Flink 靠什么征服饿了么工程师?
- Flink 靠什么征服饿了么工程师?
2018-08-13 易伟平

阿里妹导读:本文将为大家展示饿了么大数据平台在实时计算方面所做的工作,以及计算引擎的演变之路,你可以借此了解Storm、Spark、Flink的优缺点。如何选择一个合适的实时计算引擎?Flink凭借何种优势成为饿了么首选?本文将带你一一解开谜题。
平台现状
下面是目前饿了么平台现状架构图:
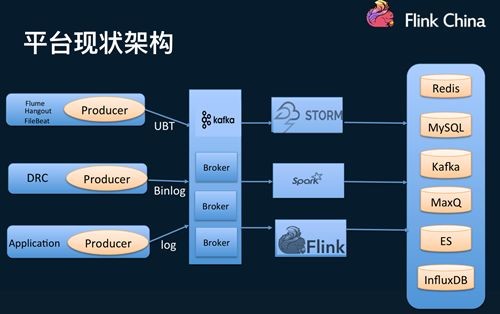
来源于多个数据源的数据写到kafka里,计算引擎主要是Storm,Spark和Flink,计算引擎出来的结果数据再落地到各种存储上。
目前Storm任务大概有100多个,Spark任务有50个左右,Flink暂时还比较少。
目前我们集群规模每天数据量有60TB,计算次数有1000000000,节点有400个。这里要提一下,Spark和Flink都是on yarn的,其中Flink onyarn主要是用作任务间jobmanager隔离, Storm是standalone模式。
应用场景
1.一致性语义
在讲述我们应用场景之前,先强调实时计算一个重要概念, 一致性语义:
1) at-most-once:即fire and forget,我们通常写一个java的应用,不去考虑源头的offset管理,也不去考虑下游的幂等性的话,就是简单的at-most-once,数据来了,不管中间状态怎样,写数据的状态怎样,也没有ack机制。
2) at-least-once: 重发机制,重发数据保证每条数据至少处理一次。
3) exactly-once: 使用粗Checkpoint粒度控制来实现exactly-once,我们讲的exactly-once大多数指计算引擎内的exactly-once,即每一步的operator内部的状态是否可以重放;上一次的job如果挂了,能否从上一次的状态顺利恢复,没有涉及到输出到sink的幂等性概念。
4) at-least-one + idempotent = exactly-one:如果我们能保证说下游有幂等性的操作,比如基于mysql实现 update on duplicate key;或者你用es, cassandra之类的话,可以通过主键key去实现upset的语义, 保证at-least-once的同时,再加上幂等性就是exactly-once。
2. Storm
饿了么早期都是使用Storm,16年之前还是Storm,17年才开始有Sparkstreaming, Structed-streaming。Storm用的比较早,主要有下面几个概念:
1) 数据是tuple-based
2) 毫秒级延迟
3) 主要支持java, 现在利用apache beam也支持python和go。
4) Sql的功能还不完备,我们自己内部封装了typhon,用户只需要扩展我们的一些接口,就可以使用很多主要的功能;flux是Storm的一个比较好的工具,只需要写一个yaml文件,就可以描述一个Storm任务,某种程度上说满足了一些需求,但还是要求用户是会写java的工程师,数据分析师就使用不了。
★ 2.1 总结
1) 易用性:因为使用门槛高,从而限制了它的推广。
2)StateBackend:更多的需要外部存储,比如redis之类的kv存储。
3) 资源分配方面:用worker和slot提前设定的方式,另外由于优化点做的较少,引擎吞吐量相对比较低一点。
3. Sparkstreaming
有一天有个业务方过来提需求说 我们能不能写个sql,几分钟内就可以发布一个实时计算任务。 于是我们开始做Sparkstreaming。它的主要概念如下:
