Python全栈开发之3、数据类型set补充、深浅拷贝与函数
转载请注明出处http://www.cnblogs.com/Wxtrkbc/p/5466082.html
一、基本数据类型补充
set是一个无序而且不重复的集合,有些类似于数学中的集合,也可以求交集,求并集等,下面从代码里来看一下set的用法,如果对这些用法不太熟悉的话,可以照着下面的代码敲一遍。
s1={1,2,3,1} #定义一个set s1 如果s1={}为空则默认定义一个字典
s2=set([2,5,6]) #定义一个set s2
print(s1) #s1={1,2,3} 自动去除重复的元素
s1.add(5) #s1={1,2,3,5} 添加一个元素
print(s1)
s3=s1.difference(s2) #返回一个s1中存在而不存在于s2的字典s3,s3={1,3},而s1并没有改变
print(s3)
s1.difference_update(s2) #s1跟新成上面的s3 s1={1,3}
s1.discard(1) #删除元素1,不存在的话不报错 s1={3}
print(s1)
s1.remove(3) #删除元素3,不存在的话报错 s1={}
print(s1)
s1.update([11,2,3]) #跟新s1中的元素,其实是添加 s1={11,2,3}
print(s1)
k=s1.pop() #删除一个元素,并将删除的元素返回给一个变量,无序的,所以并不知道删除谁
s1={1,2,3,4} #这里重新定义了集合s1,s2
s2={3,4,5,6}
r1=s1.intersection(s2) #取交集,并将结果返回给一个新的集合 r1={3,4}
print(r1)
print(s1)
s1.intersection_update(s2) #取交集,并将s1更新为取交集后的结果 s1={3,4}
print(s1)
k1=s1.issubset(s2) #s1是否是s2的的子序列是的话返回True,否则False 这里k1=true
print(k1)
k2=s1.issuperset(s2) #s1是否是s2的父序列 k2=False
k3=s2.isdisjoint(s1) #s1,s2,是否有交集,有的话返回False,没有的话返回True
print(k3)
s1.update([1,2]) #s1={1,2,3,4}
r3=s1.union(s2) #取并集将结果返回给r3 r3={1,2,3,4,5,6}
print(r3)
r2=s1.symmetric_difference(s2) #r2=s1并s2-s1交s2 r2={1,2,5,6}
print(r2)
s1.symmetric_difference_update(s2) #s1更新为 s1并s2 - s1交s2 s1={1,2,5,6}
print(s1)
二、三目运算符
三目运算符可以简化条件语句的缩写,可以使代码看起来更加简洁,三目可以简单的理解为有三个变量,它的形式是这样的 name= k1 if 条件 else k2 ,如果条件成立,则 name=k1,否则name=k2,下面从代码里面来加深一下理解,从下面的代码明显可以看出三目运算符可以使代码更加简洁。
a=1
b=2
if a<b: #一般条件语句的写法
k=a
else:
k=b c=a if a<b else b #三目运算符的写法
三、深拷贝浅拷贝
拷贝意味着对数据重新复制一份,对于拷贝有两种深拷贝,浅拷贝两种拷贝,不同的拷贝有不同的效果。拷贝操作对于基本数据结构需要分两类进行考虑,一类是字符串和数字,另一类是列表、字典等。如果要进行拷贝的操作话,要import copy。
1、数字和字符串
