sudo nano /home/one/hadoop-1.1.2/conf/hdfs-site.xml
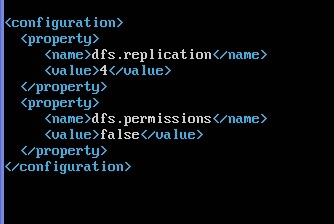 我们的集群有4个分机,所以rep4份
我们的集群有4个分机,所以rep4份
配置主从节点
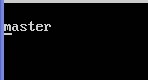
配置conf/masters来设置主节点,注意:最好使用主机名,并且保证机器之间通过主机名可以互相访问:
sudo nano /home/one/hadoop-1.1.2/conf/masters
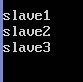
配置conf/slaves来设置从节点:
sudo nano /home/one/hadoop-1.1.2/conf/slaves
配置结束,如果不想分机在一个一个配置,可以把配置好的hadoop文件拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确
命令是在hadoop用户下进行:这个只需要在主机运行就可以了
scp -r /home/hadoop/hadoop-1.1.2 hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/hadoop-1.1.2 hadoop@slave2:/home/hadoop/
scp -r /home/hadoop/hadoop-1.1.2 hadoop@slave3:/home/hadoop/
6.虽然说复制到从机,但是从机有一些配置是不用要的,比如说配置主从节点
sudo nano /home/one/hadoop-1.1.2/conf/masters
把master删除掉
sudo nano /home/one/hadoop-1.1.2/conf/slaves
把slave1,slave2,slave3删除掉
修改:/conf/hdfs-site.xml
把dfs.permissions删除掉
sudo nano /home/one/hadoop-1.1.2/conf/hdfs-site.xml

7.hadoop集群启动与测试:这个只需要在主机上运行就可以了
sudo -i 获取root权限
chown -R hadoop:hadoop /home/hadoop/hadoop-1.2.1 给hadoop用户赋予权限
命令在hadoop用户下进行:
su hadoop 切换hadoop用户
cd /home/hadoop/hadoop-1.1.2
bin/hadoop namenode -format 格式化文件,格式化文件只能格式化一次,如果格式化多了,时间就会不同步,就会出错,这里有2个解决的方法
第一个方法,就是删除tmp文件,就是创建的那个文件
rm -rf tmp/ 删除tmp
mkdir /home/hadoop/tmp 创建tmp目录
sudo chmod 777 tmp/ 给tmp目录赋予权限,然后格式化,但是从机tmp跟主机的tmp会不同步,格式化以后,从机tmp都删除,主机复制从机
scp -r /home/hadoop/tmp hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/tmp hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/tmp hadoop@slave1:/home/hadoop/
第二个方法,修改每个DataNode的namespaceID(位于/tmp/dfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/tmp/dfs/name/current/VERSION文件中),
使其一致,第2个方法会好些,因为一些文件都是存放在tmp里面,如果删除,数据也会没有