1) Micro-batch:需要提前设定一个窗口,然后在窗口内处理数据。
2) 延迟是秒级级别,比较好的情况是500ms左右。
3) 开发语言是java和scala。
4)streaming SQL,主要是我们的工作,我们希望提供streaming SQL的平台。
特点:
1) Spark生态和SparkSQL: 这是Spark比较好的地方,技术栈是统一的,SQL,图计算,machine learning的包都是可以互调的。因为它先做的是批处理,和Flink不一样,所以它天然的实时和离线的api是统一的。
2) Checkpointon hdfs。
3) onyarn:Spark是属于hadoop生态体系,和yarn集成度高。
4) 高吞吐: 因为它是Micro-batch的方式,吞吐也是比较高的。
下面给大家大致展示一下我们平台用户快速发布一个实时任务的操作页面,它需要哪些步骤。我们这里不是写DDL和DML语句,而是ui展示页面的方式。
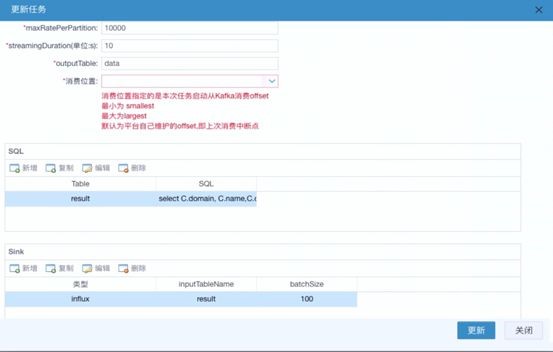
页面里面会让用户选一些必要的参数, 首先会选哪一个kafka集群,每个分区消费多少,反压也是默认开启的。消费位置需要让用户每次去指定,有可能用户下一次重写实时任务的时候,可以根据业务需求去选择offset消费点。
中间就是让用户描述pipeline。 SQL就是kafka的多个topic,输出选择一个输出表,SQL把上面消费的kafka DStream注册成表,然后写一串pipeline,最后我们帮用户封装了一些对外sink(刚刚提到的各种存储都支持,如果存储能实现upsert语义的话,我们都是支持了的)。
★ 3.1 MultiStream-Join
虽然刚刚满足一般无状态批次内的计算要求,但就有用户想说, 我想做流的join怎么办, 早期的Spark1.5可以参考Spark-streamingsql这个开源项目把 DStream注册为一个表,然后对这个表做join的操作,但这只支持1.5之前的版本,Spark2.0推出structured streaming之后项目就废弃了。我们有一个tricky的方式:
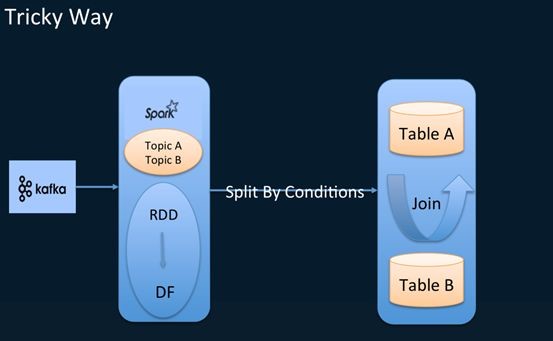
让Sparkstreaming去消费多个topic,但是我根据一些条件把消费的DStream里面的每个批次RDD转化为DataFrame,这样就可以注册为一张表,根据特定的条件,切分为两张表,就可以简单的做个join,这个join的问题完全依赖于本次消费的数据,它们join的条件是不可控的,是比较tricky的方式。比如说下面这个例子,消费两个topic,然后简单通过filer条件,拆成两个表,然后就可以做个两张表的join,但它本质是一个流。

★ 3.2 Exactly-once

exactly-once需要特别注意一个点:
我们必须要求数据sink到外部存储后,offset才能commit,不管是到zk,还是mysql里面,你最好保证它在一个transaction里面,而且必须在输出到外部存储(这里最好保证一个upsert语义,根据unique key来实现upset语义)之后,然后这边源头driver再根据存储的offeset去产生kafka RDD,executor再根据kafka每个分区的offset去消费数据。如果满足这些条件,就可以实现端到端的exactly-once. 这是一个大前提。
★ 3.3 总结
1) Stateful Processing SQL ( <2.x mapWithState、updateStateByKey):我们要实现跨批次带状态的计算的话,在1.X版本,我们通过这两个接口去做,但还是需要把这个状态存到hdfs或者外部去,实现起来比较麻烦一点。
