[转] Jenkins pipeline 踩坑集合
[From] https://testerhome.com/topics/10328
前言
最近由于项目需要,接触到了Jenkins 2.0版本,其中最重要的特性就是提供了对pipeline的支持。
简单的来说,就是把Jenkins1.0版本中,Project中的相关配置信息,如SVN/Git的配置,Parameter的配置等都变成Code,即Pipeline as Code。
这样的优势为可以通过写代码的形式配置Project,且Jenkins中内置了常用的steps。实现了构建步骤代码化、构建过程视图化。
其他的Jenkins基础这里不多说了,这里主要介绍最近遇到的问题及其处理方法。一方面是自己总结和整理一下,另一方面也可以供他人参考,少踩坑。
选择Declarative Pipeline还是Scripted Pipeline
最开始的Pipeline plugin,支持的只有一种脚本类型,就是Scripted Pipeline;
Declarative Pipeline为Pipeline plugin在2.5版本之后新增的一种脚本类型,与原先的Scripted Pipeline一样,都可以用来编写脚本。
使用哪一种脚本格式呢,我又纠结了,也查询了些资料。
https://stackoverflow.com/questions/43484979/jenkins-scripted-pipeline-or-declarative-pipeline
http://jenkins-ci.361315.n4.nabble.com/Declarative-pipelines-vs-scripted-td4891792.html
最后,我还是选择了Declarative Pipeline,这也是后续Open Blue Ocean所支持的类型。
相对而言,Declarative Pipeline比较简单,如果Groovy很熟的,用Scripted Pipeline可能更顺手。
另外,Declarative Pipeline中,是可以内嵌Scripted Pipeline代码的。
设置和获取执行参数
原先在Jenkins 1.0的时候,常用的一个设置就是“ "This build is parameterized",通过获取参数值,执行后续相关的判断及操作。
在pipeline中,可以这样设置:
#!/usr/bin/env groovy
pipeline{
agent none
options{
disableConcurrentBuilds()
skipDefaultCheckout()
timeout(time: , unit: 'HOURS')
timestamps()
}
parameters{
string(name: 'PERSON', defaultValue: 'among中文', description: '请输入中文')
booleanParam(name: 'YESORNO', defaultValue: true, description: '是否发布')
}
stages{
stage('test stage')
{
agent
{
label 'master'
}
steps
{
echo 'Hello, stage1'
echo "Hello ${params.PERSON}"
echo "Hello ${env.PERSON}"
scrip
{
def input = params.YESORNO
if (input)
{
echo "you input is ${input},to do sth"
}
else
{
echo "you input is ${input},nothing to do"
}
}
}
}
}
环境变量的问题
通过Jenkins 执行相关sh的时候,环境变量中,不会默认继承/etc/profile 和 ~/.profile 等环境变量。
这个时候就很麻烦了,尤其在一些依赖环境变量操作的sh脚本时。
可以这样来做,一是在增加node节点时,自己设置环境变量,如:
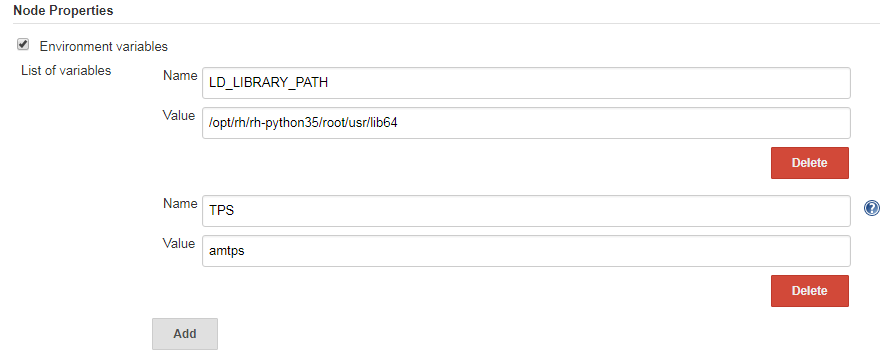
也可以在代码中这么写。写 withEnv ,或是直接在shell中先source profile文件。然后在执行相关命令。
steps
{
withEnv(['TPS=amtps']) {
// do sth
}
//
sh 'source /etc/profile && source ~/.bash_profile && env'
dir('/root')
{
sh '(source /etc/profile;source ~/.bash_profile;sh ./ee.sh)'
}
}
Jenkins中nohup后进程还是起不来的问题
在普通的shell环境中,nohup,并且& 某个程序后,会抛到后台执行,在退出当前shell环境后,程序依然可以执行。
但是在Jenkins中,通过nohup,且使用&之后,step结束后,执行的程序还是会退出,导致程序起不来。
尝试和验证了很多方法,后面都是这样解决的。
修改JENKINS_NODE_COOKIE的值,这样后续结束的时候,后面的sh程序就不会被kill掉了。
适用版本:Jenkins 2.46版本,版本如差异较大,可能不一致。当时为了解决这个问题,折腾了很久,找的资料也比较老了,很多都没用,特定记录一下。
steps
{
sh 'JENKINS_NODE_COOKIE=dontKillMe nohup python3 /home/among/pj/my_py/monitor/amon/amon.py >/tmp/run.log 2>&1 &'
}
shell出错后继续,取shell输出值。
这2个比较简单,看例子就知道了。
steps
{
sh returnStatus: true, script: "ps -ef|grep amon|grep -v grep|awk '{print \$2}'|xargs kill -9"
script
{
def pid = sh returnStdout: true ,script: "ps -ef|grep amon|grep -v grep|awk '{print \$2}'"
pid = pid.trim()
echo "you input pid is ${pid},to do sth"
sh "kill -9 ${pid}"
} }
以上就是最近遇到的一些问题,后续遇到了,我再补充吧。
一些地方有可能存在问题或有更好的解决方法,欢迎大家提出和完善。
[转] Jenkins pipeline 踩坑集合的更多相关文章
- 微信小程序踩坑集合
1:官方工具:https://mp.weixin.qq.com/debug/w ... tml?t=1476434678461 2:简易教程:https://mp.weixin.qq.com/debu ...
