Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka
1.概述
前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据。下面是今天要分享的目录:
- 数据来源
- Flume到Kafka
- 数据源加载
- 预览
下面开始今天的分享内容。
2.数据来源
Kafka生产的数据,是由Flume的Sink提供的,这里我们需要用到Flume集群,通过Flume集群将Agent的日志收集分发到 Kafka(供实时计算处理)和HDFS(离线计算处理)。关于Flume集群的Agent部署,这里就不多做赘述了,不清楚的同学可以参考《高可用Hadoop平台-Flume NG实战图解篇》一文中的介绍,下面给大家介绍数据来源的流程图,如下图所示:

这里,我们使用Flume作为日志收集系统,将收集到的数据输送到Kafka中间件,以供Storm去实时消费计算,整个流程从各个Web节点 上,通过Flume的Agent代理收集日志,然后汇总到Flume集群,在由Flume的Sink将日志输送到Kafka集群,完成数据的生产流程。
3.Flume到Kafka
从图,我们已经清楚了数据生产的流程,下面我们来看看如何实现Flume到Kafka的输送过程,下面我用一个简要的图来说明,如下图所示:

这个表达了从Flume到Kafka的输送工程,下面我们来看看如何实现这部分。
首先,在我们完成这部分流程时,需要我们将Flume集群和Kafka集群都部署完成,在完成部署相关集群后,我们来配置Flume的Sink数据流向,配置信息如下所示:
- 首先是配置spooldir方式,内容如下所示:
producer.sources.s.type = spooldir
producer.sources.s.spoolDir = /home/hadoop/dir/logdfs
- 当然,Flume的数据发送方类型也是多种类型的,有:Console、Text、HDFS、RPC等,这里我们系统所使用的是Kafka中间件来接收,配置内容如下所示:

producer.sinks.r.type = org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=dn1:9092,dn2:9092,dn3:9092
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
这样,我们就在Flume的Sink端配置好了数据流向接受方。
4.数据加载
在完成配置后,接下来我们开始加载数据,首先我们在Flume的spooldir端生产日志,以供Flume去收集这些日志。然后,我们通过Kafka的KafkaOffsetMonitor监控工具,去监控数据生产的情况,下面我们开始加载。
- 启动ZK集群,内容如下所示:
zkServer.sh start
注意:分别在ZK的节点上启动。
- 启动Kafka集群
kafka-server-start.sh config/server.properties &
在其他的Kafka节点输入同样的命令,完成启动。
- 启动Kafka监控工具
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk dn1:2181,dn2:2181,dn3:2181 \
--port 8089 \
--refresh 10.seconds \
--retain 1.days
- 启动Flume集群
flume-ng agent -n producer -c conf -f flume-kafka-sink.properties -Dflume.root.logger=ERROR,console
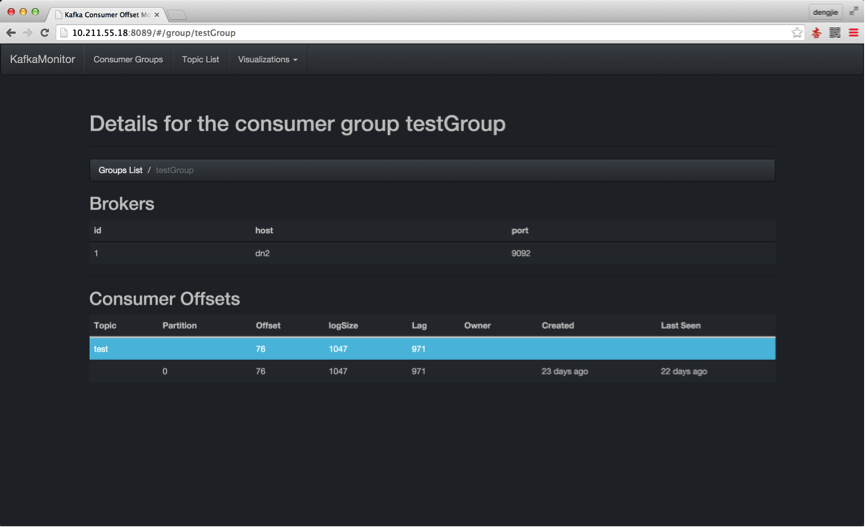
然后,我在/home/hadoop/dir/logdfs目录下上传log日志,这里我只抽取了一少部分日志进行上传,如下图所示,表示日志上传成功。

