iris数据集预测
iris数据集预测(对比随机森林和逻辑回归算法)
随机森林
library(randomForest)
#挑选响应变量
index <- subset(iris,Species != "setosa")
ir <- droplevels(index)
set.seed(1)
ind<-sample(2,nrow(ir),replace=TRUE,prob=c(0.7,0.3))
train<-ir[ind==1,]
test<-ir[ind==2,]
rf<-randomForest(Species~.,data=train,ntree=100)
rf Call:
randomForest(formula = Species ~ ., data = train, ntree = 100)
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 2 OOB estimate of error rate: 5.88%
Confusion matrix:
versicolor virginica class.error
versicolor 32 2 0.05882353
virginica 2 32 0.05882353
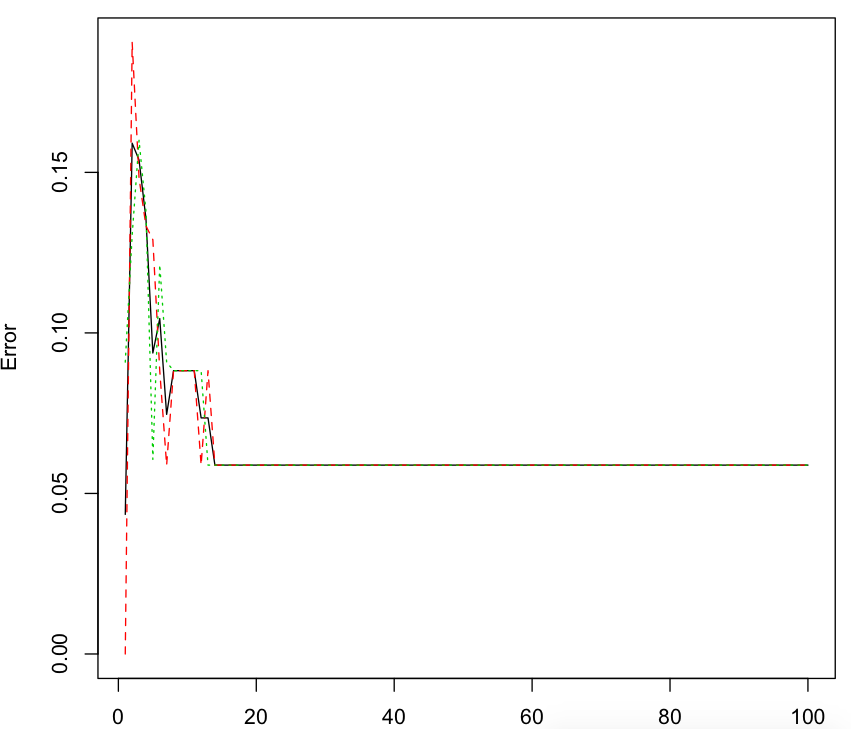
#随机森林的误差率
plot(rf)
#变量重要性
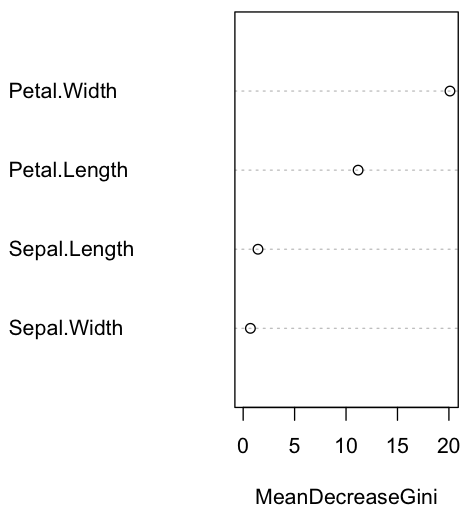
importance(rf)
importance(rf)
MeanDecreaseGini
Sepal.Length 1.4398647
Sepal.Width 0.7037353
Petal.Length 11.1734509
Petal.Width 20.1025569
varImpPlot(rf)
#查看预测结果
pred<-predict(rf,newdata=test)
table(pred,test$Species) pred versicolor virginica
versicolor 15 2
virginica 1 14
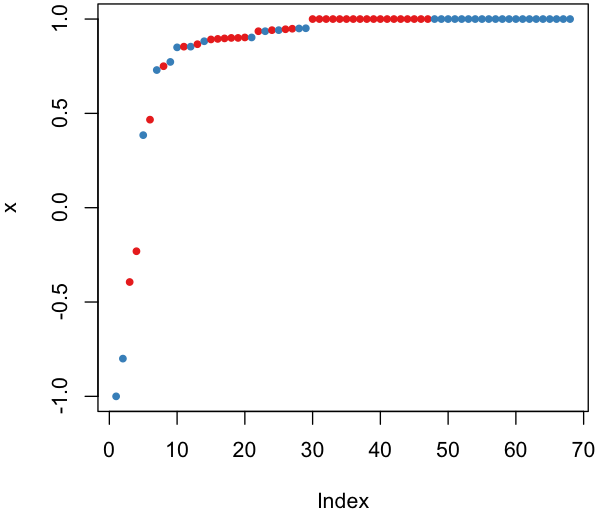
#预测边距
plot(margin(rf,test$Species))
逻辑回归
library(pROC)
g1<-glm(Species~.,family=binomial(link='logit'),data=train)
pre1<-predict(g1,type="response")
g1 Call: glm(formula = Species ~ ., family = binomial(link = "logit"),
data = train) Coefficients:
(Intercept) Sepal.Length Sepal.Width Petal.Length Petal.Width
-32.01349 -3.85855 -0.02084 6.65355 14.08817 Degrees of Freedom: Total (i.e. Null); Residual
Null Deviance: 94.27
Residual Deviance: 8.309 AIC: 18.31 summary(g1) Call:
glm(formula = Species ~ ., family = binomial(link = "logit"),
data = train) Deviance Residuals:
Min 1Q Median 3Q Max
-1.73457 -0.02241 -0.00011 0.03691 1.76243 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -32.01349 28.51193 -1.123 0.2615
Sepal.Length -3.85855 3.16430 -1.219 0.2227
