python机器学习(2:KNN算法)
1、KNN
x1 = numpy.round(numpy.random.normal(115, 10, 100),2)
y1 = numpy.round(numpy.random.normal(95, 6,100),2)
x2 = numpy.round(numpy.random.normal(70, 10, 100),2)
y2 = numpy.round(numpy.random.normal(99, 6, 100),2)
a=[]
b=[]
for i in range(100):
a.append([x1[i],y1[i]])
for i in range(100):
b.append([x2[i],y2[i]])
c=a+b
dataset=array(c)labels=[]
for i in range(100):
labels.append('*')
for i in range(100):
labels.append('o')小编自定义两个待分类的数据,也以矩阵的形式存放入;
x=[82,94]
x=array(x)
y=[90,100]
y=array(y) 3、实现过程
# -*- coding:utf-8 -*-
import numpy
from numpy import *
import random
import pylab as pl
import operator
pl.figure(1)
pl.figure(2)
#计算样本的距离,预测类别
def classify(testdata,traindata,labels,k):
#testdate:待分类数集;traindate:分好类的数集;
#tile(a,(b,c)):将a的内容在行上复制b遍,列上复制c遍
trasize=traindata.shape[0] #得到其维数
tradis1=tile(testdata,(trasize,1))-traindata
tradis2=tradis1**2
tradis3=tradis2.sum(axis=1)
tradis=tradis3**0.5 #计算样本与训练数据的距离
sortdis=tradis.argsort()#排序
classcount={}#建立空字典
for i in range(k):#通过循环寻找k个近邻
votelabel=labels[sortdis[i]]
classcount[votelabel]=classcount.get(votelabel,0)+1
sortedclasscount=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sortedclasscount[0][0]#返回占最大比例的类别
x1 = numpy.round(numpy.random.normal(115, 10, 100),2)
y1 = numpy.round(numpy.random.normal(95, 6,100),2)
x2 = numpy.round(numpy.random.normal(70, 10, 100),2)
y2 = numpy.round(numpy.random.normal(99, 6, 100),2)
a=[]
b=[]
for i in range(100):
a.append([x1[i],y1[i]])
for i in range(100):
b.append([x2[i],y2[i]])
c=a+b
dataset=array(c) #将列表转化为矩阵
labels=[]
for i in range(100):
labels.append('*')
for i in range(100):
labels.append('o')
x=[82,94]
x=array(x)
y=[90,100]
y=array(y)
k=10
labelX=classify(x,dataset,labels,k)
labelY=classify(y,dataset,labels,k)
pl.figure(1)
pl.plot(x1,y1,'*')
pl.plot(x2,y2,'o')
pl.plot(82,94,'.')
pl.plot(96,100,'.')
pl.xlabel('X')