2) Real Multi-Stream Join:没办法实现真正的多个流join的语义。
3)End-To-End Exactly-Once Semantics:它的端到端的exactly-once语义实现起来比较麻烦,需要sink到外部存储后还需要手动的在事务里面提交offset。
4. STRUCTUREDSTREAMING
我们调研然后并去使用了Spark2.X之后带状态的增量计算。下面这个图是官方网站的:
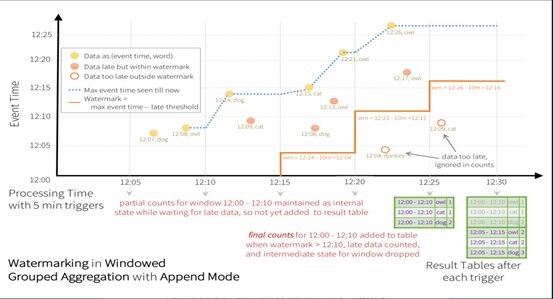
所有的流计算都参照了Google的 data flow,里面有个重要的概念:数据的processing time和event time,即数据的处理时间和真正的发生时间有个gap。于是流计算领域还有个watermark,当前进来的事件水位需要watermark来维持,watermark可以指定时间delay的范围,在延迟窗口之外的数据是可以丢弃的,在业务上晚到的数据也是没有意义的。
下面是structuredstreaming的架构图:
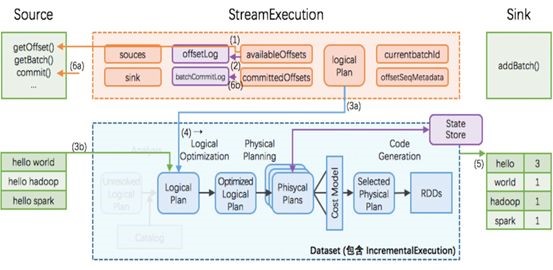
这里面就是把刚才Sparkstreaming讲exactly-once的步骤1,2,3都实现了,它本质上还是分批的batch方式,offset自己维护,状态存储用的hdfs,对外的sink没有做类似的幂等操作,也没有写完之后再去commit offset,它只是再保证容错的同时去实现内部引擎的exactly-once。
★ 4.1 特点
1) Stateful Processing SQL&DSL:可以满足带状态的流计算
2) Real Multi-Stream Join:可以通过Spark2.3实现多个流的join,多个流的join做法和Flink类似,你需要先定义两个流的条件(主要是时间作为一个条件),比如说有两个topic的流进来,然后你希望通过某一个具体的schema中某个字段(通常是event time)来限定需要buffer的数据,这样可以实现真正意义上的流的join。
3)比较容易实现端到端的exactly-once的语义,只需要扩展sink的接口支持幂等操作是可以实现exactly-once的。
特别说一下,Structuredstreaming和原生的streaming的api有一点区别,它create表的Dataframe的时候,是需要指定表的schema的,意味着你需要提前指定schema。另外它的watermark是不支持SQL的,于是我们加了一个扩展,实现完全写sql,可以从左边到右边的转换(下图),我们希望用户不止是程序员,也希望不会写程序的数据分析师等同学也能用到。

★ 4.2 总结
1) Trigger(Processing Time、 Continuous ):2.3之前主要基于processing Time,每个批次的数据处理完了立马触发下一批次的计算。2.3推出了record by record的持续处理的trigger。
2)Continuous Processing (Only Map-Like Operations):目前它只支持map like的操作,同时sql的支持度也有些限制。
3) LowEnd-To-End Latency With Exactly-Once Guarantees:端到端的exactly-once的保证需要自己做一些额外的扩展, 我们发现kafka0.11版本提供了事务的功能,是可以从基于这方面考虑从而去实现从source到引擎再到sink,真正意义上的端到端的exactly-once。
