JMM内存模型、CPU缓存一致性原则(MESI)、指令重排、as-if-serial、happen-before原则
CPU内部结构划分
控制单元
运算单元
存储单元
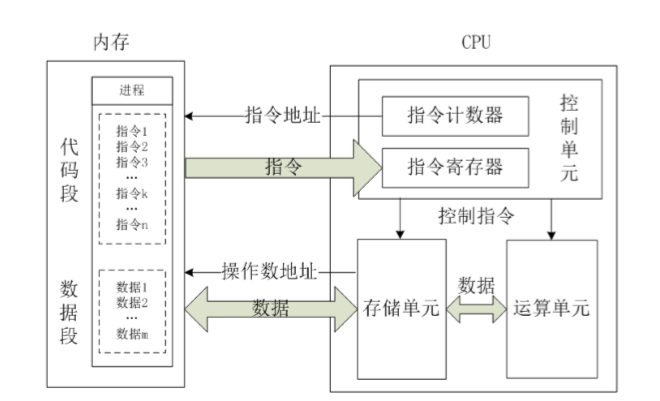
计算机多硬件多CPU结构:
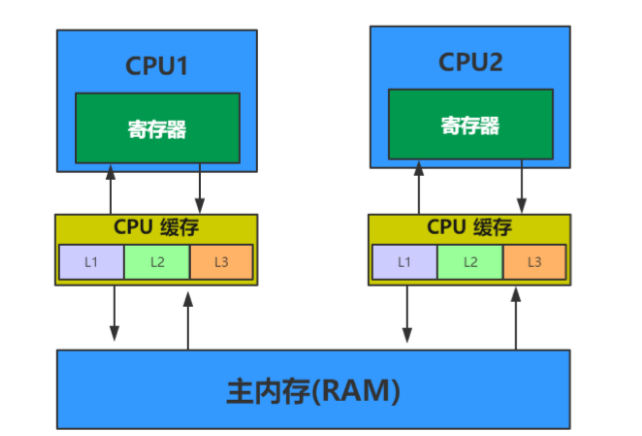
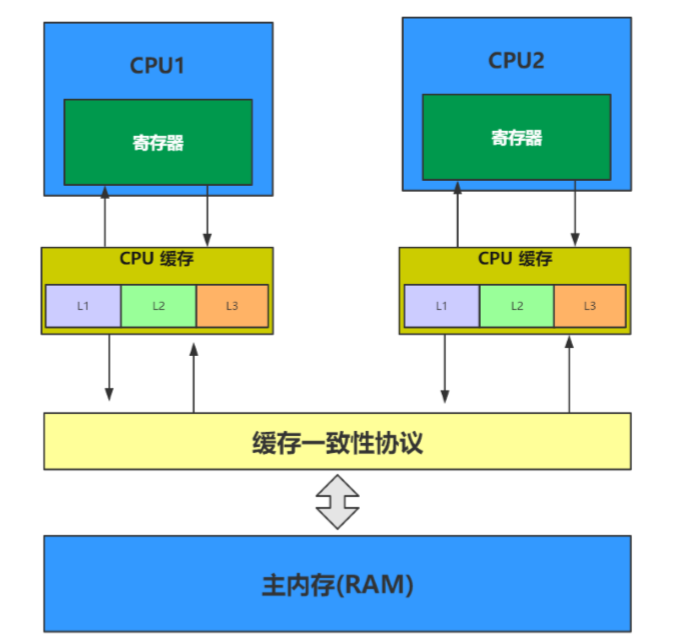
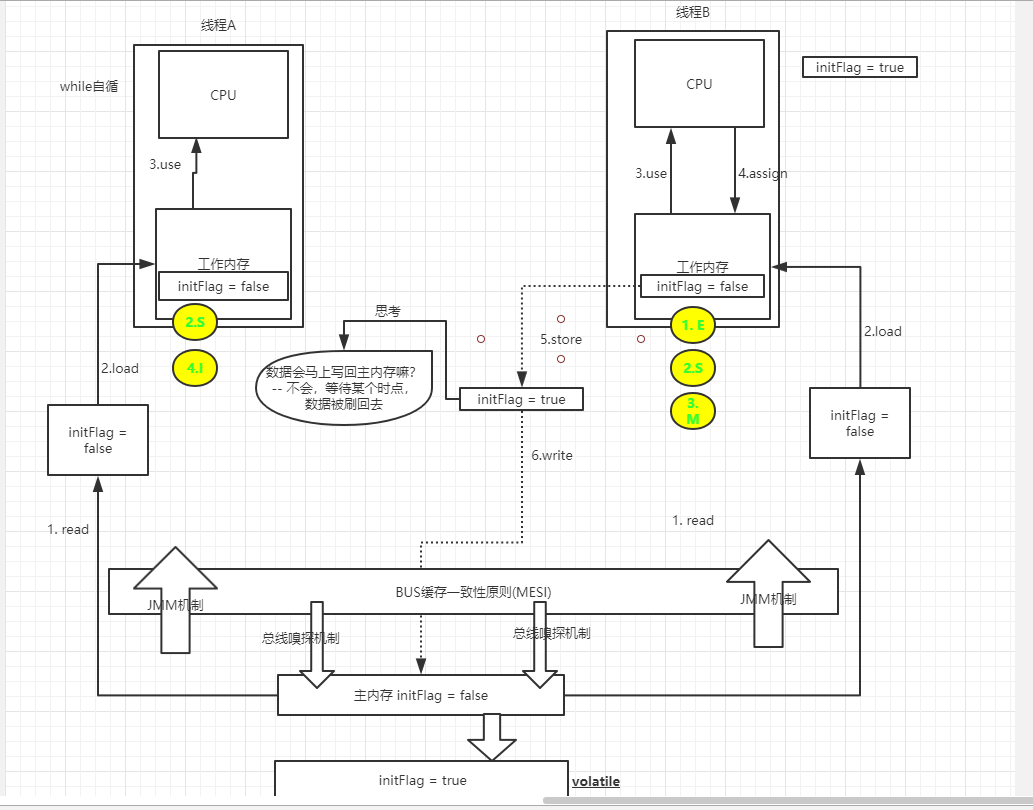
CPU缓存一致性原则
JMM同步八种操作介绍:
(1)lock(锁定):作用于主内存的变量,把一个变量标记为一条线程独占状态
(2)unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的 变量才可以被其他线程锁定
(3)read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中, 以便随后的load动作使用
(4)load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作 内存的变量副本中
(5)use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
(6)assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量
(7)store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
(8)write(写入):作用于工作内存的变量,它把store操作从工作内存中的一个变量的值传送 到主内存的变量中
