当AI遇上K8S:使用Rancher安装机器学习必备工具JupyterHub
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。本文将详细介绍如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。

本文来自 Rancher Labs
人工智能(AI)和机器学习(ML)正在成为技术领域的关键差异化因素。从本质上讲,人工智能和机器学习都是计算量巨大的工作负载,它们需要一流的分布式计算环境才能够蓬勃发展。因此,AI和ML为Kubernetes提供了一个完美的用例,他们能够最大化展现Kubernetes可以运行大量工作负载的特点。
什么是JupyterHub?
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。JupyterHub是一个多用户数据探索工具,通常是数据科学和机器学习研究与开发的关键工具。它为工程师、科学家、研究人员和学生提供了云或数据中心的计算能力,同时仍然像本地开发环境一样易于使用。本质上,JupyterHub使用户可以访问计算环境和资源,而不会给他们增加安装和维护任务的负担。用户可以在工作区中使用共享资源,系统管理员会对其进行有效管理。
在AI/ML工作负载中使用Kubernetes
Kubernetes非常擅长让我们利用大型分布式计算环境。因为其声明式设计和基于发现的服务器寻址方法,所以将计算资源应用于工作负载很容易。通常在AI/ML工作负载中,工程师或研究人员需要分配更多的资源。而Kubernetes让在物理基础架构之间迁移工作负载更加可行。在本文中,我们将展示如何使用Rancher安装JupyterHub。
使用Rancher安装JupyterHub
首先,假设我们在Rancher环境中拥有现代化的Kubernetes部署。在本文发布时,Kubernetes的稳定版本是1.16。对于JupyterHub来说,其中一个前期准备是持久化存储,所以你将需要思考如何在这个集群中提供它。出于演示的目的,我们可以使用Rancher Catalog中包含的实验性NFS提供程序来提供持久化存储。点开App Catalog并选择【启动】。然后搜索NFS提供程序。保留默认设置,然后单击屏幕底部的【启动】。如果你已经有持久化存储的解决方案,也可以直接使用它。

导航到Rancher App Catalog
搜索NFS提供程序
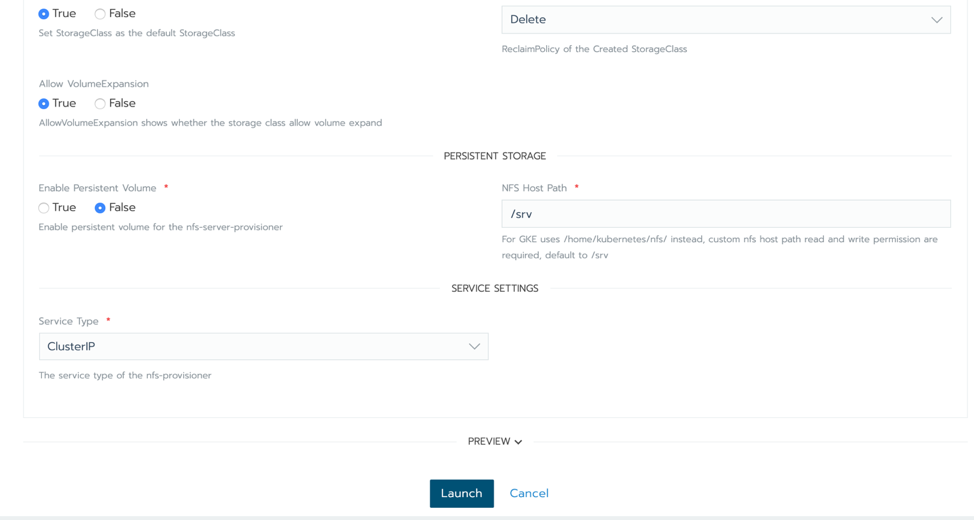
启动NFS提供程序
现在我们已经有了存储提供程序并且定义了默认存储类,我们可以继续部署应用程序组件。我们将使用Helm3来完成这一操作。查看helm官方文档(https://helm.sh/docs/intro/install/ ),在你的电脑上安装helm3客户端。另外,你也可以使用Rancher Catalog来部署helm chart,而无需任何其他工具。需要确保将repo添加到Rancher catalog中。
