python爬虫入门之快递查询
现在快递遍布生活的角角落落,一个快递其实是信息的集合体,里面包含大量的物流信息,那能不能自己实现一个快递查询的小功能?答案是能的!现在也有别人整理好的快递查询api,比如说快递100,可以通过它提供的API查询各个快递品牌的物流信息,但它的免费版本一天只能查询100次,还需要填电子信息申请!比较麻烦!
要想摆脱这种次数的限制,那只能不用别人整理好的api。自己去各个快递品牌公司官网上分析他们数据怎么请求的,怎么获得到的,然后用爬虫获取。这里就以中通快递为例(因为这个数据请求分析起来比较简单,适合入门),教大家爬虫入门。
1.数据请求分析
打开中通快递官网,查询一个快递单号后它会显示这个快递当前的物流信息。但是仅在这个页面,看不到它的数据到底是通过什么链接,做了什么操作请求过来的?这就要用到浏览器的开发者工具。
按F12将浏览器自带的开发者工具显示出来,选择NetWork,然后选择XHR这个标签(这个标签将会记录ajax中的请求)。接下来再点击左边的查询按钮,会发现开发者工具XHR里面多了好多文件,这些文件就是浏览器通过ajax向服务器发送的请求,里面包含浏览器的请求头,请求连接,请求数据,服务器的响应连接,响应数据等。
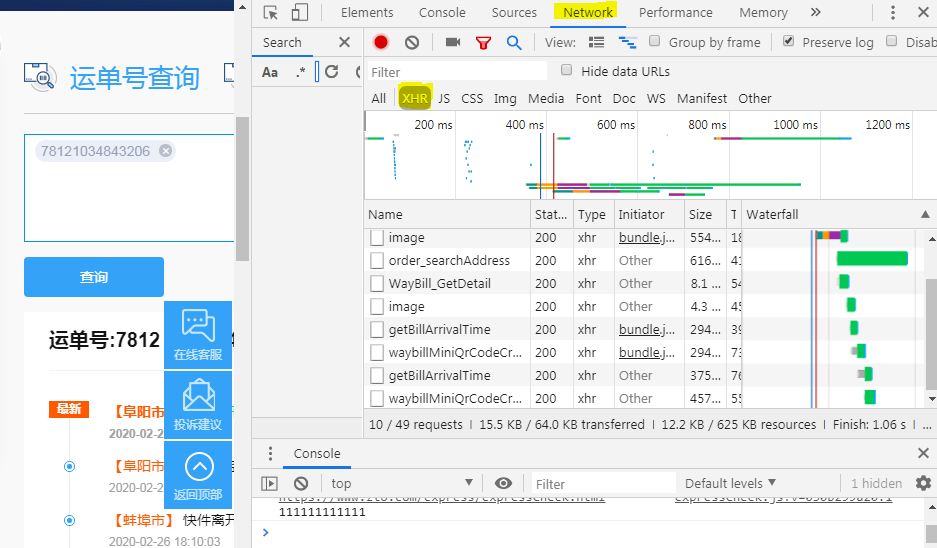
先从这些请求名字来看,其中有个叫WayBill_GetDetail的,按名字的理解来说,它应该是得到详细的什么东东。那猜测它就是获得详细数据的请求,点开它来分析一下。