5.预览
下面,我们通过Kafka的监控工具,来预览我们上传的日志记录,有没有在Kafka中产生消息数据,如下所示:
- 启动Kafka集群,为生产消息截图预览

- 通过Flume上传日志,在Kafka中产生消息数据
6.总结
本篇文章给大家讲述了Kafka的消息产生流程,后续会在Kafka实战系列中为大家讲述Kafka的消息消费流程等一整套流程,这里只是为后续的Kafka实战编码打下一个基础,让大家先对Kafka的消息生产有个整体的认识。
Kafka实战-Flume到Kafka (转)的更多相关文章
- 【Kafka】Flume整合Kafka
目录 需求 一.Flume下载地址 二.上传解压Flume 三.配置flume.conf 四.启动flume 五.测试整合 需求 实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafk ...
- Kafka实战宝典:Kafka的控制器controller详解
一.控制器简介 控制器组件(Controller),是 Apache Kafka 的核心组件.它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群.集群中任意一 ...
- Flume 与Kafka区别
今天开会讨论日志处理为什么要同时使用Flume和Kafka,是否可以只用Kafka 不使用Flume?当时想到的就只用Flume的接口多,不管是输入接口(socket 和 文件)以及输出接口(Kafk ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- Kafka实战-数据持久化
1.概述 经过前面Kafka实战系列的学习,我们通过学习<Kafka实战-入门>了解Kafka的应用场景和基本原理,<Kafka实战-Kafka Cluster>一文给大家分享 ...
- Kafka实战-Kafka到Storm
1.概述 在<Kafka实战-Flume到Kafka>一文中给大家分享了Kafka的数据源生产,今天为大家介绍如何去实时消费Kafka中的数据.这里使用实时计算的模型——Storm.下面是 ...
随机推荐
- Netty性能调优
1. 减少内存allocation和deallocation.通过静态实例和内存缓存,减少IO的次数. 2. 使用gather write和scatter read 3. 使用jDK7,因为他的byt ...
- 给你一个 5L 和 3L 桶,水无限多,怎么到出 4L。
智力题 给你一个 5L 和 3L 桶,水无限多,怎么到出 4L. 思考过程 先将 3L 的桶装满水,倒入 5L 的桶里. 再重新将 3L 的桶装满水,倒入 5L 的桶里,把 5 L 的桶装满后,这样 ...
- docker-compose RabbitMQ与Nodejs接收端同时运行时的错误
首先讲一下背景: 我现在在开发的一个项目,需要运行RabbitMQ和Nodejs接收端(amqplib库),但是在Nodejs接收端运行时,无法连接至RabbitMQ端,经常提示说 connect E ...
- VideoView视频缓冲进度条
效果图: 需求: 刚进入视频播放页时,屏幕中间有加载进度条 视频播放过程中,视频界面不动了,正在缓冲时,屏幕中间有加载进度条 private ObjectAnimator rotate; ImageV ...
- file.listFiles()按文件大小、名称、日期排序方法
原文地址:http://blog.csdn.net/dezhihuang/article/details/53287602 按照文件大小排序 public static void orderByLen ...
- mybatis基础之二
UserMapper.xml <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper ...
- RxSwift 系列(九)
前言 看完本系列前面几篇之后,估计大家也还是有点懵逼,本系列前八篇也都是参考RxSwift官方文档和一些概念做的解读.上几篇文章概念性的东西有点多,一时也是很难全部记住,大家脑子里面知道有这么个概念就 ...
- JZYZOJ1330 土地购买 dp 斜率优化
不用long long的话只能ac一半的点而且完全查不出来错...放弃cin保平安.. x[i],y[i]分别为第i块土地的长和宽,输入后需要排序然后去掉冗余数据,最后得到的x[i]递增y[i]递 ...
- [HAOI2015]数组游戏
题目大意: 有一排n个格子,每个格子上都有一个白子或黑子,在上面进行游戏,规则如下: 选择一个含白子的格子x,并选择一个数k,翻转x,2x,...,kx格子上的子. 不能操作者负. 思路: 将“某个格 ...
- Shell脚本:“syntax error:unexpected end of file”
这种错误只能说是坑,如果没有见到过,很可能就要摔里头.解决问题是重要的,但弄明白问题的来源,往往更为重要. 所以要先扯一下,换行和回车的历史遗留问题. 在计算机出现之前,有个玩意叫电传打字机.每秒钟可 ...