scrapy-redis分布式爬取知乎问答,使用docker布置多台机器。
先上结果:
问题:
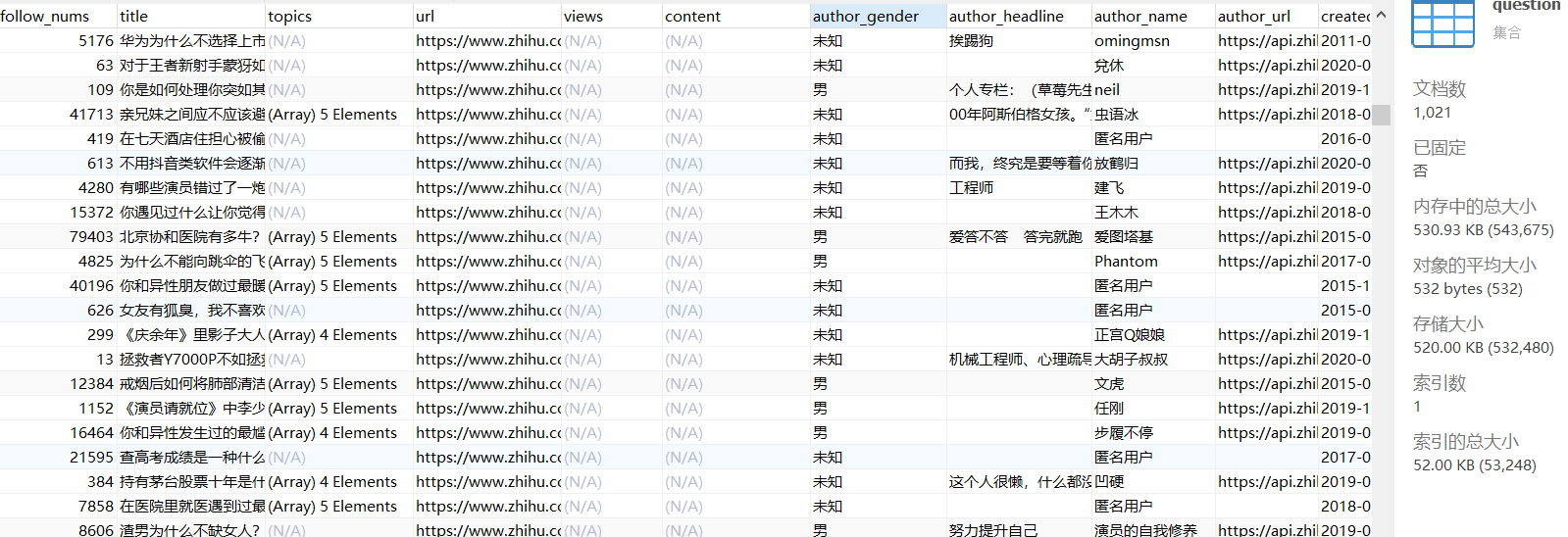
答案:
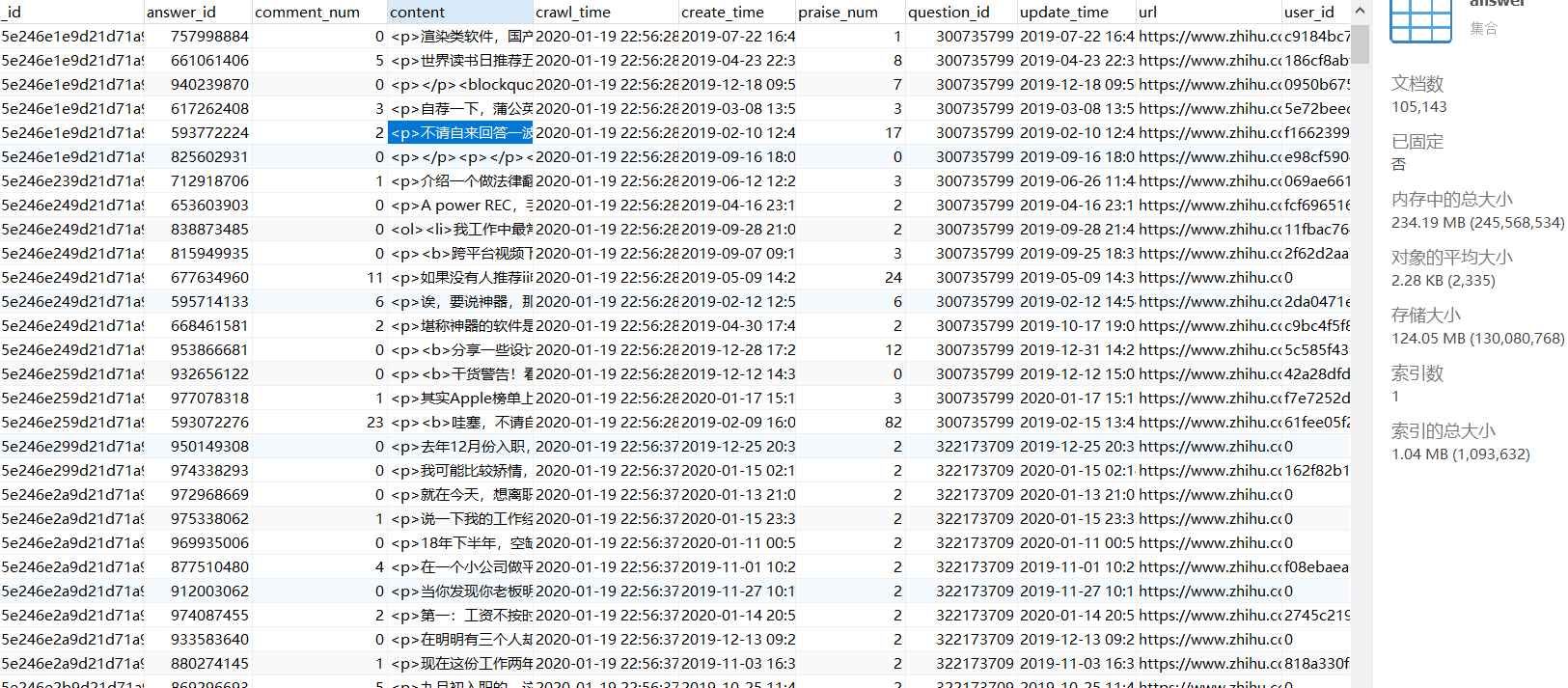
可以看到现在答案文档有十万多,十万个为什么~hh
正文开始:
分布式爬虫应该是在多台服务器(A B C服务器)布置爬虫环境,让它们重复交叉爬取,这样的话需要用到状态管理器。
状态管理器主要负责url爬取队列的管理,亦可以当爬虫服务器。同时配置好redis及scrapy-redis环境就行~
爬虫服务器主要负责数据的爬取、处理等。安装好scrapy-redis就行~
如下图:

需要多台机器同时爬取目标url并且同时从url中抽取数据,N台机器做一模一样的事,通过redis来调度、中转,也就是说它没有主机从机之分。
要明白,scrapy是不支持分布式的。
- scrapy中request是放在内存的,现在两台服务器就需要对队列进行集中管理,将request放到redis里。
- 去重也要进行集中管理,也是用到redis去重。
分布式爬虫的优点
- 充分利用多台机器的带宽速度爬取数据
- 充分利用多台机器的IP爬取
使用scrapy-redis非常简单,可以说修改scrapy项目里的settings.py的几个配置基本就行了。
pip install scrapy-redis
然后这个知乎爬取项目要从scrapy讲起:
cmd中启动一个scrapy项目:
scrapy startproject ArticleSpider
进入项目文件夹并开始一个爬虫:
cd ArticleSpider scrapy genspider zhihu www.zhihu.com
目前的项目文件:
分析知乎的问题的api:
在知乎首页每次向下拉都会触发这个ajax请求,并且返回内容是问题的url、标题等,很明显它就是问题的api了~
https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=8c3313b2932c370198480b54dc89fd3a&desktop=true&page_number=2&limit=6&action=down&after_id=5
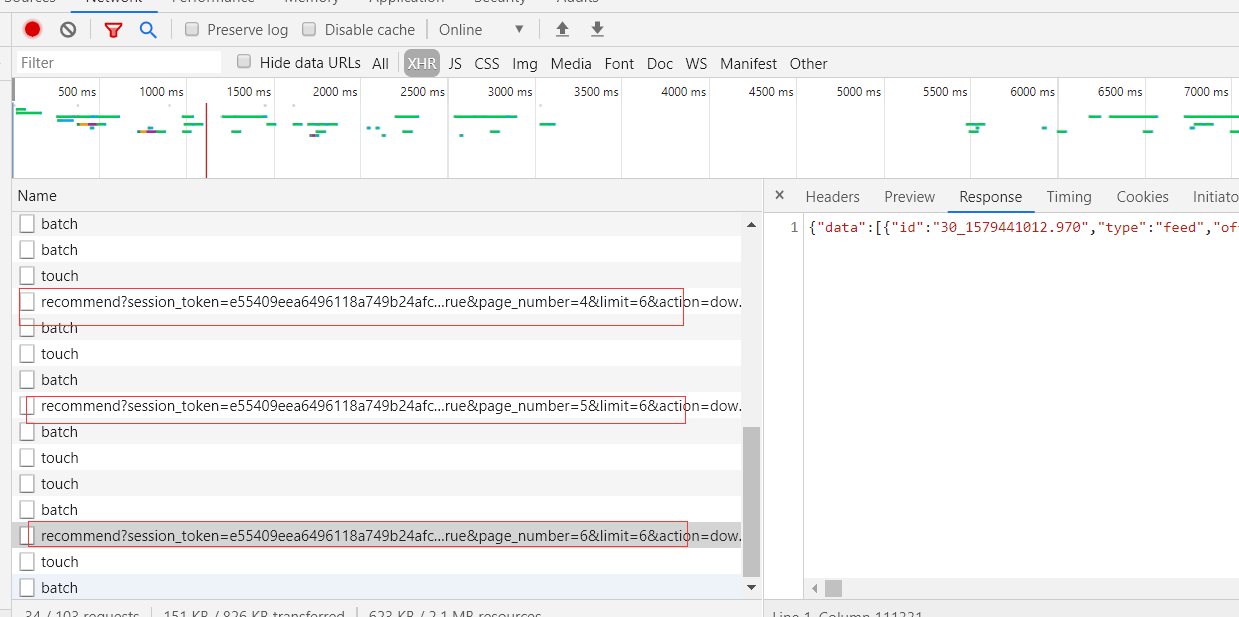
它的返回:

有趣的是每次请求它,它的response头都会返回一个set-cookie,意味着要用返回的新的cookie请求下一页的答案,否则返回错误。
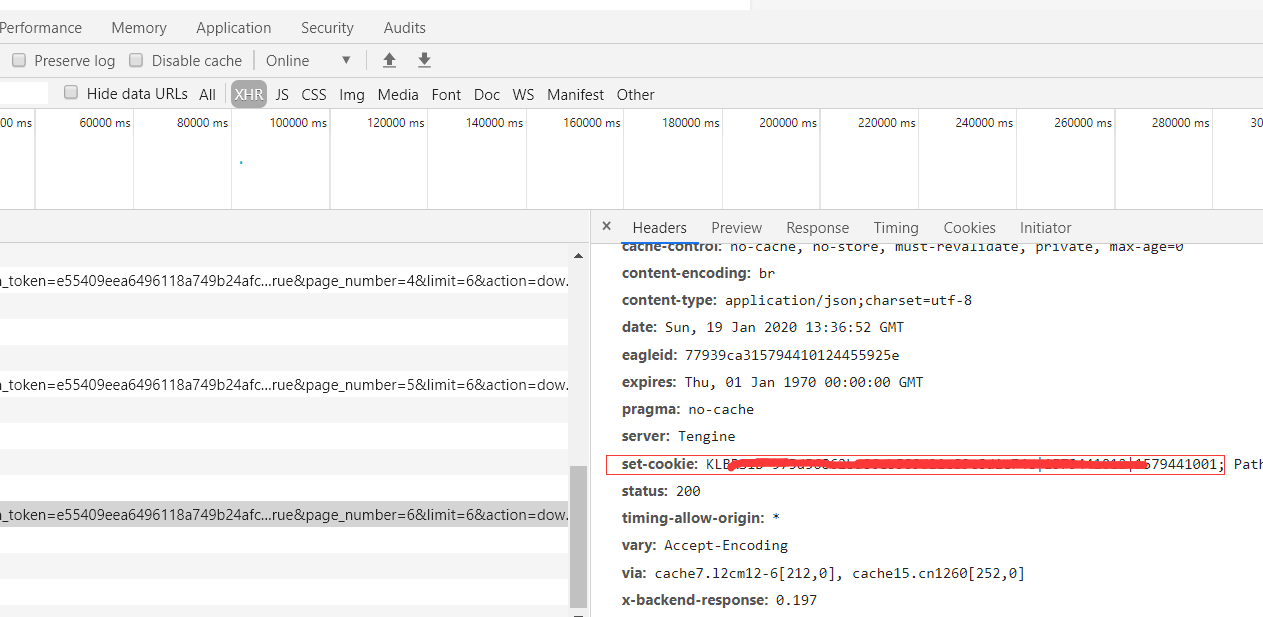
看看问题api请求头带的参数:
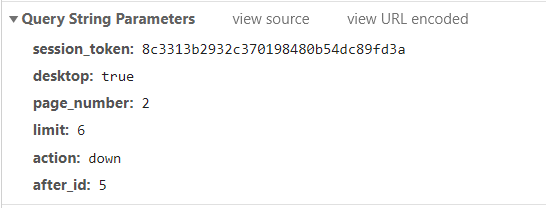
这是个get请求,其实第一条链接可以在请求首页后的html源码里找到,这样就找到了这几个参数,需要变动的只有页数page_number:
在html源码里的问题api:

我们需要先请求首页html然后以re匹配获得这条开始的问题api,然后伪造后面页数的请求。
答案api则是在往下拉所有答案时找到的:

答案api的请求更容易处理,只需要修改问题的id及offset偏移量就行,甚至不用cookie来请求。
比如这条就是某个问题的答案api:
https://www.zhihu.com/api/v4/questions/308761407/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=13&platform=desktop&sort_by=default
它的返回:

class QuestionItem(scrapy.Item):
'''
问题的item,问题和答案分两个集合保存在mongodb中
''' title = scrapy.Field()
created = scrapy.Field()
answer_num = scrapy.Field()
comment_num = scrapy.Field()
follow_nums = scrapy.Field()
question_id = scrapy.Field()
