BFS与DFS常考算法整理
BFS与DFS常考算法整理
- Preface
BFS(Breath-First Search,广度优先搜索)与DFS(Depth-First Search,深度优先搜索)是两种针对树与图数据结构的遍历或搜索算法,在树与图相关算法的考察中是非常常见的两种解题思路。
Definition of DFS and BFS
DFS的wikipedia定义:
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking.
BFS的wikipedia定义:
Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph, sometimes referred to as a ‘search key’[1]), and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level.
It uses the opposite strategy as depth-first search, which instead explores the highest-depth nodes first before being forced to backtrack and expand shallower nodes.
So obviously, as their name suggest, DFS focuses on ‘depth’ when searching or traversing while BFS focuses on ‘breath’.
By the way, because of DFS’s feature, it’s easy to relate it with ‘Backtracking’ algorithm as the wiki definition mentions. The relationship between DFS and backtracking is well explained by Reed Copsey on StackOverflow:
Backtracking is a more general purpose algorithm.
Depth-First search is a specific form of backtracking related to searching tree structures. From Wikipedia:
One starts at the root (selecting some node as the root in the graph case) and explores as far as possible along each branch before backtracking.
It uses backtracking as part of its means of working with a tree, but is limited to a tree structure.
Backtracking, though, can be used on any type of structure where portions of the domain can be eliminated - whether or not it is a logical tree. The Wiki example uses a chessboard and a specific problem - you can look at a specific move, and eliminate it, then backtrack to the next possible move, eliminate it, etc.
How to Implement DFS and BFS
DFS
In tree structure, DFS means we always start from a root node and try to reach the leaf node as direct as possible before we have to backtrack.

Order in which the nodes are visited
In graph, DFS means we start from a random assigned node in the graph, and explores as far as possible along the branch before we have to backtrack.
So the key points for DFS are:
- How to explore as far as possible?
- How to backtrack?
How to explore as far as possible
Normally, for tree node, it would have left child or right child, so we would continuously go on exploring current node’s child node until we encounter a null node, then we go back to last node. Repeat above procedures until all nodes have been visited.
for graph node, we do the similar exploration: explore as further as possible according to the representation of graph (adjacency list, adjacency matrix or incidence matrix) until we find no more node that hasn’t been visited and connected with current node, then we go back to last node. Repeat above procedures until all nodes have been visited.
How to backtrack/go back?
‘Go back’ generally can be realized using data structure ——stack—— or by recursion. And if we use stack, it means we would need to push each node we visited in the process of exploring each branch, and pop when we can’t explore further starting from current node.
BFS
In tree structure, BFS means we always start from a root node and try to all the other nodes in the same breath before we further try exploring nodes at next depth level. (The same explanation for graph)
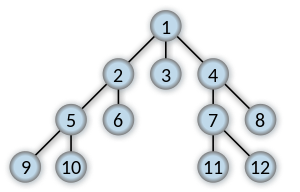
Order in which the nodes are visited
So the key points for BFS are:
- How to explore all nodes of same depth level?
How to explore all nodes of same depth level?
We can use a queue to do this: Starting from root node of a tree (Or a random node in a graph), we add visit all nodes connected with the starting node and add them to the queue. Then, we poll node from queue one by one and repeat above procedures until all nodes have been visited.
Typical Leetcode Prbolems
DFS
Path Sum II
Given a binary tree and a sum, find all root-to-leaf paths where each path’s sum equals the given sum.
Note: A leaf is a node with no children.
Example:
Given the below binary tree and sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1Return:
[
[5,4,11,2],
[5,8,4,5]
]- My Answer
package medium2;
import java.util.ArrayList;
import java.util.List;
/**
* @author Tom Qian
* @email tomqianmaple@outlook.com
* @github https://github.com/bluemapleman
* @date 2018年6月7日
*/
public class PathSumII
{
// DFS: make use of recursion to backtrack
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> ans=new ArrayList<List<Integer>>();
if(root==null)
return ans;
int goal=sum-root.val;
if(goal==0) {
if(root.left==null && root.right==null) {
List<Integer> tempList=new ArrayList<>();
tempList.add(root.val);
ans.add(tempList);
return ans;
}
}
List<List<Integer>> temp;
if((temp=pathSum(root.left, goal)).size()!=0) {
for(List<Integer> list:temp) {
list.add(0, root.val);
ans.add(list);
}
}
if((temp=pathSum(root.right, goal)).size()!=0) {
for(List<Integer> list:temp) {
list.add(0,root.val);
ans.add(list);
}
}
return ans;
}
}
Convert Sorted List to Binary Search Tree
Given a singly linked list where elements are sorted in ascending order, convert it to a height balanced BST.