bin/start-all.sh 启动所有的节点
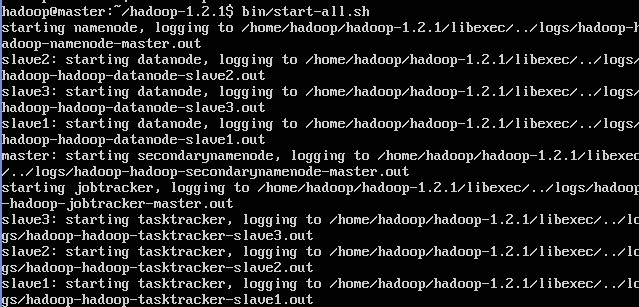
bin/hadoop dfsadmin -report 查看集群的状态
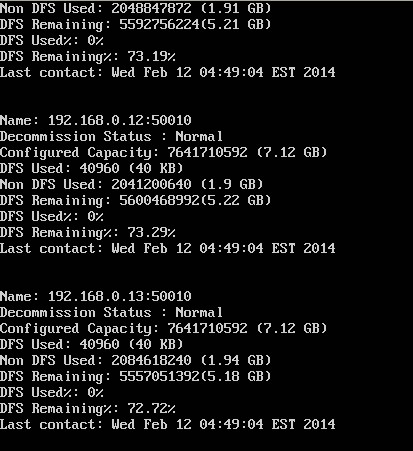
测试:
NameNode http://192.168.0.10:50070
JobTracker http://192.168.0.10:50030
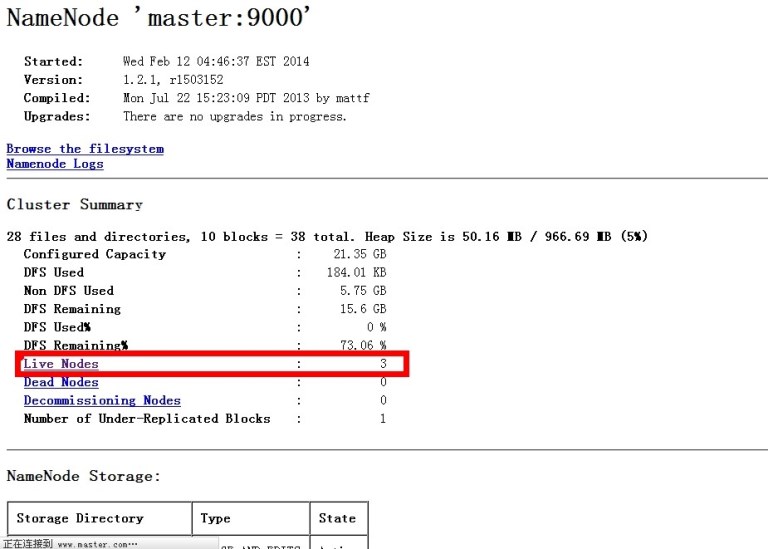
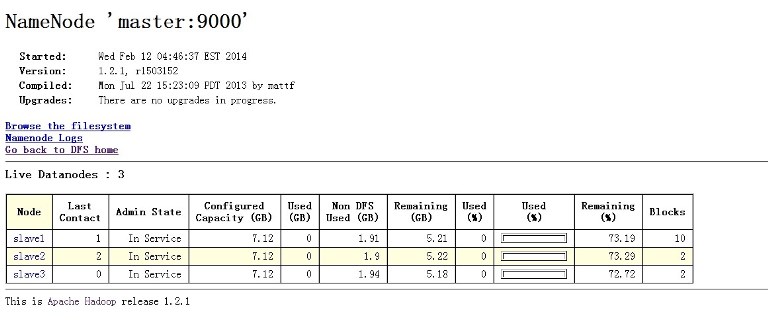
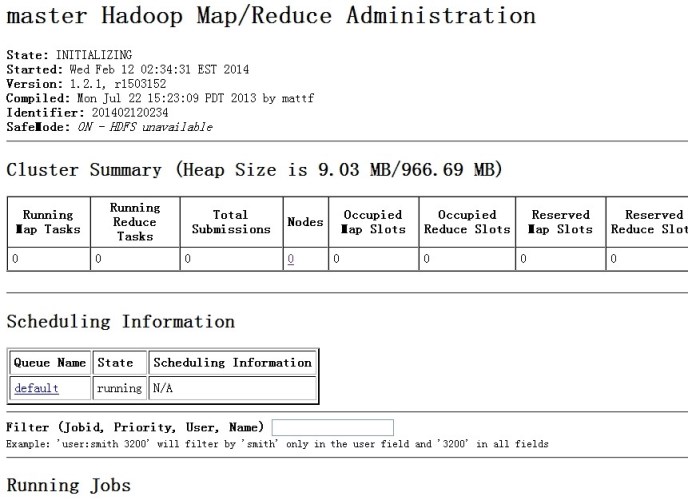
这样hadoop集群就配置完了,下面讲下配置hbase集群,都是在hadoop用户下操作,这个也是一样,主机搭建完以后,复制到从机上
1.下载并解压hbase-0.94.13.tar.gz到/home/hadoop下面
tar zxvf hbase-0.94.13.tar.gz
2.修改 hbase-env.sh ,hbase-site.xml,regionservers 这三个配置文件如下:
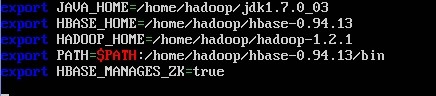
修改 hbase-env.sh
sudo nano /home/hadoop/hbase-0.94.13/conf/hbase-env.sh
修改 hbase-site.xml
sudo nano /home/hadoop/hbase-0.94.13/conf/hbase-site.xml

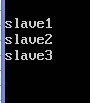
修改 regionservers
sudo nano /home/hadoop/hbase-0.94.13/conf/regionservers
复制hbase到从机
scp -r /home/hadoop/hbase-0.94.13 hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/hbase-0.94.13 hadoop@slave2:/home/hadoop/
scp -r /home/hadoop/hbase-0.94.13 hadoop@slave2:/home/hadoop/
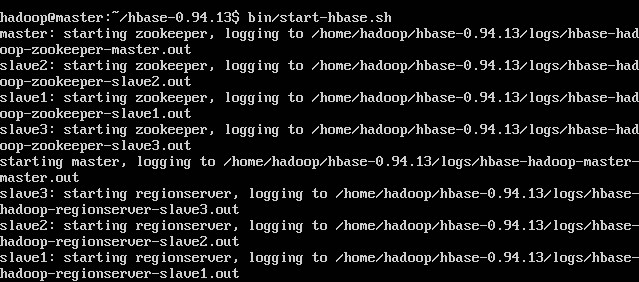
然后启动hbase,输入命令,记住:一定要先启动hadoop集群,才能启动hbase
bin/start-hbase.sh
我们也可以通过WEB页面来管理查看HBase数据库。
HMaster:http://172.16.48.201:60010/master.jsp
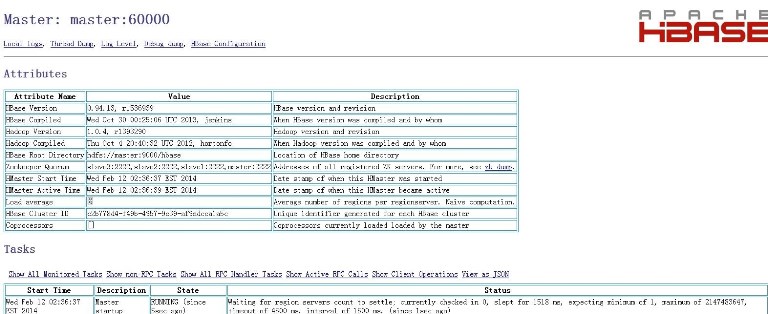
可以输入jps查看HMaster
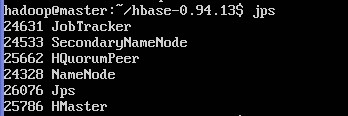
然后输入如下命令进入hbase的命令行管理界面:?quit 退出
bin/hbase shell

bin/stop-hbase.sh 退出hbase
第三章:Hadoop简介及配置Hadoop-1.2.1,hbase-0.94.13集群的更多相关文章
- The Django Book 第三章 试图和URL配置
之前自学Django也有一段时间了,再过一个月就要入职新公司了(Python Django开发),即使现在还在入门级徘徊,再好好把Django基础过一遍吧. The Django Book 第三章 试 ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 基于Hadoop 2.2.0的高可用性集群搭建步骤(64位)
内容概要: CentSO_64bit集群搭建, hadoop2.2(64位)编译,安装,配置以及测试步骤 新版亮点: 基于yarn计算框架和高可用性DFS的第一个稳定版本. 注1:官网只提供32位re ...