topics = scrapy.Field()
url = scrapy.Field()
author_url = scrapy.Field()
author_name = scrapy.Field()
author_headline = scrapy.Field()
author_gender = scrapy.Field()
crawl_time = scrapy.Field() class Answer_Item(scrapy.Item):
'''
答案的item
'''
answer_id = scrapy.Field()
question_id = scrapy.Field()
url = scrapy.Field()
user_name = scrapy.Field()
user_id = scrapy.Field()
content = scrapy.Field()
praise_num = scrapy.Field()
comment_num = scrapy.Field()
create_time = scrapy.Field()
update_time = scrapy.Field()
crawl_time = scrapy.Field()
然后是spider.py的修改:
# -*- coding: utf-8 -*-
import re
import time
import json
import datetime
import scrapy from ArticleSpider.items import QuestionItem, Answer_Item
from scrapy.http import Request
from scrapy_redis.spiders import RedisSpider def timestamp_2_date(timestamp):
'''
用来将时间戳转为日期时间形式
'''
time_array = time.localtime(timestamp)
my_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
return my_time def handle_cookie(response):
'''
用来处理set-cookie
'''
cookie_section = response.headers.get('set-cookie')
# 匹配cookie片段
sections = re.findall('(KLBRSID=.*?);', str(cookie_section))
print(sections)
raw_cookie = response.request.headers['Cookie'].decode('utf-8')
# 替换cookie片段到完整cookie里
cookie = re.sub('KLBRSID=.*', sections[0], raw_cookie)
return cookie class ZhihuSpider(RedisSpider):
# spider名
name = 'zhihu'
# 允许访问的域名
allowed_domains = ['www.zhihu.com']
# redis_key,到时scrapy会去redis读这个键的值,即要访问的url,原来start_url的值也是放在redis里
redis_key = 'zhihu:start_urls'
# spider的设置,在这里设置可以覆盖setting.py里的设置
custom_settings = {
# 用来设置随机延迟,最大5秒
"RANDOM_DELAY": 5,
}
# 上面这样设置好了就能使用scrapy-redis进行分布式的爬取,其他的比如parse()函数按照scrapy的逻辑设置就好
# 答案的api
answer_api = 'https://www.zhihu.com/api/v4/questions/{0}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit={1}&offset={2}&platform=desktop&sort_by=default' def parse(self, response):