对于数字和字符串而言,深拷贝,浅拷贝没有什么区别,因为对于数字数字和字符串一旦创建便不能被修改,假如对于字符串进行替代操作,只会在内存中重新生产一个字符串,而对于原字符串,并没有改变,基于这点,深拷贝和浅拷贝对于数字和字符串没有什么区别,下面从代码里面说明这一点。
import copy
s='abc'
print(s.replace('c','222')) # 打印出 ab222
print(s) # s='abc' s并没有被修改
s1=copy.deepcopy(s)
s2=copy.copy(s) #可以看出下面的值和地址都一样,所以对于字符串和数字,深浅拷贝不一样,数字和字符串一样就不演示了,大家可以去试一下
print(s,id(s2)) # abc 1995006649768
print(s1,id(s2)) # abc 1995006649768
print(s2,id(s2)) # abc 1995006649768
2、字典、列表等数据结构
对于字典、列表等数据结构,深拷贝和浅拷贝有区别,从字面上来说,可以看出深拷贝可以完全拷贝,浅拷贝则没有完全拷贝,下面先从内存地址分别来说明,假设 n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}。
浅拷贝在内存中只额外创建第一层数据 深拷贝在内存中将所有的数据重新创建一份
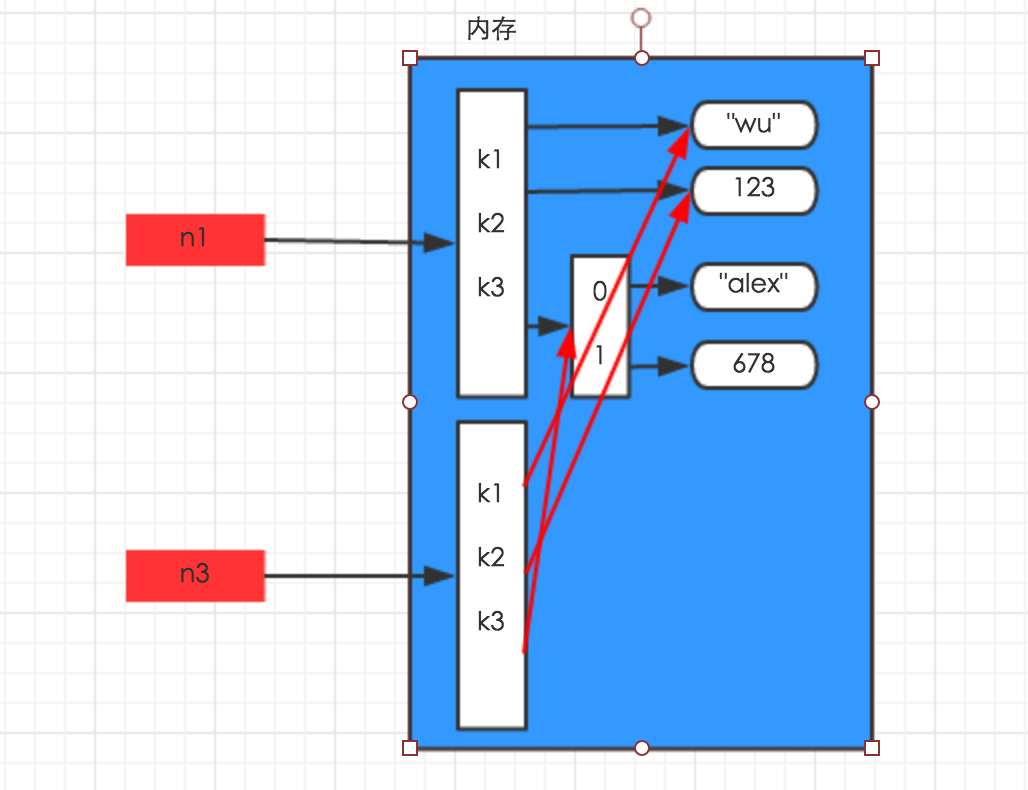
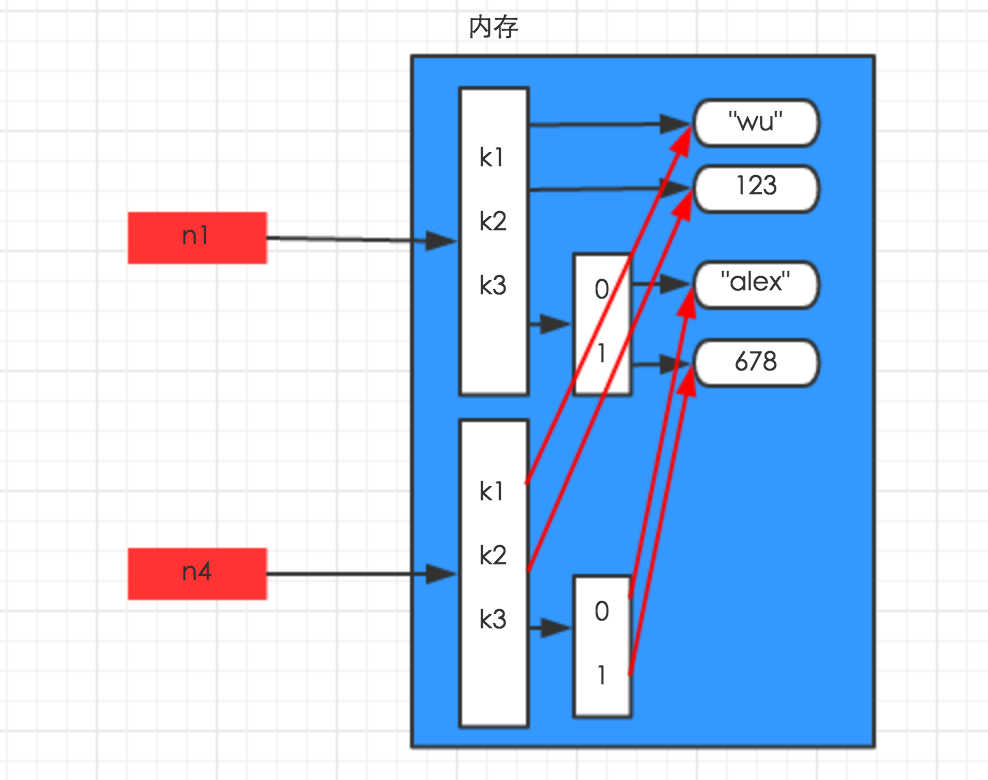
下面从代码上来进行说明,
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2=copy.copy(n1) # 浅拷贝
n3=copy.deepcopy(n1) # 深拷贝
print(n1,id(n1),id(n1['k1']),id(n1['k3']))
print(n2,id(n2),id(n2['k1']),id(n2['k3']))
print(n3,id(n3),id(n3['k1']),id(n3['k3'])) # 从下面打印的值结合上面的图就可以很好的理解,
# {'k3': ['alex', 456], 'k2': 123, 'k1': 'wu'} 2713748822024 2713753080528 2713755115656
# {'k3': ['alex', 456], 'k2': 123, 'k1': 'wu'} 2713755121416 2713753080528 2713755115656
# {'k3': ['alex', 456], 'k2': 123, 'k1': 'wu'} 2713753267656 2713753080528 2713754905800
四、函数
如果我们要计算一个圆的面积,就需要知道它的半径,然后根据公式S=3.14*r*r算出它的面积,如果我们要算100个圆的面积,则每次我们都需要写公式去计算,是不是很麻烦,但是有了函数的话,我们就不再每次写S=3.14 *r*r,而是把计算圆面积的功能写到一个函数里比如说s=areacircle(r),然后每次求面积的时候,只要把半径传递给函数就可以实现计算圆面积,这样我们写代码就简单多了。这就是函数的功能。
1、定义函数
定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。比如说定义一个求和函数
def sum(a,b): #定义函数
ret=a+b #函数体
return ret #函数返回
print(sum(1,2)) #调用函数并打印出结果 #如果没有return语句,函数执行完毕后也会返回结果,只是结果为None
2、函数的参数
函数的参数有位置参数、默认参数、可变参数、关键字参数等,此外需要注意的是Python里面传参数的时候传的是引用,而不是在创建一份新的值,下面分别来说明
