dom树的介绍,及原理分析
三、解析和DOM树的构建
1、解析:
由于解析渲染引擎是一个非常重要的过程,我们将会一步步的深入,现在让我们来介绍解析。
解析一个文档,意味着把它转换为一个有意义的结构——代码可以了解和使用的东西,解析 的结果通常是一个树的节点集合,用来表示文档结构,它被称为解析树或者语法树。
例子:
解析表达式“2+3-1”,返回树如下图3.1 1)、语法:
解析是基于文档所遵循的语法规则——书写所用的语言或格式——来进行的。每一种可以解析的格式必须由确定的语法与词汇组成。这被称之为上下文无关语法。 人类语言并非此种语言,所以不能用常规的解析技术来解析。 2)、解析器——分析器组合:
解析器有两个处理过程——词法分析与语法分析。
词法分析负责把输入切分成符号序列,符号是语言的词汇——由该语言所有合法的单词组成。语法分析是对该语言语法法则的应用。
解析器通常把工作分给两个组件——词法分析程序(有时被叫分词器)负责把输入切分成合法符号序列,解析器负责按照语法规则分析文档结构和构建语法树。
词法分析程序知道如何过滤像空格,换行之类的无关字符。如下图3.1.2 解析过程是迭代的。解析器通常会从词法分析器获取新符号并尝试匹配句法规则。如果匹配成功,就在句法树上创建相应的节点,并继续从词法分析器获取下一个符号。
如果没有匹配的规则,解析器会内部保存这个符号,并继续从词法分析器获取符号,直到内部保存的所有符号能够成功匹配一个规则。
如果最终无法匹配,解析器会抛出异常。这意味着文档无效,含有句法错误。 3)、转换:
多数情况下,解析树并非是最终结果,解析经常被用于转换——输入文档转换为另一种格式,比如一个编译器要把源码编译成机器码,首先会解析成解析树,然后再转换成机器码,如下图3.1.3 4)、解析示例:
在图3.1中,我们构建了一个数学表达式解析树,让我们来试着定义一个简单的数学语言并看看解析是如何进行的。
词汇:我们的语言可以包含整数、加号和减号。
语法:
1>.语法由表达式、术语和操作符组成
2>.我们的语言能包含任何数字类型的表达式
3>.表达式定义为术语紧跟着操作符,再跟另外一个术语。
4>.操作符为一个加号和一个减号
5>.术语是一个整数或者表达式
现在让我们来分析输入“2+3-1”:
第一个符合规则的子字符串是”2″,根据规则#5它是一个术语。第二个匹配是”2 + 3″,符合第二条规则——一个术语紧跟一个操作符再跟另外一个术语。下一个匹配出现在输入结束时。”2 + 3 – 1″是一个表达式,因为我们已知“2+3”是一个术语,所以符合第二条规则。 “2 + + “不会匹配任何规则,所以是无效的输入。 5)、词法与句法的合法性定义:
词汇通常用正则表达式来表示。
比如我们的语言可以定义为:
INTEGER :0|[1-9][0-9]*
PLUS : +
MINUS: -
如你所见,整型是由正则表达式定义的。
句法常用BNF格式定义,我们的语言被定义为:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
我们说过常规解析器只能解析上下文无关语法的语言。这种语言的一个直觉的定义是它的句法可以用BNF完整的表达。其规范定义请参考 http://en.wikipedia.org/wiki/Context-free_grammar 6)、解析器的类型:
解析器有两种基本类型——自上而下解析器和自下而上解析器。主观上可以认为自上而下的解析器从上层句法结构开始尝试匹配句法;自下而上的则从输入开始,慢慢转换成句法规则,从底层规则开始,直到上层规则全部匹配。
让我们看看这两种解析器将怎样解析我们的例子:
自上而下解析器从上层规则开始,它会把”2 + 3″定义为表达式,然后定义”2 + 3 – 1″为表达式(定义表达式的过程中也会匹配其它规则,但起点是最高级别规则)。
自下而上的解析器会扫描输入,直到有匹配的规则,它会把输入替换成规则。这样一直到输入结束。部分匹配的规则会放入解析堆栈。如下图:3.1.6 这种自下而上的解析器叫作移位归约解析器,因为输入被向右移动(想象一下一个指针从指向输入开始逐渐向右移动) 并逐渐归约到句法树。 7)自动创建解析器
有一些工具可以为你创建解析器,它们通常称为解析器生成器。你只需要提供语法——词汇与句法规则——它就能生成一个可以工作的解析器。创建解析器需要对解析器有深入的了解,并且手动创建一个优化的解析器并不容易,所以解析器生成工具很有用。