如果要把一个变量从主内存中复制到工作内存中,就需要按顺序地执行read和load操作, 如果把变量从工作内存中同步到主内存中,
就需要按顺序地执行store和write操作。但Java内 存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。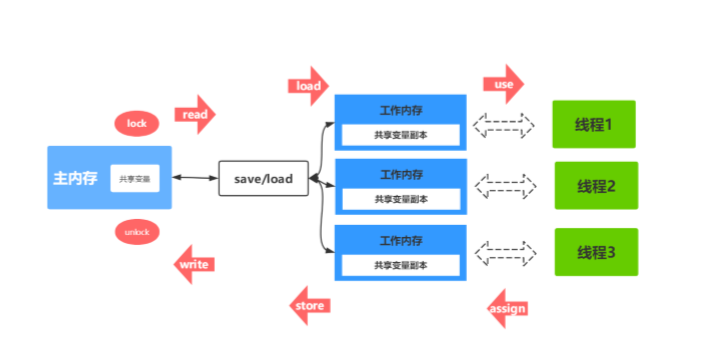
JMM三大特性
原子性
汇编指令 --原子比较和交换在底层的支持 cmp-chxg
解决办法: Synchronized Lock锁机制 保证任意时刻只有一个线程访问该代码块。
public class VolatileAtomicSample {
private static volatile int counter = 0; // volatile无法保证原子性
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(()->{
for (int j = 0; j < 1000; j++) {
counter++; //不是一个原子操作,第一轮循环结果是没有刷入主存,这一轮循环已经无效
//1 load counter 到工作内存
//2 add counter 执行自加
}
});
thread.start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter);
}
}
启动10个线程,每个线程执行自增步骤,count++ 是非原子性的。volatile保证数据的可见性,同时存在CPU缓存锁机制以及MESI缓存分布式协议,最后打印的值 <= 10000.