# 位置参数
# 函数调用的时候,传递的参数必须按顺序与定义的函数一一对应
def fun1(name): #name为位置参数
print(name)
fun1('Jason') #将Jason 传递给func函数作为默认参数 # 默认参数
# 需要放在参数列表最后
def fun2(name,age=19): #age=19是默认参数,如果不传的话默认为19
print('%s:%s' %(name,age))
fun2("Jason",18) #将Jason和18 传给name和age # 可变参数
# 可以传递任意个参数,自动组装成元组元素
def fun3(*args):
print(args,type(args))
fun3(1,2,3) #直接传递参数
l=list([1,2,3,4])
fun3(*l) #或者在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去 #关键字参数
#可传入任意个含参数名的参数,自动组装为一个dict
def fun4(**kwargs):
print((kwargs,type(kwargs)))
fun4(k=1) #定义一个关键字参数
l={'k1':1,'k2':2}
fun4(**l) #或者先定义一个字典,在前面加上**变成关键字参数传给函数 # 可以定义一个函数 func(*args, **kw) 这样无论什么样的参数都可以传递给函数 #传递的是引用
def fun5(s):
s.append(333) #这里s指向 l
l=[11,22]
fun5(l)
print(l) #l=[11,22,333] #注意与上一种情况比较
def fun6(s):
s=112 #这里s指向 112
l=[1,2,3]
fun6(l)
print(l) #l=[1,2,3]
五、作业
1.寻找差异
# 数据库中原有
old_dict = {
"#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#2":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 }
}
# cmdb 新汇报的数据
new_dict = {
"#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 800 },
"#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#4":{ 'hostname':'c2', 'cpu_count': 2, 'mem_capicity': 80 }
}
old_set=set(old_dict)
new_set=set(new_dict) del_set=old_set.difference(new_set)
add_set=new_set.difference(old_set)
flush_set=old_set.intersection(new_set) for i in del_set:
old_dict.pop(i) for i in add_set:
old_dict[i]=new_dict[i] for i in flush_set:
old_dict[i] = new_dict[i]
print(old_dict)
2、简述普通参数、指定参数、默认参数、动态参数的区别
普通参数传递的个数和顺序要明确,默认参数传递的时候,如果没有给默认参数复制的话,会使用默认值,如果给定了的话,就会使用给定值。动态参数的个数不确定,可以传递任意个参数,这些参数自动组装成一个元组,可以在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去,指定参数传递的是一个明确的类似键值,这些参数自动组装成一个字典,可以先定义一个字典,在前面加上**变成关键字参数传给函数。