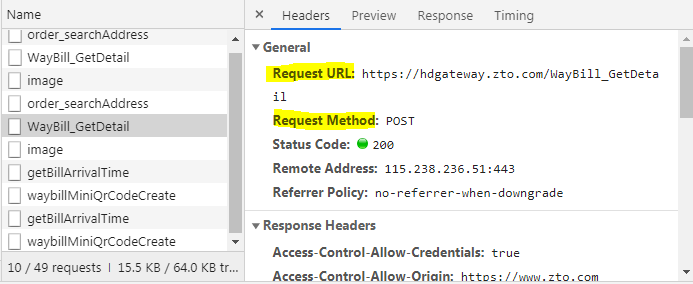
可以看到这个请求的请求头headers中包含请求连接Request URL,也就是说浏览器是向这个链接发送请求的,请求方式为POST。请求的时候带参数了么?接着往下看。
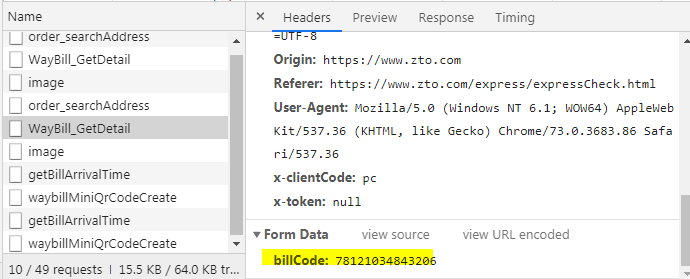
在最下面可以看到Form data 就是提交的参数billCode,参数的值就是输入的快递单号。当浏览器向链接发送请求的时候,会带上这个billCode参数,那么来试一下这个请求到底获得是什么数据。
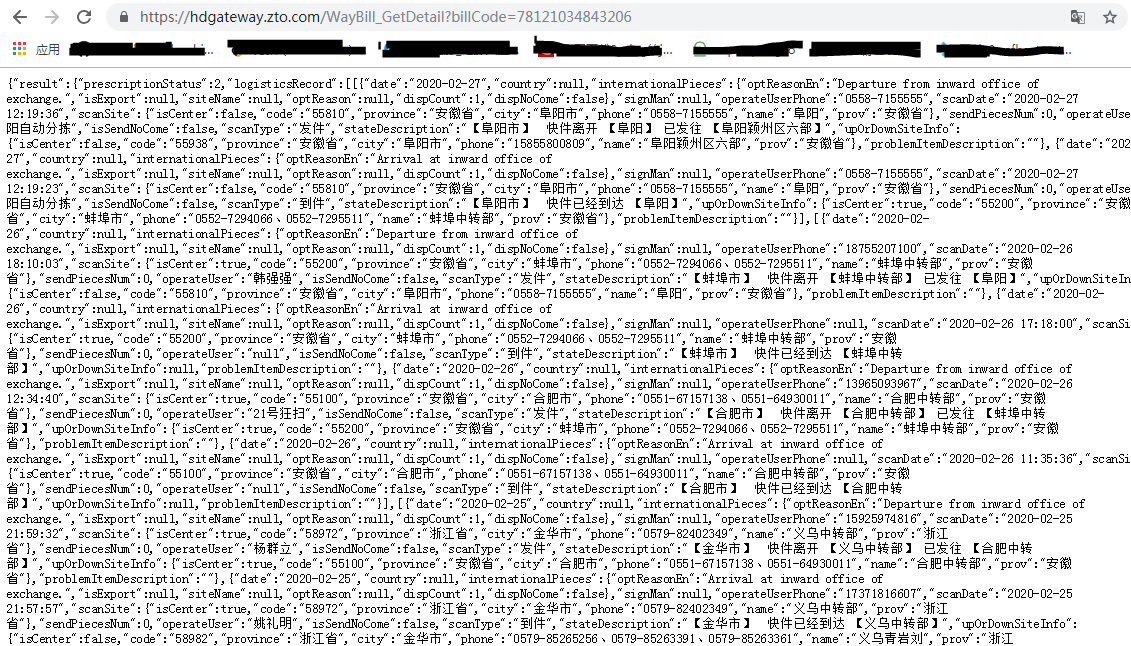
在浏览器输入刚刚那个Request URL链接,后面加?跟上参数billCode,会发现请求回来的是一个json字符串,里面包含这个快递单号的所有物流信息。接下来只需对这个json解析就好。
2.代码实现
经过简单的url分析,拿到了真实的数据请求链接和链接参数,这样就可以自己根据这个链接编码实现数据请求。
在请求的时候为了避免被反爬虫,需要在请求的时候加上请求头header,里面的内容看着是不是有些熟悉?没错,它就是WayBill_GetDetail请求的请求头,直接可以从浏览器获取到,然后用requests.get方法请求数据。
def search(billCode):
url = "https://hdgateway.zto.com/WayBill_GetDetail?