For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example:
Given the sorted linked list: [-10,-3,0,5,9],
One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:
0
/ \
-3 9
/ /
-10 5- My Answer
package medium2;
/**
* @author Tom Qian
* @email tomqianmaple@outlook.com
* @github https://github.com/bluemapleman
* @date 2018年6月11日
*/
public class ConvertSortedListtoBinarySearchTree
{
// DFS: make use of recursion to backtrack
// find the middle node of sorted linked list, and take it as the root node of the BST.
public TreeNode sortedListToBST(ListNode head) {
if(head==null)
return null;
ListNode slow=head,fast=head,followSlow=head;
boolean moveFlag=false;
while(fast!=null && fast.next!=null) {
if(moveFlag)
followSlow=followSlow.next;
moveFlag=true;
slow=slow.next;
fast=fast.next.next;
}
TreeNode root=new TreeNode(slow.val);
if(moveFlag) {
followSlow.next=null;
root.left=sortedListToBST(head);
root.right=sortedListToBST(slow.next);
}
return root;
}
}Course Schedule
There are a total of n courses you have to take, labeled from 0 to n-1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
Example 1:
Input: 2, [[1,0]]
Output: true
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0. So it is possible.Example 2:
Input: 2, [[1,0],[0,1]]
Output: false
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0, and to take course 0 you should
also have finished course 1. So it is impossible.Note:
1.The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented.
2.You may assume that there are no duplicate edges in the input prerequisites.
- My Answer
// DFS
public boolean canFinish(int numCourses, int[][] prerequisites) {
Map<Integer, List<Integer>> map=new HashMap<>();
for(int i=0;i<numCourses;i++)
map.put(i, new ArrayList<>());
for(int i=0;i<prerequisites.length;i++) {
map.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
// start DFS: detect if there is any circle in course graph, i.e. whether DFS starting from certain start point i would lead to the start point again.
for(int i=0;i<numCourses;i++) {
// Use a set to avoid infinite loop: when met same node twice, ignore it.
Set<Integer> set=new HashSet<>();
// Use a stack to backtrack
ArrayDeque<Integer> stack=new ArrayDeque<>();
List<Integer> preCourseList=map.get(i);
for(Integer preCourse:preCourseList)
stack.push(preCourse);
while(!stack.isEmpty()) {
int preCourse=stack.pop();
if(set.contains(preCourse))
continue;
else
set.add(preCourse);
if(preCourse==i)
return false;
else {
preCourseList=map.get(preCourse);
for(Integer tempPreCourse:preCourseList) {
stack.push(tempPreCourse);
}
}
}
}
return true;
}BFS
Course Schedule
- My Answer
// BFS
public boolean canFinish(int numCourses, int[][] prerequisites) {
Map<Integer, List<Integer>> map=new HashMap<>();
for(int i=0;i<numCourses;i++)
map.put(i, new ArrayList<>());
for(int i=0;i<prerequisites.length;i++) {
map.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
// start DFS: detect if there is any circle in course graph, i.e. whether BFS starting from certain start point i would lead to the start point again.
for(int i=0;i<numCourses;i++) {
// Use a set to avoid infinite loop: when met same node twice, ignore it.
Set<Integer> set=new HashSet<>();
// Use a queue to remember nodes of same depth level
ArrayDeque<Integer> queue=new ArrayDeque<>();
List<Integer> preCourseList=map.get(i);
for(Integer preCourse:preCourseList)
queue.add(preCourse);
while(!queue.isEmpty()) {
int preCourse=queue.poll();
if(set.contains(preCourse))
continue;
else
set.add(preCourse);
if(preCourse==i)
return false;
else {
preCourseList=map.get(preCourse);
for(Integer tempPreCourse:preCourseList) {
queue.add(tempPreCourse);
}
}
}
}
return true;
}Binary Tree Right Side View
Given a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example:
Input: [1,2,3,null,5,null,4]
Output: [1, 3, 4]
Explanation:
1 <---
/ \
2 3 <---
\ \
5 4 <---- My Answer
package medium2;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
/**
* @author Tom Qian
* @email tomqianmaple@outlook.com
* @github https://github.com/bluemapleman
* @date 2018年6月12日
*/
public class BinaryTreeRightSideView
{
public List<Integer> rightSideView(TreeNode root) {
List<Integer> ans=new ArrayList<>();
if(root==null)
return ans;
ans.add(root.val);
ArrayDeque<TreeNode> queue1=new ArrayDeque<>(),queue2=new ArrayDeque<>();;
queue1.add(root);
while(!queue1.isEmpty() || !queue2.isEmpty()){
TreeNode rightestNode=null;
if(!queue1.isEmpty()) {
while(!queue1.isEmpty()) {
TreeNode fatherNode=queue1.poll();
if(fatherNode.right!=null) {
queue2.add(fatherNode.right);
if(rightestNode==null)
rightestNode=fatherNode.right;
}
if(fatherNode.left!=null) {
queue2.add(fatherNode.left);
if(rightestNode==null)
rightestNode=fatherNode.left;
}
}
}else{
while(!queue2.isEmpty()) {
TreeNode fatherNode=queue2.poll();
if(fatherNode.right!=null) {
queue1.add(fatherNode.right);
if(rightestNode==null)
rightestNode=fatherNode.right;
}
if(fatherNode.left!=null) {
queue1.add(fatherNode.left);
if(rightestNode==null)
rightestNode=fatherNode.left;
}
}
}
if(rightestNode!=null)
ans.add(rightestNode.val);
}
return ans;
}
}.