CPU为了提升性能,会存在指令编排机制。也就会出现内存屏障 见有序性详解。
可见性 volatile -- LOCK缓存行(有且仅有一个线程会占有缓存行) + CPU缓存一致性原则MESI(独占E-->共享S-->修改M--->其他失效I)
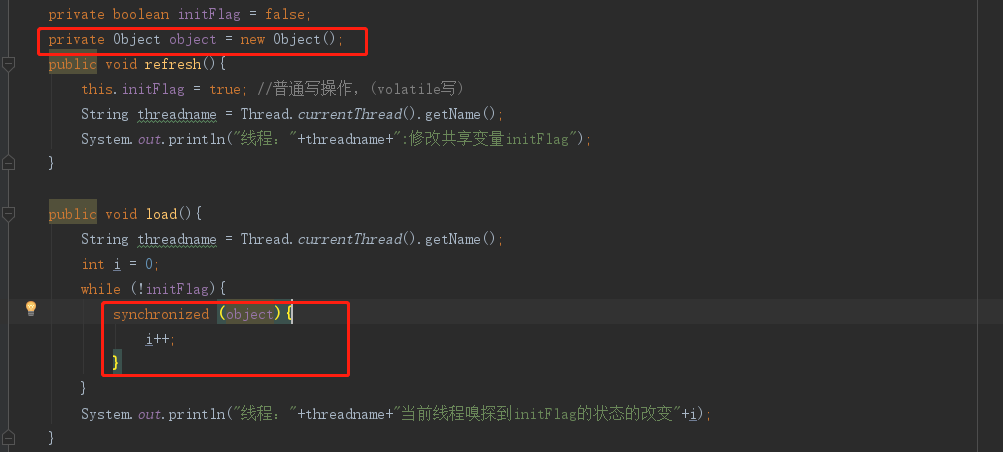
public class VolatileVisibilitySample {
private boolean initFlag = false;
public void refresh(){
this.initFlag = true; //普通写操作,(volatile写)
String threadname = Thread.currentThread().getName();
System.out.println("线程:"+threadname+":修改共享变量initFlag");
}
public void load(){
String threadname = Thread.currentThread().getName();
int i = 0;
while (!initFlag){
i++;
}
System.out.println("线程:"+threadname+"当前线程嗅探到initFlag的状态的改变"+i);
}
public static void main(String[] args){
VolatileVisibilitySample sample = new VolatileVisibilitySample();
Thread threadA = new Thread(()->{
sample.refresh();
},"threadA");
Thread threadB = new Thread(()->{
sample.load();
},"threadB");
threadB.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
threadA.start();
}
}
分析如下: 只会打印 "线程:threadA:修改共享变量initFlag".