'''
解析首页,获取问题api
'''
# 每次请求知乎问题api都会返回一个新的set-cookie(只是一段cookie),用来设置新的cookie。旧的cookie无法访问下一页的链接
cookie = handle_cookie(response)
print(cookie)
# 请求首页后,在首页html源码里寻找问题的api
question_api = re.findall('"previous":"(.*?)","next', response.text, re.S)
question_url = question_api[0].replace('\\u002F', '/')
# 用新的cookie请求问题api,回调函数为parse_question
yield Request(url=question_url,callback=self.parse_question,headers={'cookie':cookie}) def parse_question(self,response):
'''
解析问题api返回的json数据
'''
# 构造新cookie
cookie = handle_cookie(response)
dics = json.loads(response.text)
for dic in dics['data']:
try:
ques_item = QuestionItem()
if 'question' in dic['target']:
# 问题标题
ques_item['title'] = dic['target']['question']['title']
# 问题创建时间
ques_item['created'] = dic['target']['question']['created']
ques_item['created'] = timestamp_2_date(ques_item['created'])
# 回答数
ques_item['answer_num'] = dic['target']['question']['answer_count']
# 评论数
ques_item['comment_num'] = dic['target']['question']['comment_count']
# 关注人数
ques_item['follow_nums'] = dic['target']['question']['follower_count']
# 问题id
ques_item['question_id'] = dic['target']['question']['id']
#问题url
ques_item['url'] = dic['target']['question']['id']
ques_item['url'] = 'https://www.zhihu.com/question/' + str(ques_item['url'])
# 问题标签
if 'uninterest_reasons' in dic:
topics = []
for i in dic['uninterest_reasons']:
topics.append(i['reason_text'])
ques_item['topics'] = topics
# 作者url
ques_item['author_url'] = dic['target']['question']['author']['url']
# 作者名
ques_item['author_name'] = dic['target']['question']['author']['name']
# 作者签名
ques_item['author_headline'] = dic['target']['question']['author']['headline']
# 作者性别
ques_item['author_gender'] = dic['target']['question']['author'].get('gender')
if ques_item['author_gender']:
