【每周小项目】使用 puppeteer 插件爬取动态网站
0. 前言
这两天对爬虫开始感兴趣,最开始是源于天涯的一个房价神贴,盖了上万层,追着读了好久。天涯网页端的“只看楼主”需要会员,手机端可以“只看楼主”,但是体验不太好,记录也不方便,于是决定把楼主发言单独爬下来,既可以保存,也可以检索。
最开始想法很简单,对每一页进行元素检索,发帖人与楼主名字匹配的,就把里面的content拷出来。
首先在网上找到的工具是cheerio插件,它在读取网站之后,将网站内容存下来,通过元素选择器进行内容选取。在使用递归后,还能解决翻页问题。
事实上也确实如此,通过简单几步操作,就把楼主的发言保存了下来,也让我对爬虫产生了兴趣。
问题
cheerio确实简单好用,在应对简单静态网页时没有问题。但对付具备一定反爬机制的网站就无能为力了。比如cheerio解决翻页问题,靠的是动态修改url链接。但是有的网站,比如我最爱的煎蛋,它的网页链接页码是乱码,就没办法实现自动翻页。再比如有的房产网站,在罗列在售资源时,为了用户体验,使用了懒加载,只有将页面滚动到底部后,才能触发加载。
以上种种实际上就是cheerio对于网页操作是无能为力的。
解决
在网上查找对付懒加载的方法时,发现了puppeteer插件。谷歌浏览器在17年自行开发了Chrome Headless特性,并与之同时推出了puppeteer,本质上就是一个不含界面的浏览器,有点像电脑的终端,所有操作都通过代码进行操作。
这样,我们就可以在对网站进行检索之前,操作指定元素滚动到底部,以触发更多信息。或者在需要翻页的时候,操作代码对翻页按钮进行点击,然后对翻页后的页面进行相关处理。
1. 下载与引包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2. 使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3. 爬过的几个坑
page.evaluate 的传参问题
因为打开的这个 page 只是一个木偶,并不是真正的浏览器页面,所以在这个页面上的操作与一般页面上的操作有差异。
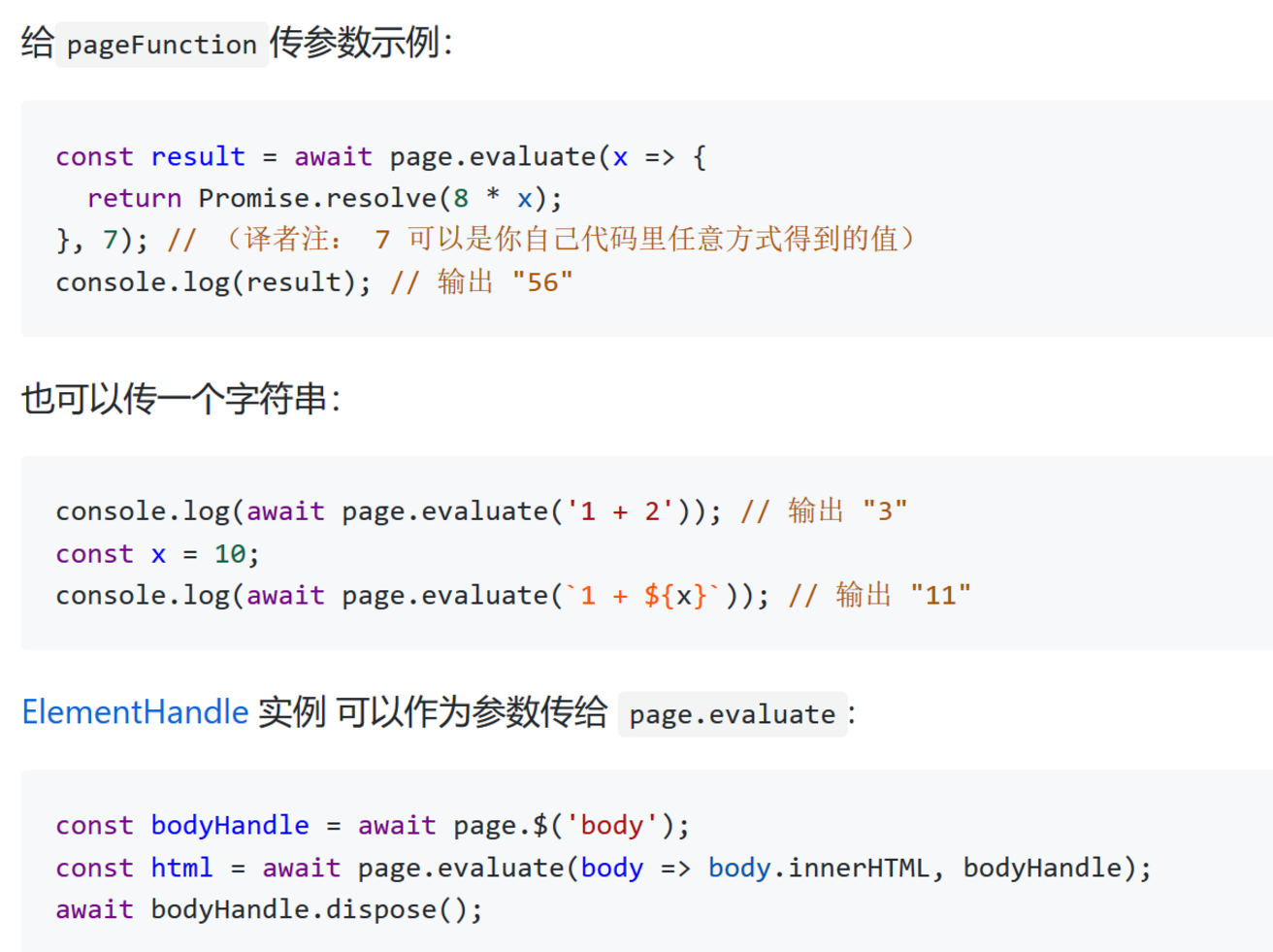
官方文档里说,这个参数是这样的。在实际使用中,可以传一个字符串变量,但是到更复杂一点的,比如‘fs’,自定义外部函数时,都无法读取。
这也是我建议在第6步,对页面操作完成后,统一对结果进行处理。(主要是因为我没有解决这个问题,所以认怂绕开走了……)
元素操作问题
puppeteer中,最重要的函数执行和要素选择都与一般浏览器上操作有些区别,这里有些坑要爬,现在我也说不清楚。
【每周小项目】使用 puppeteer 插件爬取动态网站的更多相关文章
- python3爬取动态网站图片
思路: 1.图片放在<image>XXX</image>标签中 2.利用fiddler抓包获取存放图片信息的js文件url 3.利用requests库获取html内容,然后获取 ...
- Python 爬虫练习项目——异步加载爬取
项目代码 from bs4 import BeautifulSoup import requests url_prefix = 'https://knewone.com/discover?page=' ...
- 用Python爬取斗鱼网站的一个小案例
思路解析: 1.我们需要明确爬取数据的目的:为了按热度查看主播的在线观看人数 2.浏览网页源代码,查看我们需要的数据的定位标签 3.在代码中发送一个http请求,获取到网页返回的html(需要注意的是 ...
- webmagic爬取渲染网站