Sepal.Width -0.02084 4.85883 -0.004 0.9966
Petal.Length 6.65355 5.47953 1.214 0.2246
Petal.Width 14.08817 7.32507 1.923 0.0544 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 94.268 on 67 degrees of freedom
Residual deviance: 8.309 on 63 degrees of freedom
AIC: 18.309 Number of Fisher Scoring iterations: 9
#方差分析
anova(g1,test="Chisq")
Analysis of Deviance Table Model: binomial, link: logit Response: Species Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev Pr(>Chi)
NULL 94.268
Sepal.Length 14.045 80.223 0.0001785 ***
Sepal.Width 0.782 79.441 0.3764212
Petal.Length 62.426 17.015 2.766e-15 ***
Petal.Width 8.706 8.309 0.0031715 **
---
Signif. codes: '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' '
#计算最优阀值
modelroc1<-roc(as.factor(ifelse(train$Species=="virginica",1,0)),pre1)
plot(modelroc1,print.thres=TRUE)

评估模型的预测效果
predict <-predict(g1,type="response",newdata=test)
predict.results <-ifelse(predict>0.804,"virginica","versicolor")
misClasificError <-mean(predict.results !=test$Species)
print(paste("Accuracy:",1-misClasificError))
[1] "Accuracy: 0.90625"
XGBoost
y<-data.matrix(as.data.frame(train$Species))-1
x<-data.matrix(train[-5])
bst <- xgboost(data =x, label = y, max.depth = , eta = ,nround = , objective = "binary:logistic") [] train-error:0.029412
[] train-error:0.029412
p<-predict(bst,newdata=data.matrix(test))
modelroc2<-roc(as.factor(ifelse(test$Species=="virginica",1,0)),p)
plot(modelroc2)

predict.results <-ifelse(p>0.11,"virginica","versicolor")
misClasificError <-mean(predict.results !=test$Species)
print(paste(-misClasificError))
[] "0.90625"
iris数据集预测的更多相关文章
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- Iris数据集实战
本次主要围绕Iris数据集进行一个简单的数据分析, 另外在数据的可视化部分进行了重点介绍. 环境 win8, python3.7, jupyter notebook 目录 1. 项目背景 2. 数据概 ...