if ques_item['author_gender'] == 0:
ques_item['author_gender'] = '女'
else:
ques_item['author_gender'] = '男'
else:
ques_item['author_gender'] = '未知'
# 爬取时间
ques_item['crawl_time'] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
yield ques_item
except:
pass
# 问题api里会有个is_end的值,用来判断是否还有下一页
if not dics['paging']['is_end']:
# 有下一页,获取next里的下一页链接
next_url = dics['paging']['next']
# 用新的cookie请求下一页问题url
yield Request(url=next_url, callback=self.parse_question, headers={'cookie': cookie})
# 请求答案api,api需要传入question_id, limit及页码
yield Request(url=self.answer_api.format(ques_item['question_id'], 20, 0), callback=self.parse_answer) def parse_answer(self,response):
#处理answerAPI返回的json
ans_json = json.loads(response.text)
# is_end的值意味着当前url是否是最后一页
is_end = ans_json['paging']['is_end']
totals_answer = ans_json['paging']['totals']
# 下一页url
next_url = ans_json['paging']['next']
for answer in ans_json['data']:
ans_item = Answer_Item()
# 答案id
ans_item['answer_id'] = answer['id']
# 答案对应的问题id
ans_item['question_id'] = answer['question']['id']
# 答案url
ans_item['url'] = answer['url']
# 答者用户名
ans_item['user_name'] = answer['author']['name'] if 'name' in answer['author'] else None
# 答者id
ans_item['user_id'] = answer['author']['id'] if 'id' in answer['author'] else None
# 答案内容
ans_item['content'] = answer['content'] if 'content' in answer else None
# 赞同人数
ans_item['praise_num'] = answer['voteup_count']
# 评论人数
ans_item['comment_num'] = answer['comment_count']
# 答案创建时间
ans_item['create_time'] = answer['created_time']
ans_item['create_time'] = timestamp_2_date(ans_item['create_time'])
# 答案修改时间
ans_item['update_time'] = answer['updated_time']
ans_item['update_time'] = timestamp_2_date(ans_item['update_time'])
# 爬取时间
ans_item['crawl_time'] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
yield ans_item