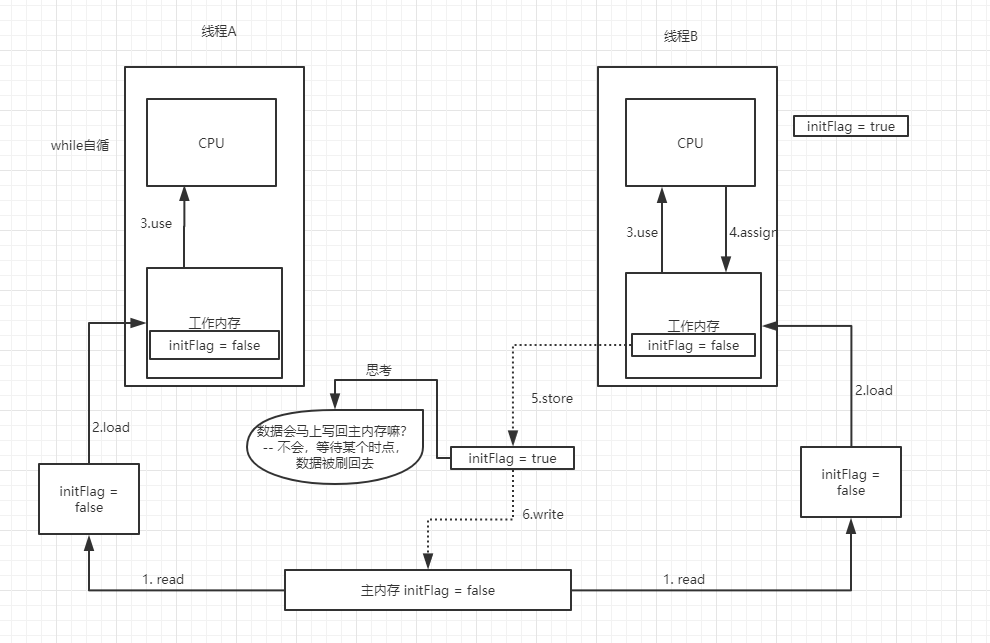
修改:
因为在线程A里面增加了锁机制,同时CPU自身也存在时间片切片,导致线程上下文切换,initFlag会从内存中读取线程B更新的值。
会把线程B嗅探机制打印出来。打印如下:
线程:threadA:修改共享变量initFlag
线程:threadB当前线程嗅探到initFlag的状态的改变25747425
修改2:使用volatile关键字 ====> JMM缓存一致性原则(MESI) + LOCK缓存行
有序性
-- 指令重排 ---> 内存屏障(volatile禁止重排优化 )
查看汇编指令:-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)。 即在单线程情况下,不能改变程序运行的结果
程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
double p = 3.14; //
double r = 1.0; //
double area = p * r * r; //3计算面积
上面例子中1,2存在指令重排操作,但是1,2不能和第三步存在指令重排操作,否则将改变程序运行的结果。
happen-before原则
1、 程序顺序原则,即在一个线程内必须保证语义串行性,也就是说按照代码顺序执行
2. 锁规则 解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)
3. volatile规则 volatile变量的写,先发生于读,这保证了volatile变量的可见性,简单的理解就是,volatile变量在每次被线程访问时,都强迫从主内存中读该变量的值,
而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时刻,不同的线程总是能够看到该变量的最新值。
4. 线程启动原则 线程的start()方法先于他的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行了start方法之时,线程A对共享变量的修改对线程B可见。
5. 传递性 A先于B,B先于C,那么A必然先于C
6. 线程终止原则 线程的所有操作先于线程的终结。Thread.join()方法的作用就是等待当前执行的线程的终止。
假设在线程B终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见。
7. 线程中断规则
对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
8、对象终结规则 对象的构造函数执行,结束先于finalize()方法 指令重排发生在什么阶段?
1. 编译阶段,字节码编译成机器指令码阶段。
2. CPU运行时,执行指令
volatile禁止重排优化 ---内存屏障(Memory Barrier)
下图是JMM针对编译器制定的volatile重排序规则表
指令重排code示例
/**
* 并发场景下存在指令重排
*/
public class VolatileReOrderSample {
private static int x = 0, y = 0;
private static volatile int a = 0, b =0;
static Object object = new Object(); public static void main(String[] args) throws InterruptedException {
int i = 0; for (;;){
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread t1 = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
shortWait(10000);
a = 1; //是读还是写?store,volatile写
//storeload ,读写屏障,不允许volatile写与第二步volatile读发生重排
x = b; // 读还是写?读写都有,先读volatile,写普通变量
//分两步进行,第一步先volatile读,第二步再普通写
}
}, "t1");
Thread t2 = new Thread(new Runnable() {
public void run() {
b = 1;
UnsafeInstance.reflectGetUnsafe().storeFence();
y = a;
}
});
t1.start();
t2.start();
t1.join();
t2.join(); /**
* cpu或者jit对我们的代码进行了指令重排?