billCode="+billCode
header = {
"Access-Control-Request-Headers":"x-clientcode,x-token",
"Access-Control-Request-Method":"POST",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
req = requests.get(url, headers = header)
return req.json()
这样就拿到这个快递的所有物流信息,接下来对这个json进行分析。从网上随便找一个json解析工具,对这一串解析可得到如图的有序数据,快递物流信息都在logisticsRecord这个标签中,每一天的物流信息组成logisticsRecord标签中的一项,遍历logisticsRecord,就可以得到每天的物流信息。而每一天的物流信息又包括时间,地点描述等。
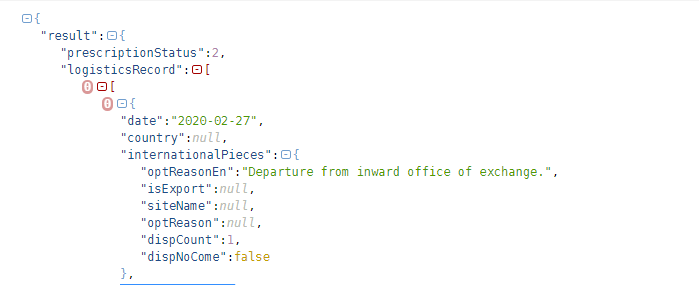
简单分析json后,开始编码:
def parse_json(data):
logisticsRecord = data["result"]["logisticsRecord"]
for day in logisticsRecord:
for item in day:
date = item["scanDate"]
description = item["stateDescription"]
print(date)
print(description)
这里只显示scanDate扫描时间和stateDescription状态描述(即快递到哪儿)主函数main:
if __name__ == '__main__':
while True:
print("欢迎大家来到中通邮件查询系统")
print("请输入查询单号:")
num = input()
data = search(num)
parse_json(data) n = input("还要接着查询嘛?(y/n):")
if n == "n":
break
print("谢谢大家使用")
结果演示:
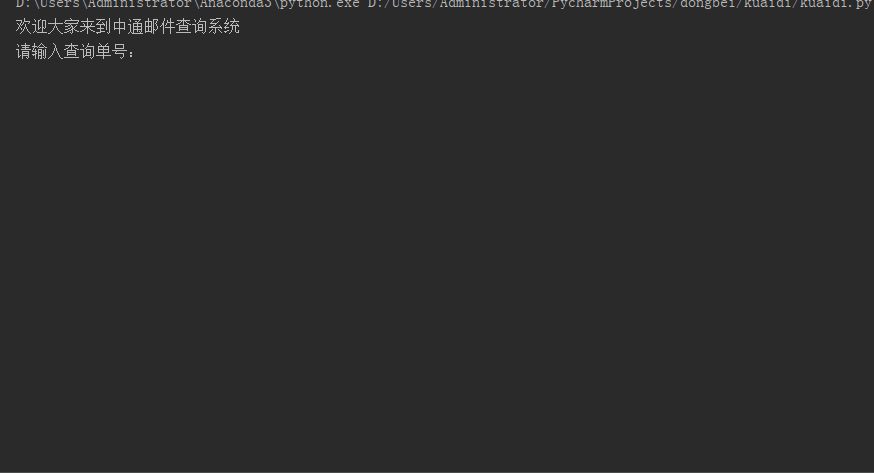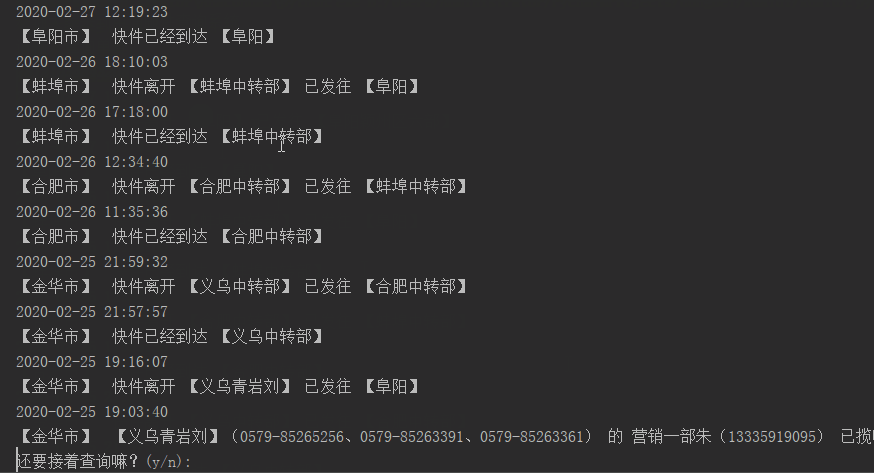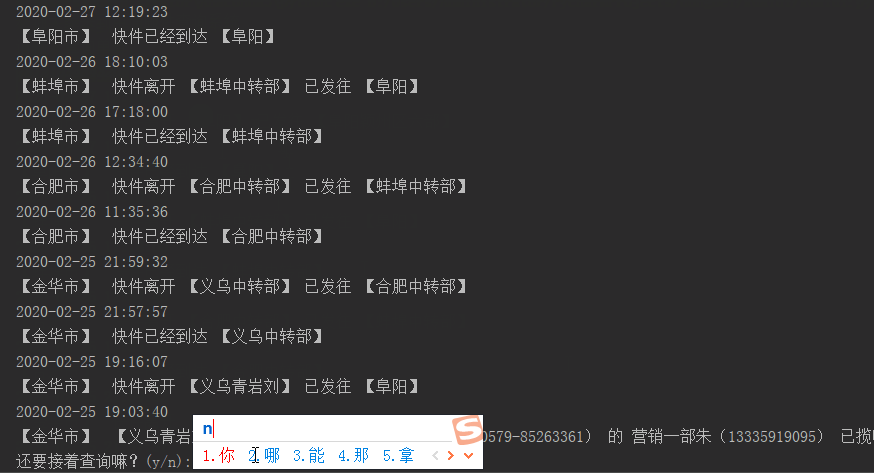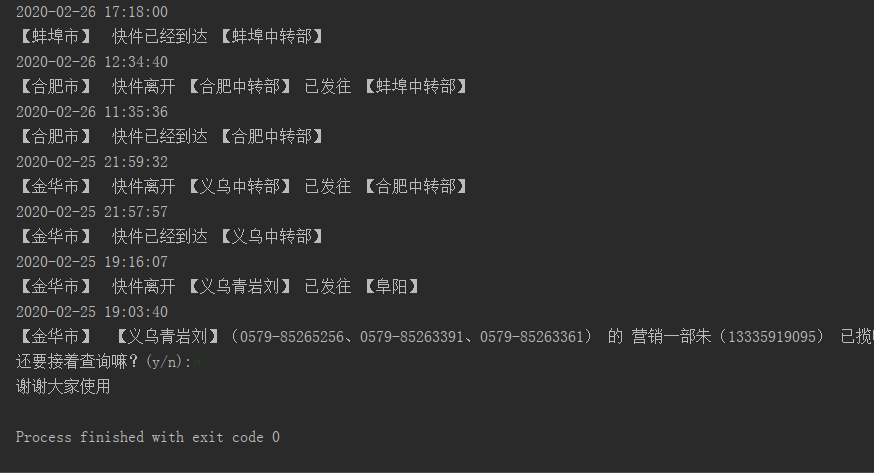
这里只实现了快递查询的关键代码,即请求数据和解析json,界面有点丑陋,也不人性化。小伙伴们可以用pyqt写一个简单的界面,这样使用起来更加方便。
欢迎大家关注 公众号:ly戏说编程 免费解答学习中的问题,这里有python数据分析,爬虫,机器学习,java基础,java项目,html教程,css,js等等课程!还有整理的一些电子书,会不定时发放给大家!
python爬虫入门之快递查询的更多相关文章
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- python爬虫入门01:教你在 Chrome 浏览器轻松抓包