# offset偏移,一页20,每问题只爬50页回答。即offest>1000
offset = next_url.split('offset=')[1].split('\u0026')[0]
if int(offset)>1000:
pass
else:
# 当当前页不为最后一页且offset不大于1000时,继续请求下一页答案
if not is_end:
yield scrapy.Request(url=next_url, callback=self.parse_answer)
settings.py添加以下行:
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True FEED_EXPORT_ENCODING = 'utf-8' # redis配置
REDIS_HOST = '填状态管理器服务器ip,请一定要保证redis数据库能远程访问'
REDIS_PORT = 6379
# redis密码
REDIS_PARAMS = {'password': ''} # 当scrapy-redis爬完之后会空等, 等待redis提供继续爬取的url。但是如果已经爬完了。没必要继续等,设置这个当意味启动3600s时停止spider。
CLOSESPIDER_TIMEOUT = 3600
pipelines.py的修改,将数据保存到远程mongodb数据库服务器:
from pymongo import MongoClient class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item class MongoPipeline(object): def __init__(self, databaseIp='远程mongodb服务器ip', databasePort=27017, user="", password="",):
self.client = MongoClient(databaseIp, databasePort)
# self.db = self.client.test_database
# self.db.authenticate(user, password) def process_item(self, item, spider): postItem = dict(item) # 把item转化成字典形式
print(postItem)
if item.__class__.__name__ == 'QuestionItem':
mongodbName = 'zhihu'
self.db = self.client[mongodbName]
# 更新插入问题数据
self.db.question.update({'question_id':postItem['question_id']},{'$set':postItem},upsert=True) elif item.__class__.__name__ == 'Answer_Item':
mongodbName = 'zhihu'
self.db = self.client[mongodbName]
# 更新插入答案数据
self.db.answer.update({'answer_id': postItem['answer_id']}, {'$set': postItem}, upsert=True)
# 会在控制台输出原item数据,可以选择不写
return item
middlewares.py的修改:
import logging
import random
import time class RandomDelayMiddleware(object):
'''
这个类用来设置自定义的随机延时
'''
def __init__(self, delay):
self.delay = delay @classmethod
def from_crawler(cls, crawler):
delay = crawler.spider.settings.get("RANDOM_DELAY", 10)
if not isinstance(delay, int):
raise ValueError("RANDOM_DELAY need a int")