* 1,1
* 0,1
* 1,0
* 0,0
*/
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
} } public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
} }
如果不要volatile去增加内存屏障?如何解决?
-- 手动增加屏障,通过Unsafe来解决.
loadFence() storeFence fulFence() .
Unsafe通过BootStwp被加载,否则抛异常。JVM的双亲委派机制
通过反射来获取。
public class UnsafeInstance {
public static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
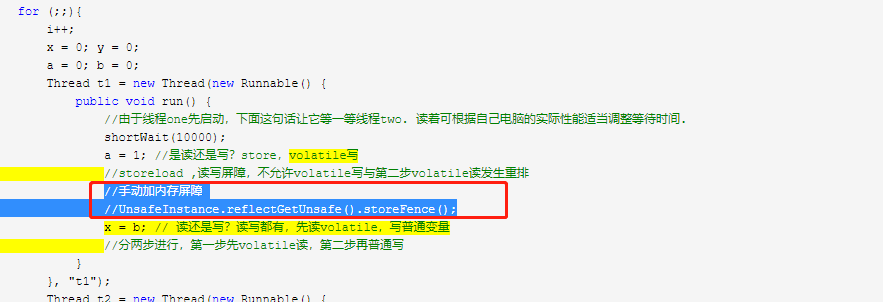
内存屏障 Memory Barrier
1.写写storestore 2.写读storeload 3.读写loadstore 4.读读loadload

volatile禁止重排优化
volatile关键字另一个作用就是禁止指令重排优化,从而避免多线程环境下程序出现乱序 执行的现象,关于指令重排优化前面已详细分析过,这里主要简单说明一下volatile是如何实 现禁止指令重排优化的。先了解一个概念,内存屏障(Memory Barrier)。
内存屏障,又称内存栅栏,是一个CPU指令,它的作用有两个,一是保证特定操作的执行 顺序,二是保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)。由于编译 器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则会告诉编译器 和CPU,
不管什么指令都不能和这条Memory Barrier指令重排序,也就是说通过插入内存屏 障禁止在内存屏障前后的指令执行重排序优化。Memory Barrier的另外一个作用是强制刷出 各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的新版本。总之, volatile变量正是通过内存屏障实现其在内存中的语义,即可见性和禁止重排优化。
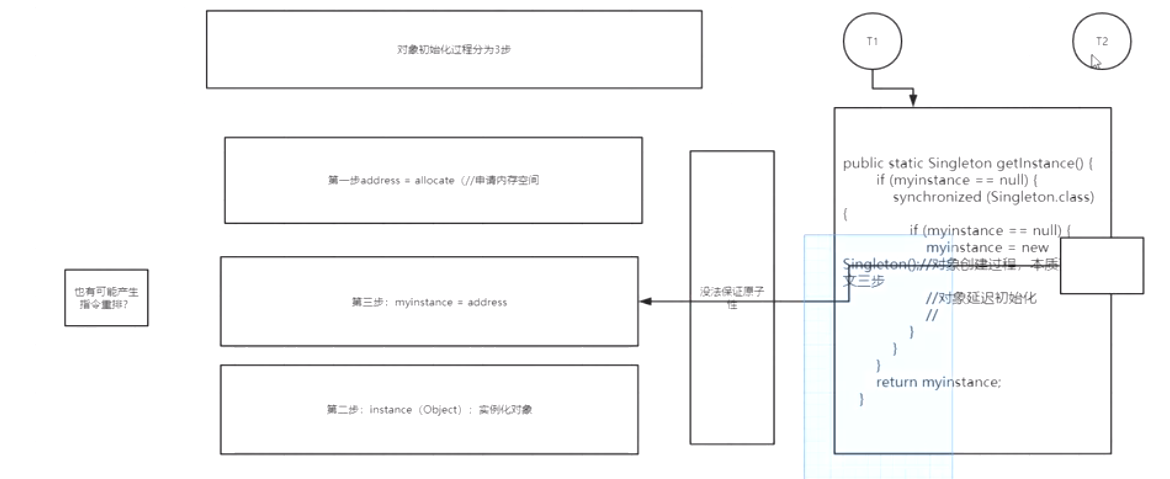
下面看一 个非常典型的禁止重排优化的例子DCL,如下:
public class DoubleCheckLock {
private static DoubleCheckLock instance;
private DoubleCheckLock(){}
public static DoubleCheckLock getInstance(){ //第一次检测
if (instance==null){ //同步 synchronized (DoubleCheckLock.class)
{ if (instance == null){ //多线程环境下可能会出现问题的地方
instance = new DoubleCheckLock();
}
}
}
return instance;
}
}
上述代码一个经典的单例的双重检测的代码,这段代码在单线程环境下并没有什么问题, 但如果在多线程环境下就可以出现线程安全问题。原因在于某一个线程执行到第一次检测,读 取到的instance不为null时,instance的引用对象可能没有完成初始化。 总线风暴
问题:大量使用cas和volatile,会有什么问题? 高并发情况下为什么会产生总线风暴?
