ItemCF_基于物品的协同过滤
ItemCF_基于物品的协同过滤
1. 概念

2. 原理
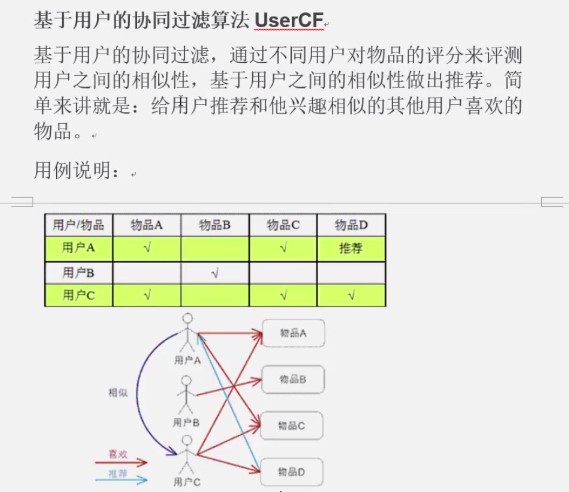
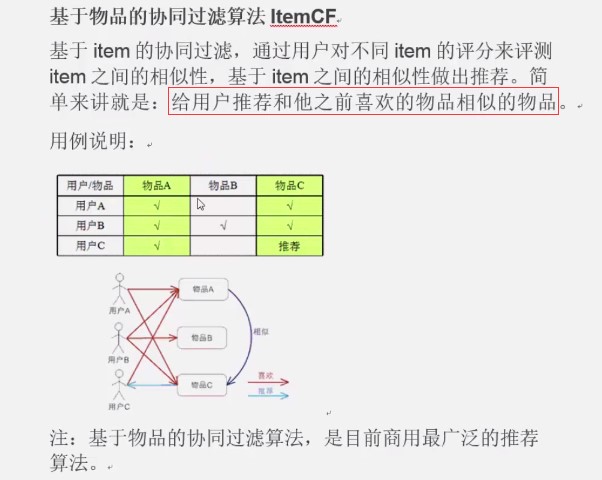
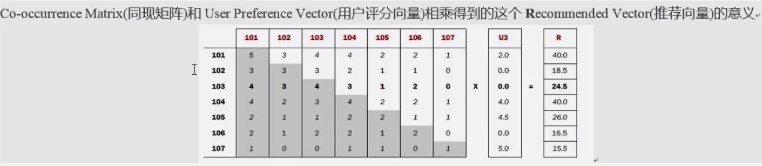

3. java代码实现思路
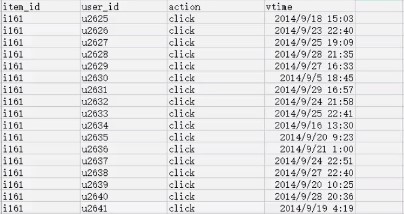
六个MapReduce



ItemCF_基于物品的协同过滤的更多相关文章
- ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
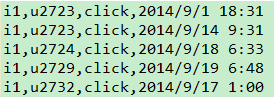
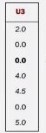
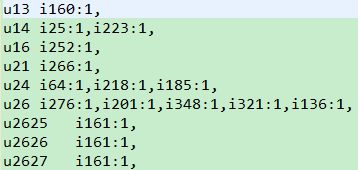
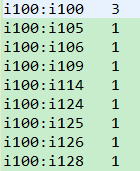
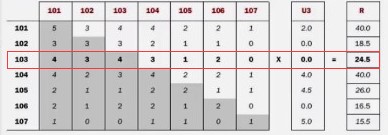
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- 基础系列(5)—— C#控制语句
语句是程序中最小程序指令.C#语言中可以使用多种类型的语句,每一种类型的语句又可以通过多个关键字实现.以下是C# 语言中使用的主要控制语句 类别 关键字 选择语句 if.else.switch.ca ...
- Spring学习(四)—— java动态代理(JDK和cglib)
JAVA的动态代理 代理模式 代理模式是常用的java设计模式,他 的特征是代理类与委托类有同样的接口,代理类主要负责为委托类预处理消息.过滤消息.把消息转发给委托类,以及事后处理消息等.代理类与委托 ...
- HTML5 <meta> 标签属性,所有meta用法
基本标签 声明文档使用的字符编码:<meta charset="utf-8" /> 声明文档的兼容模式:<meta http-equiv="X-UA-C ...
- lintcode-107-单词切分
107-单词切分 给出一个字符串s和一个词典,判断字符串s是否可以被空格切分成一个或多个出现在字典中的单词. 样例 给出 s = "lintcode" dict = [" ...
- linux普通用户被内存被限制的问题
把应用从root用户迁移到普通用户test,由于普通用户会被限制最大的进程数,当进程数占满后出现了下面的错误 /bin/bash: Resource temporarily unavailable. ...
- dom变成jquery对象 先获取dom对象 然后通过$()转换成jquery对象
dom变成jquery对象 先获取dom对象 然后通过$()转换成jquery对象
- 【JavaScript】checkBox的多选行<tr>信息获取
页面的列表table显示(后台model.addAttribute("page", page);传来page信息,page通过foreach标签迭代展示表格数据): <!-- ...
- HttpHelper类及调用
首先列出HttpHelper类 /// <summary> /// Http操作类 /// </summary> public class HttpHelper { priva ...
- spring的事务传播特性
PROPAGATION_REQUIRED(常用) Support a current transaction; create a new one if none exists. 支持一个当前事务;如 ...
- 洛谷 P2498 [SDOI2012]拯救小云公主 解题报告
P2498 [SDOI2012]拯救小云公主 题目描述 英雄又即将踏上拯救公主的道路-- 这次的拯救目标是--爱和正义的小云公主. 英雄来到\(boss\)的洞穴门口,他一下子就懵了,因为面前不只是一 ...