4) CEP(Drools):我们发现有业务方需要提供cep 这样复杂事件处理的功能,目前我们的语法无法直接支持,我们让用户使用规则引擎Drools,然后跑在每个executor上面,依靠规则引擎功能去实现cep。
于是基于以上几个Spark structuredstreaming的特点和缺点,我们考虑使用Flink来做这些事情。
5.Flink
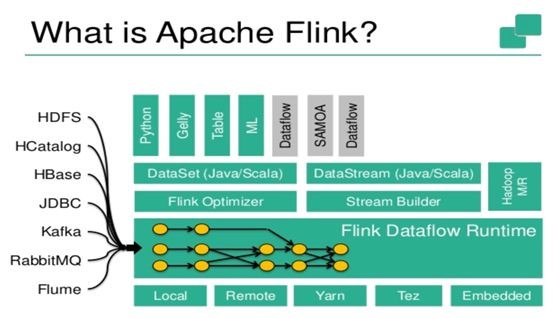
Flink目标是对标Spark,流这块是领先比较多,它野心也比较大,图计算,机器学习等它都有,底层也是支持yarn,tez等。对于社区用的比较多的存储,Flink社区官方都支持比较好,相对来说。
Flink的框架图:
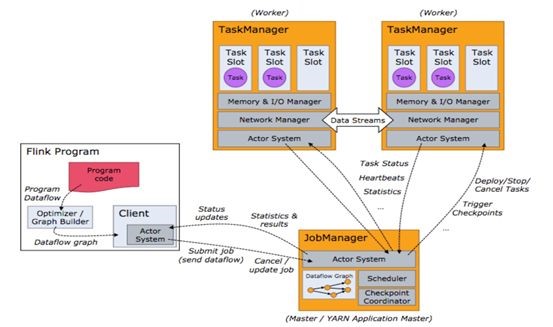
Flink中的JobManager,相当于Spark的driver角色,taskManger相当于executor,里面的task也有点类似Spark的那些task。 不过Flink用的rpc是akka,同时Flink core自定义了内存序列化框架,另外task无需像Spark每个stage的task必须相互等待而是处理完后即往下游发送数据。
Flink binary data处理operator:
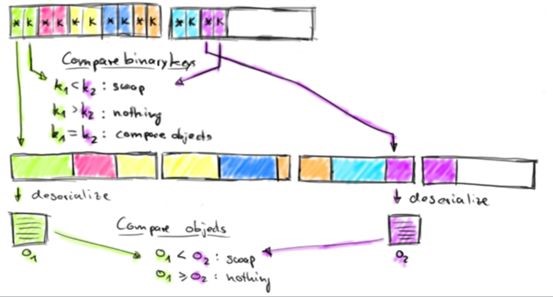
Spark的序列化用户一般会使用kryo或者java默认的序列化,同时也有Tungsten项目对Spark程序做一jvm层面以及代码生成方面的优化。相对于Spark,Flink自己实现了基于内存的序列化框架,里面维护着key和pointer的概念,它的key是连续存储,在cpu层面会做一些优化,cache miss概率极低。比较和排序的时候不需要比较真正的数据,先通过这个key比较,只有当它相等的时候,才会从内存中把这个数据反序列化出来,再去对比具体的数据,这是个不错的性能优化点。
Flink task chain:
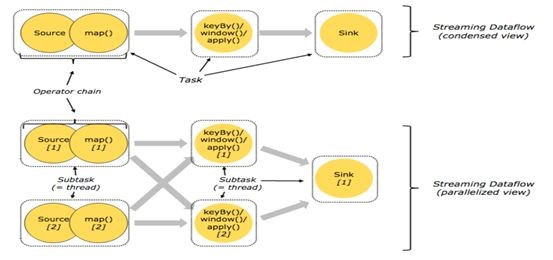
Task中operatorchain,是比较好的概念。如果上下游数据分布不需要重新shuffle的话,比如图中source是kafka source,后面跟的map只是一个简单的数据filter,我们把它放在一个线程里面,就可以减少线程上下文切换的代价。
并行度概念
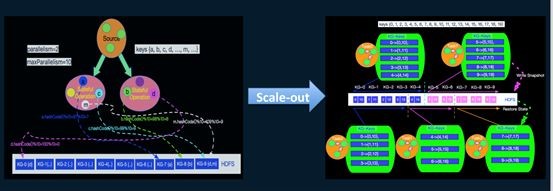
比如说这里面会有5个task,就会有几个并发线程去跑,chain起来的话放在一个线程去跑就可以提升数据传输性能。Spark是黑盒的,每个operator无法设并发度,而Flink可以对每个operator设并发度,这样可以更灵活一点,作业运行起来对资源利用率也更高一点。
Spark 一般通过Spark.default.parallelism来调整并行度,有shuffle操作的话,并行度一般是通Spark.sql.shuffle.partitions参数来调整,实时计算的话其实应该调小一点,比如我们生产中和kafka的partition数调的差不多,batch在生产上会调得大一点,我们设为1000,左边的图我们设并发度为2,最大是10,这样首先分2个并发去跑,另外根据key做一个分组的概念,最大分为10组,就可以做到把数据尽量的打散。
State & Checkpoint
因为Flink的数据是一条条过来处理,所以Flink中的每条数据处理完了立马发给下游,而不像spark,需要等该operator所在的stage所有的task都完成了再往下发。