1. CAS ---> CPU工作内存与主内存产生大量的交互
2. volatile ---> 产生大量的无效的工作内存变量
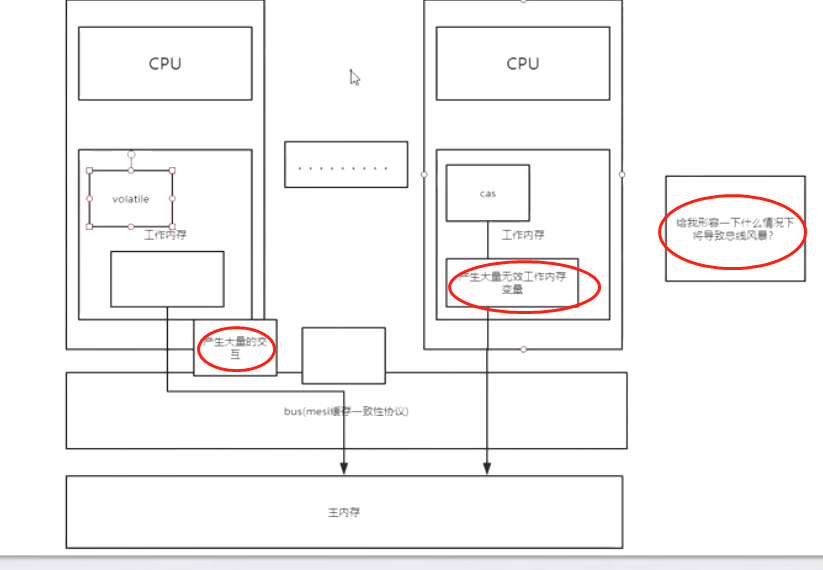
解决办法:
synchronized 关键字 单例设计---高并发(加双重锁)
public class Singleton {
/**
* 查看汇编指令
* -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp
*/
private volatile static Singleton myinstance;
public static Singleton getInstance() {
if (myinstance == null) {
synchronized (Singleton.class) {
if (myinstance == null) {
myinstance = new Singleton();//对象创建过程,本质可以分文三步
//对象延迟初始化
//
}
}
}
return myinstance;
}
public static void main(String[] args) {
Singleton.getInstance();
}
}
JMM内存模型、CPU缓存一致性原则(MESI)、指令重排、as-if-serial、happen-before原则的更多相关文章
- 基础篇:深入JMM内存模型解析volatile、synchronized的内存语义
目录 1 java内存模型,JMM(JAVA Memory Model) 2 CPU高速缓存.MESI协议 3 指令重排序和内存屏障指令 4 happen-before原则 5 synchronize ...
- JMM内存模型详解(一)
本文开始死磕JMM(Java内存模型)由于知识点较多,分来写 该文为JMM第一篇 技术往往是枯燥的,本文文字较多 1. JMM是什么? 其实JMM很好理解,我简单的解释一下,在Java多线程中我们经常 ...
- JVM学习(七)JMM内存模型
一.什么是JMM 概念:Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能 ...