Webkit使用两款知名的解析器生成工具:Flex用于创建词法分析器,Bison用于创建解析器 (你也许会看到它们以Lex和Yacc的名字存在)。Flex的输入文件是符号的正则表达式定义,Bison的输入文件是BNF格式的句法定义。 2.HTML解析器:
HTML解析器的工作是解析HTML标记到解析树
1)HTML语法定义
HTML的词汇与句法定义在w3c组织创建的规范中。当前版本是HTML4,HTML5的工作正在进行中。
2)不是上下文无关语法
在对解析器的介绍中看到,语法可以用类似BNF的格式规范地定义。不幸的是所有常规解析器的讨论都不适用于HTML(我提及它们并不是为了娱乐,它们可以用于解析CSS和JavaScript)。HTML无法用解析器所需的上下文无关的语法来定义。过去HTML格式规范由DTD (Document Type Definition)来定义,但它不是一个上下文无关语法。
HTML与XML相当接近。XML有许多可用的解析器。HTML还有一个XML变种叫XHTML,那么它们主要区别在哪里呢?区别在于HTML应用更加”宽容”,它容许你漏掉一些开始或结束标签等。它整个是一个“软”句法,不像XML那样严格死板。 总的来说这一看似细微的差别造成了两个不同的世界。一方面这使得HTML很流行,因为它包容你的错误,使网页作者的生活变得轻松。另一方面,它使编写语法格式变得困难。所以综合来说,HTML解析并不简单,现成的上下文相关解析器搞不定,XML解析器也不行。
3)HTML DTD
HTML的定义使用DTD文件。这种格式用来定义SGML族语言,它包含对所有允许的元素的定义,包括它们的属性和层级关系。如我们前面所说,HTML DTD构不成上下文无关语法。
DTD有几种不同类型。严格模式完全尊守规范,但其它模式为了向前兼容可能包含对早期浏览器所用标签的支持。当前的严格模式DTD:http://www.w3.org/TR/html4/strict.dtd
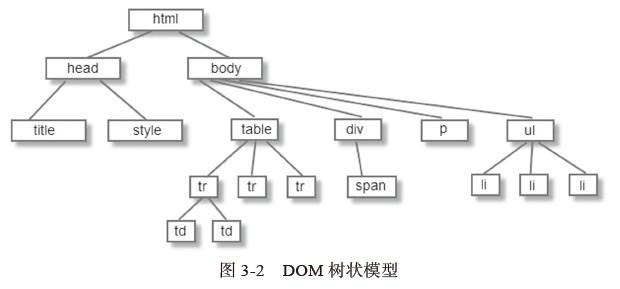
4)DOM
解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。
DOM与标签有着几乎一一对应的关系,如下:
<html>
<body>
<p>hello world</p>
<div><img src="aa.png"/></div>
</body>
</html>
其对应的DOM树如下3.2.4图:
与HTML一样,DOM规范也由w3c组织制订。参考:http://www.w3.org/DOM/DOMTR. 这是一个操作文档的通用规范。有一个专门的模块定义HTML特有元素: http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
当我们说树中包含DOM节点时,意思就是这个树是由实现了DOM接口的元素组成。这些实现包含了其它一些浏览器内部所需的属性。
dom树的介绍,及原理分析的更多相关文章
- 转载:AbstractQueuedSynchronizer的介绍和原理分析
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- AbstractQueuedSynchronizer的介绍和原理分析(转)
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- Servlet过滤器介绍之原理分析
zhangjunhd 的BLOG 写留言去学院学习发消息 加友情链接进家园 加好友 博客统计信息 51CTO博客之星 用户名:zhangjunhd 文章数:110 评论数:858 访问量:19 ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- AbstractQueuedSynchronizer的介绍和原理分析
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- 转:AbstractQueuedSynchronizer的介绍和原理分析
引自:http://ifeve.com/introduce-abstractqueuedsynchronizer/ 简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同 ...