Flink有粗粒度的checkpoint机制,以非常小的代价为每个元素赋予一个snapshot概念,只有当属于本次snapshot的所有数据都进来后才会触发计算,计算完后,才把buffer数据往下发,目前Flink sql没有提供控制buffer timeout的接口,即我的数据要buffer多久才往下发。可以在构建Flink context时,指定buffer timeout为0,处理完的数据才会立马发下去,不需要等达到一定阈值后再往下发。
Backend默认是维护在jobmanager内存,我们更多使用的的是写到hdfs上,每个operator的状态写到rocksdb上,然后异步周期增量同步到外部存储。
容错
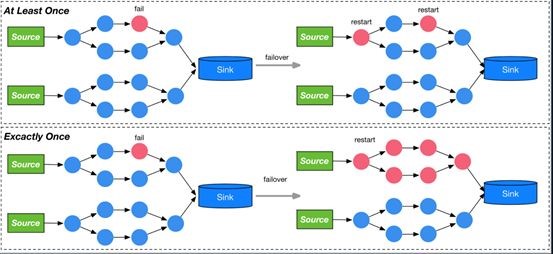
图中左半部分的红色节点发生了failover,如果是at-least-once,则其最上游把数据重发一次就好;但如果是exactly-once,则需要每个计算节点从上一次失败的时机重放。
Exactly Once Two-Phase Commit
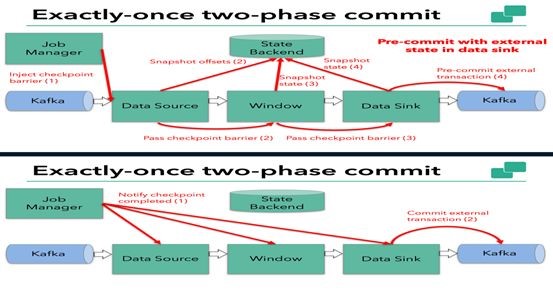
Flink1.4之后有两阶段提交来支持exactly-once.它的概念是从上游kafka消费数据后,每一步都会发起一次投票,来记录状态,通过checkpoint的屏障来处理标记,只有最后再写到kafka(0.11之后的版本),只有最后完成之后,才会把每一步的状态让jobmanager中的cordinator去通知可以固化下来,这样实现exactly-once。
Savepoints
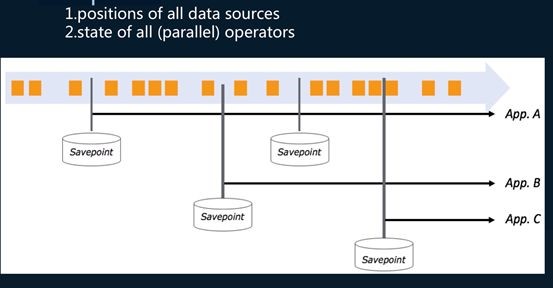
还有一点Flink比较好的就是,基于它的checkpoint来实现savepoint功能。业务方需要每个应用恢复节点不一样,希望恢复到的版本也是可以指定的,这是比较好的。这个savepoint不只是数据的恢复,也有计算状态的恢复。
特点:
1) Trigger (Processing Time、 Event Time、IngestionTime):对比下,Flink支持的流式语义更丰富,不仅支持Processing Time, 也支持Event time和Ingestion Time。
2)Continuous Processing & Window:支持纯意义上的持续处理,recordby record的,window也比Spark处理的好。
3) Low End-To-End Latency With Exactly-Once Guarantees:因为有两阶段提交,用户是可以选择在牺牲一定吞吐量的情况下,根据业务需求情况来调整来保证端到端的exactly-once。
4) CEP:支持得好。
5) Savepoints:可以根据业务的需求做一些版本控制。
也有做的还不好的:
1)SQL (Syntax Function、Parallelism):SQL功能还不是很完备,大部分用户是从hive迁移过来,Spark支持hive覆盖率达到99%以上。 SQL函数不支持,目前还无法对单个operator做并行度的设置。
2) ML、Graph等:机器学习,图计算等其他领域比Spark要弱一点,但社区也在着力持续改进这个问题。
我们期待和你一起,把Flink建设得更好,帮助更多开发者。
Flink 靠什么征服饿了么工程师?的更多相关文章
- 园子的推广博文:欢迎收看 Apache Flink 技术峰会 FFA 2021 的视频回放
园子专属收看链接:https://developer.aliyun.com/special/ffa2021/live#?utm_content=g_1000316459 Flink Forward 是 ...