return cls(delay) def process_request(self, request, spider):
if 'signin?next' in request.url:
raise IgnoreRequest
delay = random.randint(0, self.delay)
logging.debug("### random delay: %s s ###" % delay)
time.sleep(delay) class RandomUserAgentMiddleware():
'''
这个类用来给spider随机设置user_agent里的请求头
'''
user_agent = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agent) class CookieMiddleware():
'''
这个类用来给spider随机设置cookie,scrapy要求cookies是字典类型
'''
def process_request(self, request, spider):
with open('cookies.txt') as f:
raw_cookie = f.read()
# 当请求首页时,提供cookie
if request.url in 'https://www.zhihu.com/':
request.headers['cookie'] = raw_cookie
print('---',request.headers)
使用py文件 启动scrapy-redis:
from scrapy.cmdline import execute
import sys
import os # os.path.abspath(__file__)当前py文件的路径
# os.path.dirname(os.path.abspath(__file__))当前文件目录
# 设置工程目录
sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 相当于在cmd里执行scrapy crawl zhihu
execute(['scrapy','crawl','zhihu'])
启动后scrapy-redis会等待start_urls push进redis
我在centos服务器布置好了redis,在终端执行以下命令以将知乎首页放进redis:
redis-cli
auth 123456
lpush zhihu:start_urls https://www.zhihu.com
项目docker镜像制作
centos关于docker的安装请参考,系统要求是centos7+:
https://www.runoob.com/docker/centos-docker-install.html
如果是阿里云的服务器可以到阿里云查看如何设置自己的镜像加速器。
首先创建一个没有后缀名的Dockerfile文件:
1 ##阿里云python3 镜像
2 FROM registry.cn‐shanghai.aliyuncs.com/tcc‐public/python:3
3 ##添加/usr/local/bin这个路径
4 ENV PATH /usr/local/bin:$PATH
5 ##将本地的代码放置到虚拟容器当中
6 ADD . /code
7 ##指定工作目录
8 WORKDIR /code
9 ## 执行pip3 install ‐r requirements.txt
10 RUN pip3 install ‐r requirements.txt
11 ## 执行scrapy crawl zhihu开始爬取
12 CMD scrapy crawl zhihu
requirements.txt
lxml==4.4.2
pymongo==3.10.1
redis==3.4.1
requests==2.22.0
Scrapy==1.8.0
scrapy-redis==0.6.8
如下:
build:
docker build -t registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0 .
