什么是spark(五)Spark SQL
Spark SQL
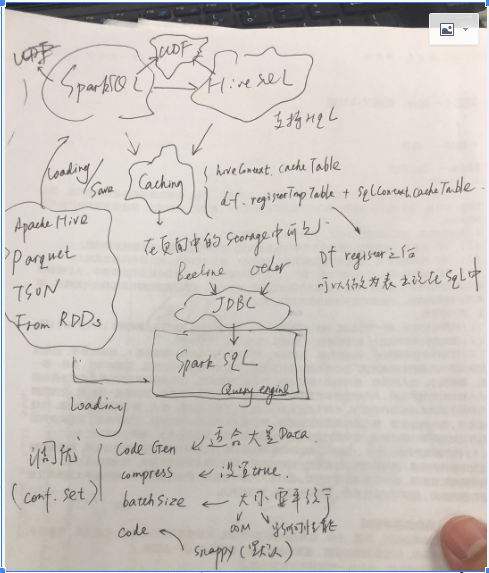
Spark SQL主要分为两部分,一部分是Spark Sql在scala中直接,使用作为执行层面上的应用,本质上就是生成DAG的另外一种形式;其发生试下Driver中生成;
另外一部分是spark SQL作为查询引擎,供client端通过jdbc来进行调用;
SparkContext和HiveContext是sparkSQL开发索要操作的对象,后者提供了HQL的查询;前者不支持HQL,但是支持普通的SQL;很多针对Hive的一些sql不支持,所以对于Hive表的查询,建议使用HiveContext;基本的思路是首先通过SQL语句获得dataframe,通过dataframe进行注册
除此之外Spark/HivecContext支持Cache;Cache的数据将会在Spark的页面中的Storage中看到;支持UDF(User Define Function)。
SparkSQL同样支持Hive,Parquet,JSON,而且可以通过RDD获得DataFrame;
SparkSQL调优:
1)code gen,适合于大量的数据;
2)compress,对于内存数据进行压缩;
3)batchsize,多少数据进行压缩;
4)codec,压缩的编码;
这些调优参数都是在conf里面设置的。
什么是spark(五)Spark SQL的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子
[Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子 $cat people.json {"name":" ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
不多说,直接上干货! 最近,开始,进一步学习spark的最新版本.由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz. 前期博客 Spark ...
- [Spark] 05 - Spark SQL
关于Spark SQL,首先会想到一个问题:Apache Hive vs Apache Spark SQL – 13 Amazing Differences Hive has been known t ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [Spark][Python]spark 从 avro 文件获取 Dataframe 的例子
[Spark][Python]spark 从 avro 文件获取 Dataframe 的例子 从如下地址获取文件: https://github.com/databricks/spark-avro/r ...
随机推荐
- classpath到底指的哪里
之前一直对classpath不太明白到底指的哪里,今天研究了一下,做个总结.. classpath顾名思义就是指类路径,但是这样解释可能还是不明白,这里拿一个SpringBoot应用编译后生成的tar ...
- webstrom提示不见了
今天做项目时候,不知道怎么搞的我的神编辑器webstrom没有了代码提示!!! 重启软件.重启电脑甚至卸载重装都不行,研究了半天终于知道问题出在了哪: 后来我发现在Webstorm的菜单[File]里 ...
- SPOJ 694 && SPOJ 705 (不重复子串个数:后缀数组)
题意 给定一个字符串,求它的所有不重复子串的个数 思路 一个字符串的子串都必然是它的某个后缀的前缀.对于每一个sa[i]后缀,它的起始位置sa[i],那么它最多能得到该后缀长度个子串(n-sa[i]个 ...
- CF 914
照例看A 然后A了 看B 似乎博弈一下就可以了 然后看C 似乎是DP 然后看了room woc似乎有黑红名 赶紧hack 然后没有人有问题 思考为什么 突然看到房间有15hack... 好吧我做D 然 ...
- hdu4453
题解: splay模板 删除,翻转等等 代码: #include<cstdio> #include<cstring> #include<cmath> #includ ...
- ElementUI组件Cascader级联选择器数据后台处理
Cascader级联选择器数据数据格式不知道的可以去官网看下:这里我就不表示什么了. 部门实体类: import lombok.Data; @Data public class Department ...
- nodejs之log4js日志记录模块简单配置使用
在我的一个node express项目中,使用了log4js来生成日志并且保存到文件里,生成的文件如下: 文件名字叫:access.log 如果在配置log4js的时候允许了同时存在多个备份log文件 ...
- form表单序列化之后追加字段
方法是在{}中添加字段 key-value 一一对应,如下: var data = $.param({'state': state}) + '&' + $('#desProForm').ser ...
- 自己WIN7旗舰版安装 SQLServer2005/2008的一些总结
准备工作:下载安装包,当然要保证安装包能用: 安装:1.设置setup.exe文件 右键属性选择 --兼容,兼容下面选择---以管理员方式运行,---兼容模式选择windows xp或者windows ...
- 【Shell脚本】逐行处理文本文件
经常会对文体文件进行逐行处理,在Shell里面如何获取每行数据,然后处理该行数据,最后读取下一行数据,循环处理.有多种解决方法如下: 1.通过read命令完成. read命令接收标准输入,或其他文件描 ...