- 006_饿了么大前端总监sofish帮你理清前端工程师及大前端团队的成长问题!
作者|Sofish编辑|小智 & 尾尾本文是前端之巅向 sofish 的约稿<什么样的人可以称为架构师?>.采访< 饿了么大前端团队究竟是如何落地和管理的?>以及 so ...
- 【饿了么】招聘Java开发工程师、架构师
3年以上实际工作经验,本科及以上学历. 具有良好的编程基础( 比如熟悉HTTP.多线程.Socket.JVM.基本的数据结构和算法等). 熟悉Java语言以及相关的服务器(比如Tomcat).工具(M ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 饿了么 ---Java面试
下午去饿了么参加面试,其实也满怀期待,毕竟也是个大公司. 交通:偏外环,真北路 环境:感觉压抑,不通风,面试人很多,可能是屋子高度低,不舒服. 填了资料,等待面试,两轮,真是憋屈 都是搞技术的,何苦为 ...
- CVTE 嵌入式软件工程师 二面
昨天晚上收到了二面的通知,激动啊-第二天提前20分钟到达指定地点,然后一起做大巴去到CVTE总部,发现笔试刷掉的人好像并不是很多.我们一下车被带到了公司的电影院,听演唱会.呵呵,挺有意思的,有一个漂亮 ...
- 大公司的资深工程师和小公司的Leader如何决择?
很多人在技术的道路上,都会面临选择,一个是大公司的资深工程师/技术专家,一个是小公司的leader,这个选择是一条分叉路口,是持续纵向深入发展,还是横向发展.这实际上就是个人职业规划问题. 接着往专家 ...
- 拼多多、饿了么、蚂蚁金服Java面试题大集合
自己当初找工作时参加过众多一线互联网公司的Java研发面试,这段时间处于寒冬,然而前几天跳槽找工作,两天面了3家,已经拿了两个offer,觉得可以和大家分享下: 下面为拼多多.饿了么.蚂蚁金服.哈啰出 ...
随机推荐
- android4.0 锁屏实现(转)
转载请表明出处:http://blog.csdn.net/wdaming1986/article/details/8837023 好了,言归正传,说说锁屏了,其实把锁屏做成apk的形式,会引起很多问题 ...
- cocos2dx各个版本下载地址
https://code.google.com/archive/p/cocos2d-x/downloads?page=1 各种工具包括 NDK 8 https://github.com/fusijie ...
- 将内存图像数据封装成QImage V2
转:http://www.cnblogs.com/bibei1234/p/3161555.html 如何将内存图像数据封装成QImage 当采用Qt开发相机数据采集软件时,势必会遇到采集内存图像并进行 ...
- 使用cp命令时候递归的创建目标目录
在使用cp命令拷贝文件的时候,有时候会遇到这样的场景: 源文件:/a/b/c/e.txt 目标地址:/mnt/a/b/c/e.txt 而/mnt/a/b/c这个目录结构还没有创建.拷贝的时候还要求目录 ...
- 2017-2018-1 20179202《Linux内核原理与分析》第四周作业
一.跟踪分析内核的启动过程实验 : 1.启动Menuos: qemu仿真kernel: qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd ...
- git团队开发常用命令
Git >>>>>>>>>>>> git clone <项目地址,http(s)> 把云端的项目克隆到本地 git ...
- 如果修改GeneXus Android的一些源码文件(FlexibleClient)
在使用GeneXus开发Android应用的过程中遇到了一个问题,使用tabs控件时发现默认高度过高,和UI设计要求的高度不一致,找了很久发现没有地方设置.后来联系了GeneXus中国厂商,得到了答复 ...
- Web API 自定义文件内容的定制类
public class FileContent : HttpContent { private readonly Stream _stream; public FileContent(string ...
- java getenv getProperties区别
网上很多使用的是getProperties.说获得系统变量,但是其实不正确.getProperties中所谓的"system properties"其实是指"java s ...
- 切换java版本
First, clean your project: Project > Clean If that doesn't fix things... Second check your projec ...