通过 python爬虫入门:什么是爬虫,怎么玩爬虫? 我们知道了什么是爬虫 也知道了爬虫的具体流程 那么在我们要对某个网站进行爬取的时候 要对其数据进行分析 就要知道应该怎么请求 就要知道获取的数据是 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
随机推荐
- 页面弹窗toast和加载loading
create-at 2019-04-04 都采用单例模式,原生js实现 兼容老版本浏览器内核,请将用es6语法的地方作修改 loading 加载 代码: 样式全部通过js创建style标签注入head ...
- 3_5 生成元(UVa1583)
如果x加上x的各个数字之和得到y,就说x是y的生成元.给出n(1<=n<=100000),求最小生成元.无解输出0.例如,n=216,121,2005时的解分别为198,0,1979. 样 ...
- MSE-初始化MSE
MSE(Mobility Services Engine) Cisco MSE可以配合无线实现很多功能,MSE的功能简单概括有: 1.基本位置服务捕获并聚合关键网络信息,例如设备位置,RF频谱详细信息 ...
- 2016-2017学年第三次测试赛 问题 F: 签到题
问题 F: 签到题 时间限制: 1 Sec 内存限制: 128 MB提交: 80 解决: 28 提交统计讨论版 题目描述 在计算机网络考试中, 黑帅男神看到一个将IP网络分类的题, 精通C++的他 ...
- vjudge Trailing Zeroes (III) (二分答案 && 数论)
嗯... 题目链接:https://vjudge.net/contest/318956#problem/E 这道题是二分答案+数论,但首先是数论,否则你不知如何二分... 首先关于一个阶乘的结果最后会 ...
- mysqld: [ERROR] Found option without preceding group in config file D:\TONG\mysql-5.7.19-winx64\my.ini at line 1!
my.ini文件编码不对,改为ANSI 貌似大意是说,配置不全 改编码为ANSI解决
- SpringSecurity配置,简单梳理
生活加油:摘一句子: “我希望自己能写这样的诗.我希望自己也是一颗星星.如果我会发光,就不必害怕黑暗.如果我自己是那么美好,那么一切恐惧就可以烟消云散.于是我开始存下了一点希望—如果我能做到,那么我就 ...
- leetCode练题——20. Valid Parentheses
1.题目 20. Valid Parentheses——Easy Given a string containing just the characters '(', ')', '{', '}', ...
- 概念 - 抖脚(Fidgeting)
参考 https://cn.nytimes.com/health/20161220/why-fidgeting-is-good-medicine/dual/ https://baike.baidu.c ...
- Django中defer和only区别
defer('id', 'name'):取出对象,字段除了id和name都有 only('id', 'name'):取出对象, 只有id和name ret=models.Author.objects. ...