3、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
def fun(s):
digitnum, alphanum, sapcenum, othernum=0,0,0,0
for i in s:
if i.isdigit():
digitnum+=1
elif i.isalpha():
alphanum+=1
elif i.isspace():
sapcenum+=1
else:
othernum+=1
return (digitnum,alphanum,sapcenum,othernum)
4、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5
def fun(s):
ret=False
if isinstance(s,str) or isinstance(s,str) or isinstance(s,tuple):
if len(s)>5:
ret=True
return ret
5、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容
def fun(s):
ret=False
if isinstance(s, str) or isinstance(s, str) or isinstance(s, tuple):
for i in s:
if i=='':
ret=True
break
return ret
6、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def fun(s):
if isinstance(s,list):
if len(s)>2:
return s[0:2]
return None
7、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
def fun(s):
if isinstance(s,list) or isinstance(s,tuple):
l=[]
for i in range(1,len(s),2):
l.append(s[i])
return l
return None
8、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def fun(s):
if isinstance(s,dict):
for i in s:
if len(s[i])>2:
s[i]=s[i][0:2]
return s
9、写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者。
def fun(n):
if 1==n :
return 0
elif 2==n:
return 1
else:
return fun(n-1)+fun(n-2)
Python全栈开发之3、数据类型set补充、深浅拷贝与函数的更多相关文章
- Python全栈之路3--set集合--三元运算--深浅拷贝--初识函数
一.上节课的重点回顾: 1.类名加括号其实就是执行类的__init__方法: 2.int a.创建方式 n1 = 123 #根据int类创建了一个对象 n2 = int(123) #根据int类创建一 ...
- 战争热诚的python全栈开发之路
从学习python开始,一直是自己摸索,但是时间不等人啊,所以自己为了节省时间,决定报个班系统学习,下面整理的文章都是自己学习后,认为重要的需要弄懂的知识点,做出链接,一方面是为了自己找的话方便,一方 ...