注意: registry.~~~ 是上面创建仓库的公网地址,用自己仓库地址替换。地址后面的:1.0为自己指定的版本号,用于区分每次build的镜像。最后的.是构建镜像的路径,不可以
省掉。
测试是否能正常运行,正常运行后再进行推送。:
docker run registry.cn‐shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
推送到镜像仓库:
docker push registry.cn‐shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
在另外机器使用docker运行项目:
先登录
sudo docker login ‐‐username=*** registry.cn‐shanghai.aliyuncs.com
再直接运行即可:
docker run registry.cn‐shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
目前几台机器同时运行时没问题的:
最后,已将该项目放github,若有需要的话请上去拿~
https://github.com/dao233/spider/tree/master/ArticleSpider
END~
scrapy-redis分布式爬取知乎问答,使用docker布置多台机器。的更多相关文章
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- scrapy爬取知乎问答
登陆 参考 https://github.com/zkqiang/Zhihu-Login # -*- coding: utf-8 -*- import scrapy import time impor ...
- Scrapy爬虫笔记 - 爬取知乎
cookie是一种本地存储机制,cookie是存储在本地的 session其实就是将用户信息用户名.密码等)加密成一串字符串,返回给浏览器,以后浏览器每次请求都带着这个sessionId 状态码一般是 ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- Scrapy 分布式爬取
由于受到计算机能力和网络带宽的限制,单台计算机运行的爬虫咋爬取数据量较大时,需要耗费很长时间.分布式爬取的思想是“人多力量大”,在网络中的多台计算机同时运行程序,公童完成一个大型爬取任务, Scrap ...
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
随机推荐
- python 入门手册
python 入门手册 Introduction 这个手册是为了让学习者好好的重塑对于编程的认识,我们要来认识到怎么来在陌生的领域学习,学习的技巧开始,通过官方文档来学习 开端 利用IDE输出&quo ...
- AngularJS中格式化日期为指定格式字符串
var date = $filter('date')(new Date(),'MM/dd/yyyy');
- 企业级rancher搭建Kubernetes(采用rancher管理平台搭建k8s)
一.简介 Rancher简介 来源官方:https://www.cnrancher.com/ Rancher是一个开源的企业级容器管理平台.通过Rancher,企业再也不必自己使用一系列的开源软件去从 ...
- bzoj1432_[ZJOI2009]Function
题目描述 有n 个连续函数fi (x),其中1 ≤ i ≤ n.对于任何两个函数fi (x) 和fj (x),(i != j),恰好存在一个x 使得fi (x) = fj (x),并且存在无穷多的x ...
- 吴裕雄--天生自然 python数据分析:加纳卫生设施数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
- linux公社大量免费的在线android资料
2011年linux数据库的android在线分享 linux公社:开源公社 本文撰写:杨凯专属频道 下载如需密码,详见博客案例:点击我去查看密码 2011年9月12日 21: ...
- 阿里投资Magic Leap 是美酒还是毒药?
Leap 是美酒还是毒药?" title="阿里投资Magic Leap 是美酒还是毒药?"> 土豪阿里又摊上"大事"了!但这次不是让人头痛的假 ...
- sql问题处理
批量杀死MySQL连接 select concat('KILL ',id,';') from information_schema.processlist where Info like 'selec ...
- 空间数据导入Oracle数据库备忘
- 硬件小白学习之路(1)稳压芯片LM431
图稳压芯片LM431简介 偶然的机会接触到LM431这个芯片,周末晚上打发无聊的时光,查资料进行剖析. LM431的Symbol Diagram和Functional Diagram如图1所示,下面分 ...