- ConcrrentSkipListMap介绍和原理分析
一.前言: JDK为我们提供了很多Map接口的实现,使得我们可以方便地处理Key-Value的数据结构. 当我们希望快速存取<Key, Value>键值对时我们可以使用HashMap. 当 ...
- TKmybatis的框架介绍和原理分析及Mybatis新特性
tkmybatis是在mybatis框架的基础上提供了很多工具,让开发更加高效,下面来看看这个框架的基本使用,后面会对相关源码进行分析,感兴趣的同学可以看一下,挺不错的一个工具 实现对员工表的增删改查 ...
- TKmybatis的框架介绍和原理分析及Mybatis新特性演示
tkmybatis是在mybatis框架的基础上提供了很多工具,让开发更加高效,下面来看看这个框架的基本使用,后面会对相关源码进行分析,感兴趣的同学可以看一下,挺不错的一个工具 实现对员工表的增删改查 ...
随机推荐
- Redis' High Availability
Redis Sentinel is a system designed to help managing Redis instances. It performs the following thre ...
- 解决Deprecated: mysql_connect(): The mysql extension is deprecated and will be removed in the future: use mysqli or PDO instead in
php 5个版本,5.2.5.3.5.4.5.5,怕跟不上时代,新的服务器直接上5.5,但是程序出现如下错误:Deprecated: mysql_connect(): The mysql extens ...
- CentOS7.0 重置Root的密码
首先进入开启菜单,按下e键进入编辑现有的内核,如下图所示 然后滚动列表,找到ro,将它替换成rw,并加上init=/sysroot/bin/sh,最终变为如下图 然后按CTRL+X进入到单用户模式,在 ...
- LeetCode 213
House Robber II Note: This is an extension of House Robber. After robbing those houses on that stree ...
- Jersey(1.19.1) - Building URIs
A very important aspects of REST is hyperlinks, URIs, in representations that clients can use to tra ...
- 利用ExpandableListView和gridview 显示可展开折叠菜单导航
这篇随身笔带来的是结合聚合数据“菜谱大全”做的一个菜谱可折叠一级+二级列表. 先发来一些截图一睹为快吧. ExpandableListView 可用于折叠型菜单列表,其布局主要通过getGroupVi ...
- 基于asp.net的ajax分页
直接贴代码: <html> <head> <meta http-equiv="Content-Type" content="text/htm ...
- Cocos开发中性能优化工具介绍之Visual Studio内存泄漏检测工具——Visual Leak Detector
那么在Windows下有什么好的内存泄漏检测工具呢?微软提供Visual Studio开发工具本身没有什么太好的内存泄漏检测功能,我们可以使用第三方工具Visual Leak Detector(以下简 ...
- int/double/string使用
在计算机中存储数据和儿童在抽屉中存放物品很类似. 例如: 要在计算机中存一个数字50,需要两句话. int a; //将要放的物品告诉家长 a=50; //将物品放到某个抽屉中 计算机存储变量的过 ...
- Linux 锁
问题: 1.假如对某个文件加了锁/lock,但是程序退出时没有关闭锁,如果想在另外一个程序中用这个文件,如何办? 2.