- python全栈开发之OS模块的总结
OS模块 1. os.name() 获取当前的系统 2.os.getcwd #获取当前的工作目录 import os cwd=os.getcwd() # dir=os.listdi ...
- Python全栈开发之MySQL(二)------navicate和python操作MySQL
一:Navicate的安装 1.什么是navicate? Navicat是一套快速.可靠并价格相宜的数据库管理工具,专为简化数据库的管理及降低系统管理成本而设.它的设计符合数据库管理员.开发人员及中小 ...
- Python全栈开发之14、Javascript
一.简介 前面我们学习了html和css,但是我们写的网页不能动起来,如果我们需要网页出现各种效果,那么我们就要学习一门新的语言了,那就是JavaScript,JavaScript是世界上最流行的脚本 ...
- Python全栈开发之1、输入输出与流程控制
Python简介 python是吉多·范罗苏姆发明的一种面向对象的脚本语言,可能有些人不知道面向对象和脚本具体是什么意思,但是对于一个初学者来说,现在并不需要明白.大家都知道,当下全栈工程师的概念很火 ...
- Python全栈开发之3、深浅拷贝、变量和函数、递归、函数式编程、内置函数
一.深浅拷贝 1.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. import copy # 定义变量 数字.字符串 # n1 = 123 n1 ...
- Python全栈开发之2、运算符与基本数据结构
运算符 一.算数元算: 读者可以跟着我按照下面的代码重新写一遍,其中需要注意的是,使用除的话,在python3中可以直接使用,结果是4没有任何问题,但是在python2中使用的话,则不行,比如 9/2 ...
- Python全栈开发之2、数据类型-数值、字符串、列表、字典、元组和文件处理
一.Python 运算符 1.算术运算: 2.比较运算: 3.赋值运算: 4.逻辑运算: 5.成员运算: 二.基本数据类型 1.数字整型 int(整型) 在32位机器上,整数的位数为32位,取值范围为 ...
随机推荐
- codeforces 691E 矩阵快速幂+dp
传送门:https://codeforces.com/contest/691/problem/E 题意:给定长度为n的序列,从序列中选择k个数(可以重复选择),使得得到的排列满足xi与xi+1异或的二 ...
- Libevent学习笔记(四) bufferevent 的 concepts and basics
Bufferevents and evbuffers Every bufferevent has an input buffer and an output buffer. These are of ...
- 「PLC」PLC的硬件与工作原理
- MingW和MSVC默认的编码方式不一样
同一份源代码,源文件编码格式为UTF-8: string tmp = "我"; ;i<tmp.size();++i) { printf("%0x ",tm ...
- codevs 1029 遍历问题
1029 遍历问题 http://codevs.cn/problem/1029/ 时间限制: 1 s 空间限制: 128000 KB 题目描述 Description 我们都很熟悉二叉树的 ...
- 数字配对(bzoj 4514)
Description 有 n 种数字,第 i 种数字是 ai.有 bi 个,权值是 ci. 若两个数字 ai.aj 满足,ai 是 aj 的倍数,且 ai/aj 是一个质数, 那么这两个数字可以配对 ...
- Java--图片浏览器
功能:启动后选择打开文件,可以打开图片进行浏览. v 1.0 :支持上一张 下一张功能.(欠缺,窗口大小未随着图片大小而改变) import java.awt.BorderLayout; import ...
- Python学习笔记(四十八)POP3收取邮件
收取邮件就是编写一个MUA作为客户端,从MDA把邮件获取到用户的电脑或者手机上.收取邮件最常用的协议是POP协议,目前版本号是3,俗称POP3. Python内置一个poplib模块,实现了POP3协 ...
- TED_Topic1:Why we need to rethink capitalism
Topic 1:Why we need to rethink capitalism By Paul Tudor Jones II # Background about our speaker ...
- 向量与矩阵的范数及其在matlab中的用法(norm)
一.常数向量范数 \(L_0\) 范数 \(\Vert x \Vert _0\overset{def}=\)向量中非零元素的个数 其在matlab中的用法: sum( x(:) ~= 0 ) \(L_ ...