- 从Iris数据集开始---机器学习入门
代码多来自<Introduction to Machine Learning with Python>. 该文集主要是自己的一个阅读笔记以及一些小思考,小总结. 前言 在开始进行模型训练之 ...
- 85、使用TFLearn实现iris数据集的分类
''' Created on 2017年5月21日 @author: weizhen ''' #Tensorflow的另外一个高层封装TFLearn(集成在tf.contrib.learn里)对训练T ...
- 用Python实现支持向量机并处理Iris数据集
SVM全称是Support Vector Machine,即支持向量机,是一种监督式学习算法.它主要应用于分类问题,通过改进代码也可以用作回归.所谓支持向量就是距离分隔面最近的向量.支持向量机就是要确 ...
- iris数据集(.csv .txt)免费下载
我看CSDN下载的iris数据集都需要币,我愿意免费共享,希望下载后的朋友们给我留个言 分享iris数据集(供学习使用): 链接: https://pan.baidu.com/s/1Knsp7zn-C ...
- R语言实现分层抽样(Stratified Sampling)以iris数据集为例
R语言实现分层抽样(Stratified Sampling)以iris数据集为例 1.观察数据集 head(iris) Sampling)以iris数据集为例"> 选取数据集中前6个 ...
- KNN算法实现对iris数据集的预测
KNN算法的实现 import pandas as pd from math import dist k = int(input("请输入k值:")) dataTest = pd. ...
随机推荐
- ACM-挑战题之排列生成
题目描述:挑战题之排列生成 一自然数N,设N为3,则关于N的字典序排列为123,132,213,231,312,321.对于一个自然数N(1<= N <= 9 ) , 你要做的便是生成它的 ...
- Golang的标准命令简述
Golang的标准命令简述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Go本身包含了大量用于处理Go程序的命令和工具.go命令就是其中最常见的一个,它有许多子命令,接下来就跟随 ...
- VC 插入excel
CString ePath,iPath; m_ePath.GetWindowText(ePath); m_iPath.GetWindowText(iPath); _Application app; W ...
- nginx常用配置解析
1.常用公共参数(一般放在http下面,虽然很多参数都支持server和location) keepalive_timeout 60; #单位为s keepalive_request 2; #设 ...
- spring-@ResponseBody返回时的编码处理
下面是一个解决方案 @RequestMapping(value = "/queryall", method = GET, produces = "application/ ...
- 067-PHP使用匿名函数
<?php $func=function ($x,$y){ //匿名函数与变量绑定 return $x+$y; }; echo '5+6='.$func(5,6); //使用匿名函数 echo ...
- 第三节MapStruct翻译--Defining a mapper
第三节MapStruct--Defining a mapper 在这一章节你将学到如何用mapstruct和它的一些必要的操作选项来定义一个bean mapper. 3.1 Basic mapping ...
- ACM-奇特的立方体
题目描述:奇特的立方体 任意给出8个整数,将这8个整数分别放在一个立方体的八个顶点上,要求检验每个面上的四个数之和相等这个条件能否被满足. 输入 一次输入8个整数 输出 YES或者NO YES表示可能 ...
- 【剑指Offer】面试题09. 用两个栈实现队列
题目 用两个栈实现一个队列.队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能.(若队列中没有元素,delete ...
- UVA - 10003 Cutting Sticks(切木棍)(dp)
题意:有一根长度为L(L<1000)的棍子,还有n(n < 50)个切割点的位置(按照从小到大排列).你的任务是在这些切割点的位置处把棍子切成n+1部分,使得总切割费用最小.每次切割的费用 ...