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- Hadoop 3.0完全分布式集群搭建方法(CentOS 7+Hadoop 3.2.0)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是3.2.0,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- Hadoop 2.0完全分布式集群搭建方法(CentOS7+Hadoop 2.7.7)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是2.7.7,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
随机推荐
- MoreEffectiveC++Item35(操作符)(条款5-8)
条款5 对定制的"类型转换函数"保持警惕 条款6 区别increment/decrement操作符的前值和后置形式 条款7 千万不要重载&&,||,和,操作符 条款 ...
- TypeError: pivot_table() got an unexpected keyword argument 'rows'
利用Python进行数据分析>第二章,处理MovieLens 1M数据集,有句代码总是报错: mean_rating = data.pivot_table('rating', rows='tit ...
- JSON Schema(模式)
JSON Schema指的是数据交换中的一种虚拟的“合同”. JSON验证器负责验证语法错误,JSON Schema负责提供一致性检验. JSON Schema是数据接收方额第一道防线,也是数据发送方 ...
- WIP - Study Perf (by quqi99)
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明 (http://blog.csdn.net/quqi99) Perf Flame Graph sudo perf ...
- Asp.Net MVC webAPI Token based authentication
1. 需要安装的nuget <package id="Microsoft.AspNet.Identity.Core" version="2.2.1" ta ...
- C# 超级狗 二次开发 读写数据 激活验证 存储数据库连接字符串
本文主要讲解如果使用C#语言来对超级狗进行二次开发,如果仅仅是做个激活的功能,可以参照另一篇博客,地址:http://www.cnblogs.com/dathlin/p/8487842.html 如果 ...
- linux c++ 多线程心得
好久没写多线程了,工作好几年也没怎么大规模的写过多线程,都是成形的架构里写业务逻辑.偶尔自己写了下,各种踩坑... 1.string 不是线程安全的 一个特例是std::string.在一些STL的实 ...
- stark组件
写一个stark组件仿造admin的功能 1:新建一个stark的app 问题:在django每次启动会扫描目录下所有的admin文件,需要扫描项目目录下的每个stark文件,我们需要怎么做 1:看在 ...
- WEB服务器都在做哪些工作?
作为WEB开发人员,我们肯定应该要知道WEB服务器都在做哪些工作,这里简单列举一下,有时间然后详细说明. (1)建立连接——接受一个客户端连接. (2)接收请求——从网络中读取一条 HTTP 请求报文 ...
- 百度的富文本编辑器UEDITOR
还是百度的ueditor 比较好用,文件导入后,基本不用配置就可以直接使用图片,文件上传等功能. CKeditor要注意的地方太多了 .但是相对ckeditor 样式比较好看.