在我们使用helm之前,我们需要为应用程序创建一个命名空间。在Rancher UI中,进入集群并选择顶端菜单栏的【项目/命名空间】。你可以为JupyterHub创建一个新的命名空间。例如,我们将命名空间称为“jhub“。请注意此名称,因为我们将之后会使用。
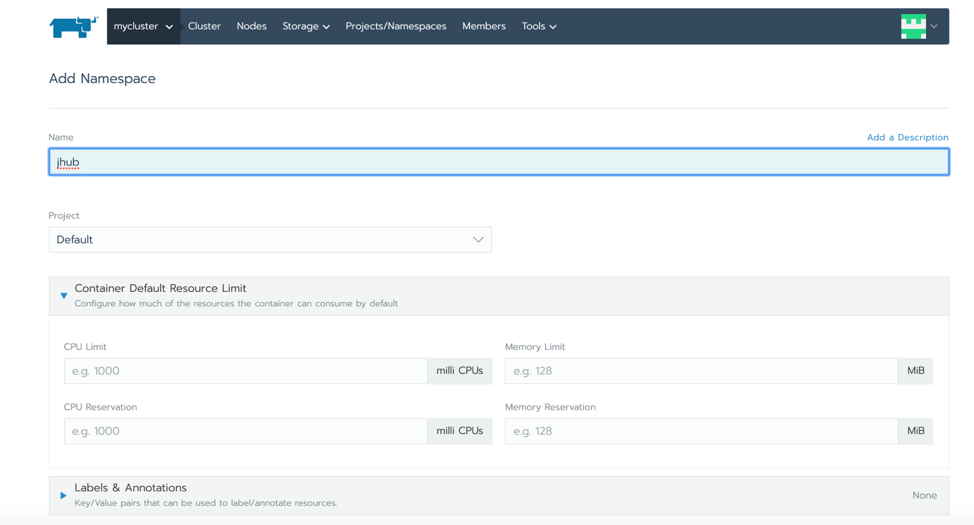
创建一个命名空间
接下来,我们可以为将要使用的JupyterHub Chart添加Helm repo。如果使用的是Rancher catalog,你需要在UI上完成此操作而不是Helm CLI:
helm repo add jupyterhub https://jupyterhub.github.io/helm-chart/
helm repo update
然后,让我们创建一个config文件,其中包含了我们要与此chart一起使用的设置。我们将该文件命名为config.yaml:
proxy:
secretToken: "<secret token>"
ingress:
enabled: true
hosts:
- <host name>
让我们替换几个项目,使它们是唯一的。用以下输出替换secretToken:
openssl rand -hex 32
并替换为你打算用来访问JyupiterHub UI的可解析DNS名称。
有了配置文件之后,就可以安装chart了。我们将引用该配置文件,因此请确保该文件存在你当前的工作目录中:
RELEASE=jhub
NAMESPACE=jhub
helm upgrade --install $RELEASE jupyterhub/jupyterhub --namespace $NAMESPACE --version=0.8.2 --values config.yaml
Helm现在应该部署所需的组件。这将需要一些时间,但是最终你应该能够通过之前设置的主机名访问UI。你也可以通过转到Rancher UI中的“工作负载“选项卡来检查状态。当我们尝试在浏览器中设置的主机名时,它将显示以下登录界面:
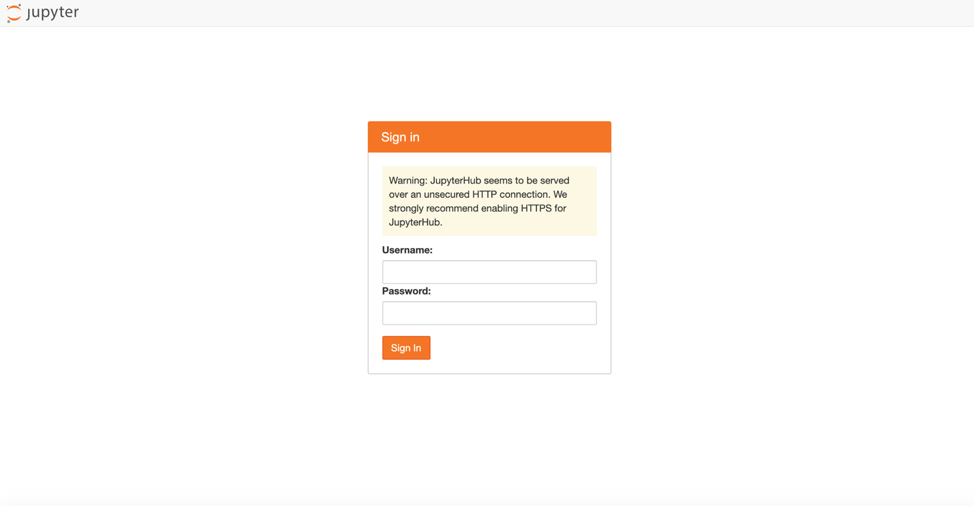
主机名登录界面
在撰写本文时,有一个issue是Kubernetes 1.16中的更改导致Jyupiter Hub的代码在尝试与Kuberentes API交互时中断。如果要立即修复,我们可以运行以下patch命令:
kubectl patch deploy -n $NAMESPACE hub --type json --patch '[{"op": "replace", "path": "/spec/template/spec/containers/0/command", "value": ["bash", "-c", "\nmkdir -p ~/hotfix\ncp -r /usr/local/lib/python3.6/dist-packages/kubespawner ~/hotfix\nls -R ~/hotfix\npatch ~/hotfix/kubespawner/spawner.py << EOT\n72c72\n< key=lambda x: x.last_timestamp,\n---\n> key=lambda x: x.last_timestamp and x.last_timestamp.timestamp() or 0.,\nEOT\n\nPYTHONPATH=$HOME/hotfix jupyterhub --config /srv/jupyterhub_config.py --upgrade-db\n"]}]'
你现在已经在Rancher上部署了可以正常工作的JupyterHub环境。默认情况下,JupyterHub使用PAM身份验证。因此,可以使用系统上的任何有效Linux用户登录。登录后,我们应该能够创建新的notebook:
Jupyter登录界面
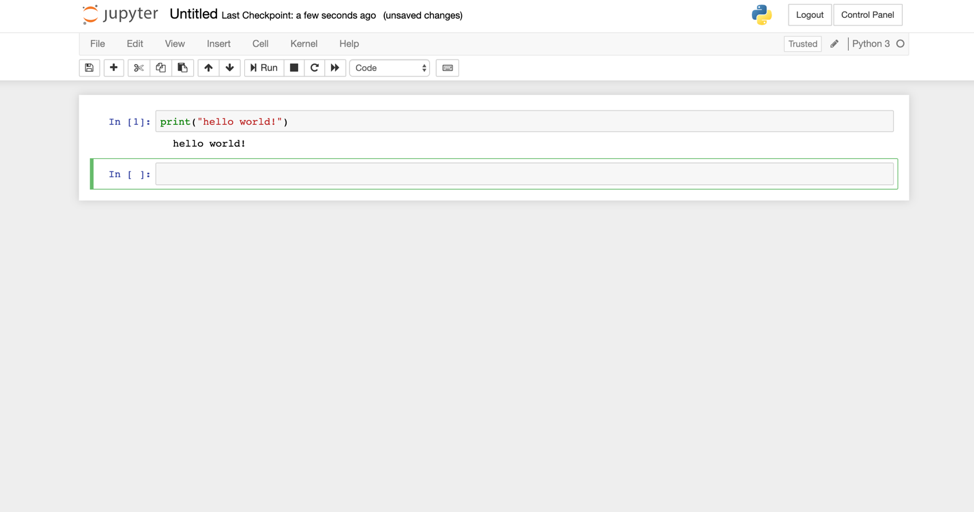
创建新的notebook
另外,你可以查看其他你可能想配置的身份验证选项。例如,你可以使用Github身份验证来允许用户登录并且创建基于他们Github ID的notebook。你选择好一个身份验证的工具之后,需要按照说明更新我们之前创建的config.yml文件,然后重新运行helm upgrade命令。
总 结
在本文中,我们展示了如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。如果你想要安装功能齐全的JupyterHub安装,你可能还需要考虑其他因素。本文只是向你展示了如何快速搭建一个基础功能的JupyterHub,希望能帮助你快速开启AI旅程!
当AI遇上K8S:使用Rancher安装机器学习必备工具JupyterHub的更多相关文章
- 关于ubuntu服务器上部署postgresql 以及安装pgadmin4管理工具(web版)
进入目录:cd pgadmin4 source bin/activate cd pgadmin4-1.6/ 启动pgadmin4:python web/pgAdmin4.py pgadmi ...
- .NET遇上Docker - Harbor的安装与基本使用
Harbor是一个开源企业级Docker注册中心,可以用于搭建私有的Docker Image仓库.可以实现权限控制等. 安装Harbor 首先,需要安装Docker和Docker Compose,参考 ...
- ubuntu 18.04 64bit下如何安装python开发工具jupyterhub
注:这是多用户版本 1.安装依赖 sudo apt-get install npm nodes sudo apt-get install python3-distutils wget https:// ...