- JMM内存模型相关笔记整理
JMM 内存模型是围绕并发编程中原子性.可见性.有序性三个特征来建立的 原子性:就是说一个操作不能被打断,要么执行完要么不执行,类似事务操作,Java 基本类型数据的访问大都是原子操作,long 和 ...
- 基于JVM原理、JMM模型和CPU缓存模型深入理解Java并发编程
许多以Java多线程开发为主题的技术书籍,都会把对Java虚拟机和Java内存模型的讲解,作为讲授Java并发编程开发的主要内容,有的还深入到计算机系统的内存.CPU.缓存等予以说明.实际上,在实际的 ...
- JAVA并发编程的艺术 JMM内存模型
锁的升级和对比 java1.6为了减少获得锁和释放锁带来的性能消耗,引入了"偏向锁"和"轻量级锁". 偏向锁 偏向锁为了解决大部分情况下只有一个线程持有锁的情况 ...
- JMM内存模型+volatile+synchronized+lock
硬件内存模型: Java内存模型: 每个线程都有一个工作内存,线程只可以修改自己工作内存中的数据,然后再同步回主内存,主内存由多个内存共享. 下面 8 个操作都是原子的,不可再分的: 1) lock ...
- 多线程与Java的JMM内存模型
共享内存模型指的就是Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入时,能对另一个线程可见.从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存( ...
- JMM 内存模型 与 volatile 关键字
内存模型 线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory). 本地内存中存储了该线程以读/写共享变量的副本. 不同线程之间无法相互 ...
随机推荐
- win+E 出现“未指定错误“修复方案
windows7 (win7) win+E 出现"未指定错误----"解决方法 出现该问题的原因:大家使用某种注册表优化所致,如使用优化大师等优化注册表-- 解决方法: 1.如果优 ...
- numpy的基础计算2
import numpy as np A = np.arange(14,2,-1).reshape((3,4)) #平均值 print(np.mean(A)) print(A.mean()) prin ...
- 使用itchat发送天气信息
微信发送当日天气情况 念头萌生 之前在浏览网站的时候发现了篇文章「玩转树莓派」为女朋友打造一款智能语音闹钟,文章中介绍了使用树莓派打造一款语音播报天气的闹钟. 当时就想照着来,也自己做个闹钟.因为一直 ...
- 从社交到IP 庞大手游玩家大军迈向社群化之路
庞大手游玩家大军迈向社群化之路" title="从社交到IP 庞大手游玩家大军迈向社群化之路"> 移动互联网及相关智能设备的快速迭进,不仅改变了我们的生活方式,也彻 ...
- ECMA5中定义的对象属性特性和方法
ECMA5规定了只有内部才有的特性,描述了属性的各种特征,这些特性用于实现JavaScript引擎,因此在Js中不能直接访问他们.为了标识特性,我们一般会他们放入两对方括号中. ECMAScript中 ...
- nexus7入手
平板一直关注了很久了,关键是不知道平板对我来说,拿它来做什么用.所以,一直也就是关注,也没有决心买了. 终于这次出手了,N7,到货了! 照片是原生的android系统,不习惯,不习惯,直接用刷机精灵, ...
- wepack环境配置1之node的安装
.向往已久的webpack终于配好了.. 1.要安装webpack,首先需要安装nodejs nodejs下载地址:https://nodejs.org/en/ 下载完成后,一步步安装即可,我是安装到 ...
- Java入门教程八(面向对象)
对象概念 一切皆是对象.把现实世界中的对象抽象地体现在编程世界中,一个对象代表了某个具体的操作.一个个对象最终组成了完整的程序设计,这些对象可以是独立存在的,也可以是从别的对象继承过来的.对象之间通过 ...
- Javascript学习笔记-基本概念-操作符
1.一元操作符 (1)递增和递减操作符 只能操作一个值的操作符叫一元操作符. var age = 29; ++age; var age = 29; --age; var age = 29; var a ...
- CollectionUtils工具类
CollectionUtils工具类 这篇讲的CollectionUtils工具类是在apache下的,可以使代码更加简洁和安全. 使用前需导入依赖 <dependency> <gr ...