BFS与DFS常考算法整理的更多相关文章
- Leetcode——二叉树常考算法整理
二叉树常考算法整理 希望通过写下来自己学习历程的方式帮助自己加深对知识的理解,也帮助其他人更好地学习,少走弯路.也欢迎大家来给我的Github的Leetcode算法项目点star呀~~ 二叉树常考算法 ...
- Leetcode——回溯法常考算法整理
Leetcode--回溯法常考算法整理 Preface Leetcode--回溯法常考算法整理 Definition Why & When to Use Backtrakcing How to ...
- C++常考算法
1 strcpy, char * strcpy(char* target, char* source){ // 不返回const char*, 因为如果用strlen(strcpy(xx,xxx)) ...
- c++常考算法知识点汇总
前言:写这篇博客完全是给自己当做笔记用的,考虑到自己的c++基础不是很踏实,只在大一学了一学期,c++的面向对象等更深的知识也一直没去学.就是想当遇到一些比较小的知识,切不值得用一整篇 博客去记述的时 ...
- .NET面试常考算法
1.求质数 质数也成为素数,质数就是这个数除了1和他本身两个因数以外,没有其他因数的数,叫做质数,和他相反的是合数, 就是除了1和他本身两个因数以外,还友其他因数的数叫做合数. 1 nam ...
- JS-常考算法题解析
常考算法题解析 这一章节依托于上一章节的内容,毕竟了解了数据结构我们才能写出更好的算法. 对于大部分公司的面试来说,排序的内容已经足以应付了,由此为了更好的符合大众需求,排序的内容是最多的.当然如果你 ...
- 近5年常考Java面试题及答案整理(三)
上一篇:近5年常考Java面试题及答案整理(二) 68.Java中如何实现序列化,有什么意义? 答:序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化.可以对流化后的对象进行读写 ...
- 近5年常考Java面试题及答案整理(二)
上一篇:近5年常考Java面试题及答案整理(一) 31.String s = new String("xyz");创建了几个字符串对象? 答:两个对象,一个是静态区的"x ...
- 面试常考的常用数据结构与算法(zz)
数据结构与算法,这个部分的内容其实是十分的庞大,要想都覆盖到不太容易.在校学习阶段我们可能需要对每种结构,每种算法都学习,但是找工作笔试或者面试的时候,要在很短的时间内考察一个人这方面的能力,把每种结 ...
随机推荐
- 安卓权威编程指南 挑战练习 25章 深度优化 PhotoGallery 应用
你可能已经注意到了,提交搜索时, RecyclerView 要等好一会才能刷新显示搜索结果.请接受挑战,让搜索过程更流畅一些.用户一提交搜索,就隐藏软键盘,收起 SearchView 视图(回到只显示 ...
- SpringBoot快速上手系列01:入门
1.环境准备 1.1.Maven安装配置 Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件. 下载Maven可执行文件 cd /usr/local ...
- Docker实战之Zookeeper集群
1. 概述 这里是 Docker 实战系列第四篇.主要介绍分布式系统中的元老级组件 Zookeeper. ZooKeeper 是一个开源的分布式协调服务,是 Hadoop,HBase 和其他分布式框架 ...
- Electron打包H5网页为桌面运行程序
一.安装配置环境 Electron(一种桌面应用程序运行时),Electron 把 Chromium 和 Node 合并到一个单独的运行时里面,很适合开发桌面 web 形式的应用程序,通过Node它提 ...
- 【前端性能优化】高性能JavaScript整理总结
高性能JavaScript整理总结 关于前端性能优化:首先想到的是雅虎军规34条然后最近看了<高性能JavaScript>大概的把书中提到大部分知识梳理了下并加上部分个人理解这本书有参考雅 ...
- JZOJ 1349. 最大公约数 (Standard IO)
1349. 最大公约数 (Standard IO) Time Limits: 1000 ms Memory Limits: 65536 KB Description 小菜的妹妹小诗就要读小学了!正所谓 ...
- java多线程基础API
本次内容主要讲认识Java中的多线程.线程的启动与中止.yield()和join.线程优先级和守护线程. 1.Java程序天生就是多线程的 一个Java程序从main()方法开始执行,然后按照既定的代 ...
- 什么是YUM
什么是Yum Yum(全称为 Yellow dog Updater, Modified)是一个在RedHat以及CentOS等Linux系统中的Shell前端软件包管理器.基于RPM包管理,能够从指定 ...
- [转载]Linux服务器丢包故障的解决思路及引申的TCP/IP协议栈理论
Linux服务器丢包故障的解决思路及引申的TCP/IP协议栈理论 转载至:https://www.sdnlab.com/17530.html 我们使用Linux作为服务器操作系统时,为了达到高并发处理 ...
- C++ 指针实现字符串倒序排列
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #include <coni ...