- 初识genymotion安装遇上的VirtualBox问题
想必做过Android开发的都讨厌那慢如蜗牛的 eclipse原生Android模拟器吧! 光是启动这个模拟器都得花上两三分钟,慢慢的用起来手机来调试,但那毕竟不是长久之计,也确实不方便,后来知道了g ...
- 微服务中台落地 中台误区 当中台遇上DDD,我们该如何设计微服务
小结: 1. 微服务中台不是 /1堆砌技术组件就是中台 /2拥有服务治理就是中台 /3增加部分业务功能就是中台 /4Cloud Native 就是中台 https://mp.weixin.qq.com ...
- K8s集群安装--最新版 Kubernetes 1.14.1
K8s集群安装--最新版 Kubernetes 1.14.1 前言 网上有很多关于k8s安装的文章,但是我参照一些文章安装时碰到了不少坑.今天终于安装好了,故将一些关键点写下来与大家共享. 我安装是基 ...
- mac上k8s学习踩坑
本文学习k8s参考内容:http://docs.kubernetes.org.cn/126.html,学习过程中遇到一些坑,记录如下: -------------------------------- ...
- 前端遇上Go: 静态资源增量更新的新实践
前端遇上Go: 静态资源增量更新的新实践https://mp.weixin.qq.com/s/hCqQW1F8FngPPGZAisAWUg 前端遇上Go: 静态资源增量更新的新实践 原创: 洋河 美团 ...
- Kubernetes(k8s)集群安装
一:简介 二:基础环境安装 1.系统环境 os Role ip Memory Centos 7 master01 192.168.25.30 4G Centos 7 node01 192.168.25 ...
随机推荐
- Zabbix调用外部脚本发送邮件:python编写脚本
Zabbix调用外部脚本发送邮件的时候,会在命令行传入两个参数,第一个参数就是要发送给哪个邮箱地址,第二个参数就是邮件信息,为了保证可以传入多个参数,所以假设有多个参数传入 #!/usr/bin/en ...
- Cortana携手微软学术搜索,变身研究人员最佳个人助理
编者按:在美国时间7月14日于微软总部雷蒙德召开的2014年微软教育峰会上,负责技术与研究的微软全球执行副总裁沈向洋博士在他的开幕主题演讲中正式宣布,Windows Phone 8.1系统中的虚拟个人 ...
- 使用 ActiveMQ 示例
« Lighttpd(fastcgi) + web.py + MySQLdb 无法正常运行关于 Jms Topic 持久订阅 » 使用 ActiveMQ 示例 企业中各项目中相互协作的时候可能用得到消 ...
- Windows下使用swoole的环境搭建
Cygwin 官方地址:http://www.cygwin.com/ swoole 官方下载地址:https://github.com/swoole/swoole-src/releases 方法/步骤 ...
- 《JavaScript算法》二分查找的思路与代码实现
二分查找的思路 首先,从有序数组的中间的元素开始搜索,如果该元素正好是目标元素(即要查找的元素),则搜索过程结束,否则进行下一步. 如果目标元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半 ...
- Java volatile修饰字段
一.关键字volatile修饰字段: 使用特殊域变量(volatile)实现线程同步 volatile:不稳定的:反复无常的:易挥发的: 1.volatile关键字为域变量的访问提供了一种免锁机制, ...
- doctrine queryBuilder
为了能够方便的切换数据库,我们有必要使用doctrine的queryBuilder, 但是估计很多人都是不喜欢的(我也是),之前尝试用的时候,发现在doctrine定义的SELECT语法中并没有CON ...
- 开始使用Github
Gather ye rosebuds while ye may 我自己也是刚开始使用github没几天,写得不好我就写自己常用的吧 2015年9月20日下午3:19更新知乎上这个答案写得好多了
- 如何理解TCP的三次握手协议?
• TCP是一个面向链接的协议,任何一个面向连接的协议,我们都可以将其类比为我们最熟悉的打电话模型. 如何类比呢?我们可以从建立和销毁两个阶段分别来看这件事情. 建立连接阶段 首先,我们来看看TCP中 ...
- java内存区域----运行时数据区
Java虚拟机的内存区域也叫做java运行时数据区,共分为五个部分:程序计数器,方法区,本地方法栈,虚拟机栈和堆.方法区和堆是线程之间所共有的,程序计数器,本地方法栈,虚拟机栈是线程私有的.其中虚拟机 ...