最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下.发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|). 好了,废话少说 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- Golang+chromedp+goquery 简单爬取动态数据
目录 Golang+chromedp+goquery 简单爬取动态数据 Golang的安装 下载golang软件 解压golang 配置golang 重新导入配置 chromedp框架的使用 实际的代 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- phantomjs+selenium实现爬取动态网址
之前使用 selenium + firefox驱动浏览器来实现爬取动态网址,但是firefox经常更新,更新后时常会导致webdriver启动不来,所以改用phantomjs+selenium来改善一 ...
随机推荐
- 零基础HTML及CSS编码总结
任务目的 针对设计稿样式进行合理的HTML架构,包括以下但不限于: * 掌握常用HTML标签的含义.用法 能够基于设计稿来合理规划HTML文档结构 理解语义化,合理地使用HTML标签来构建页面 掌握基 ...
- python之路-基本数据类型之list列表
1.概述 列表是python的基本数据类型之一,是一个可变的数据类型,用[]方括号表示,每一项元素使用逗号隔开,可以装大量的数据 #先来看看list列表的源码写了什么,方法:按ctrl+鼠标左键点li ...
- Python 第一天学习记录
- bootstrapValidator验证的remote中data属性里获取select一直是默认值
budgetEditionNo:{ message:'版本号输入不正确' , validators:{ notEmpty:{ message:'版本号不能为空,请填写' } , remote:{ ur ...
- 峰哥说技术:01-Spring Boot介绍
Spring Boot深度课程系列 峰哥说技术—2020庚子年重磅推出.战胜病毒.我们在行动 Spring Boot介绍 A.Spring Boot是什么? 由于Spring是一个轻量级的企业开发框架 ...
- GPS同步时钟装置应用及选择
GPS同步时钟装置应用及选择 GPS是全球定位系统的简称,GPS具有全天时.全天候.高精度.定位和授时服务,GPS卫星授时成本低.安全可靠.覆盖范围广.GPS同步时钟装置,是指从GPS卫星上获取时间信 ...
- Python3对比合并Excel表格
##安装模块pip install pandas as pdpip install xlsxwriterpip install openpyxl ##带入模块import pandas as pdim ...
- php中的进程
pcntl扩展:主要的进程扩展,完成进程创建于等待操作. posix扩展:完成posix兼容机通用api,如获取进程id,杀死进程等. sysvmsg扩展:实现system v方式的进程间通信之消息队 ...
- C++ 判断两个圆是否有交集
#define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include <math.h> #include <easyx.h ...
- 结题报告--hih0CoderP1041
题目:点此 描述 小Hi和小Ho准备国庆期间去A国旅游.A国的城际交通比较有特色:它共有n座城市(编号1-n):城市之间恰好有n-1条公路相连,形成一个树形公路网.小Hi计划从A国首都(1号城市)出发 ...