- hadoop之mapReduce踩坑集合
居然没有把这个目录,之前还想爆粗口的,还是算了. 上苷酸菜: 1.对于mapreduce中FileInputFormat只输入input文件根目录的方法尝试. 很简单好吧: step1: FileIn ...
- python2 => python3 踩坑集合
报错内容: ModuleNotFoundError: No module named 'md5' 解析: 这是 python2 的库,python3 已经把它包含进 hashlib 库里了 解决方法 ...
- fibos开发踩坑集合
fibos.js API资料: 与eosjs相比,fibos.js没有添加新功能,可以在eosjs项目页面https://developers.eos.io/eosio-nodeos/referenc ...
- Vue3.x+element-plus+ts踩坑笔记
闲聊 前段时间小颖在B站找了个学习vue3+TS的视频,自己尝试着搭建了一些基础代码,在实现功能的过程中遇到了一些问题,为了防止自己遗忘,写个随笔记录一下嘻嘻 项目代码 git地址:vue3.x-ts ...
- 新书推荐《再也不踩坑的Kubernetes实战指南》
<再也不踩坑的Kubernetes实战指南>终于出版啦.目前可以在京东.天猫购买,京东自营和当当网预计一个星期左右上架. 本书贴合生产环境经验,解决在初次使用或者是构建集群中的痛点,帮 ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- spring-boot-starter-amqp踩坑记
踩坑记录 近日在用spring boot架构一个微服务框架,服务发现与治理.发布REST接口各种轻松惬意.但是服务当设计MQ入口时,就发现遇到无数地雷,现在整理成下文,供各路大侠围观与嘲笑. 版本 当 ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
随机推荐
- 开发工具Visual Studio使用相关知识和经验的碎片化记录
开发工具Visual Studio使用相关知识和经验的碎片化记录 1.Visual Studio提示"无法启动IIS Express Web服务器"的解决方法 有时,在使用Visu ...
- Spring 事务不回滚
为了打印清楚日志,很多方法我都加tyr catch,在catch中打印日志.但是这边情况来了,当这个方法异常时候 日志是打印了,但是加的事务却没有回滚. 例: 类似这样的方法不会回滚 (一个方 ...
- OpenCV实现均值哈希
总共分三步:压缩,灰度化,均值化,求哈希值. 1.压缩 void secondMethod(char* filename, char* savename) { //const char* filena ...
- scalaWindows和Linux搭建
Windows搭建 https://www.cnblogs.com/freeweb/p/5623372.html Linux搭建 https://www.cnblogs.com/freeweb/p/5 ...
- [Erlang11] 那些经历过的Erlang小坑11-20
11.每次重装系统时都会重新安装Erlang,Ubuntu安装sh秒杀一切. https://gist.github.com/zhongwencool/11174620 12. Erlang Shel ...
- CDC--Demo
--CDC通过对事务日志的异步读取,记录DML操作的发生时间.--类型和实际影响的数据变化,然后将这些数据记录到启用--CDC时自动创建的表中.通过cdc相关的存储过程,可以获--取详细的数据变化情况 ...
- Nginx使用
1. 基本使用 分linux和windows版 windows版可以直接双击exe运行,默认配置为80端口,只有两个页面 html目录下为页面.css.js等代码文件 conf目录下为配置文件 主要的 ...
- 跨DLL操作fopen的返回值导致出错
在设置成/MD或/MDd不会导致出错 设置成/MT或/MTd的情况下会导致出错 看了CRT的实现,估计是因为fopen创建了CriticalSection来保护文件,但是在/MT的情况下,一个DLL里 ...
- MongoDB高级知识
MongoDB高级知识 一.mongodb适合场景: 1.读写分离:MongoDB服务采用三节点副本集的高可用架构,三个数据节点位于不同的物理服务器上,自动同步数据.Primary和Secondary ...
- codeforces|CF13C Sequence
大概的题意就是每次可以对一个数加一或者减一,然后用最小的代价使得原序列变成不下降的序列. 因为是最小的代价,所以到最后的序列中的每个数字肯定在原先的序列中出现过.(大家可以想一下到底是为什么,或者简单 ...