pl.ylabel('Y')
pl.figure(2)
pl.plot(x1,y1,'*')
pl.plot(x2,y2,'o')
pl.plot(82,94,labelX)
pl.plot(96,100,labelY)
pl.show()
4、实现结果
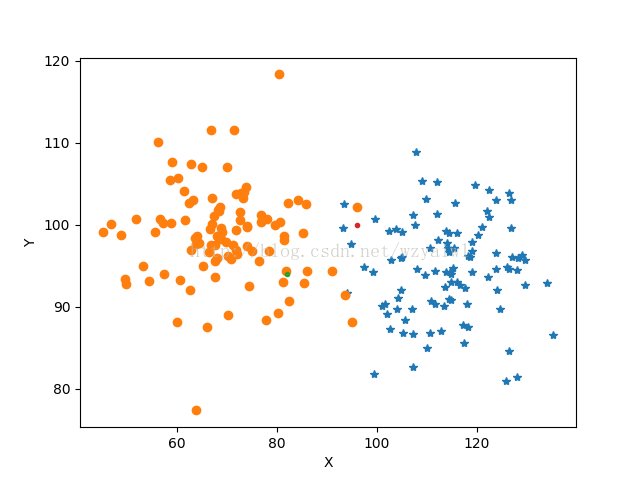
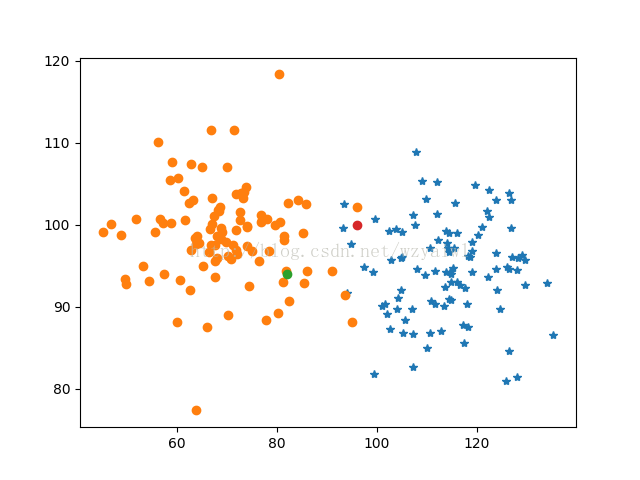
- 引入的数据一定要看清其类别,在这里就要注意列表与矩阵的转化;
- append([x1[i],y1[i]])括号里又加中括号是因为append一次只能添入一个元素
- 将列表转化为矩阵用array
- 矩阵的平方是将矩阵内每个元素平方,与线性代数不同
python机器学习(2:KNN算法)的更多相关文章
- 使用python模拟实现KNN算法
一.KNN简介 1.KNN算法也称为K邻近算法,是数据挖掘分类技术之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. 2.KNN算法的核心思想是如果一个样本 ...
- 菜鸟之路——机器学习之KNN算法个人理解及Python实现
KNN(K Nearest Neighbor) 还是先记几个关键公式 距离:一般用Euclidean distance E(x,y)√∑(xi-yi)2 .名字这么高大上,就是初中学的两点间的距离 ...
- 机器学习之KNN算法
1 KNN算法 1.1 KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- python机器学习的常用算法
Python机器学习 学习意味着通过学习或经验获得知识或技能.基于此,我们可以定义机器学习(ML)如下 - 它可以被定义为计算机科学领域,更具体地说是人工智能的应用,其为计算机系统提供了学习数据和从经 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
- Python简单实现KNN算法
__author__ = '糖衣豆豆' from numpy import * from os import listdir import operator #从列方向扩展 #tile(a,(size ...
- JavaScript机器学习之KNN算法
译者按: 机器学习原来很简单啊,不妨动手试试! 原文: Machine Learning with JavaScript : Part 2 译者: Fundebug 为了保证可读性,本文采用意译而非直 ...
- 机器学习笔记--KNN算法1
前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的狐朋狗友算法---KNN算法,为什么叫狐朋狗友算法呢,在这里我先卖个关子,且听我慢慢道来. 一 K ...
- 机器学习入门-Knn算法
knn算法不需要进行训练, 耗时,适用于多标签分类情况 1. 将输入的单个测试数据与每一个训练数据依据特征做一个欧式距离. 2. 将求得的欧式距离进行降序排序,取前n_个 3. 计算这前n_个的y值的 ...
随机推荐
- DAO三层架构及工厂模式
目录结构 1.在domain包中创建User实体类 package com.rick.domain; import java.util.Date; public class User { privat ...
- 实验吧-密码学-js(Chrome用console.log调试js)
题目就是js,可能就是一个js的代码,查看源码并复制,在Chrome中打开网页,审查元素. 将复制的代码输入,将eval改成console.log,再回车执行,就得到一段js代码. 代码中有Unico ...
- 基于python的小波阈值去噪算法
https://blog.csdn.net/alwaystry/article/details/52756051 发表于 2018-01-10 16:32:17 嵌入式设计应用 +关注 小波图像去噪原 ...
- App基本界面组件案例
今天的收获颇大呀,我发现了一个更高效快速的学习方法,如果真的是因为学习内容太多,无从下手的话,不妨去别人或者自己崇拜的大佬里的博客园里面转一转,你就会有意外的收获,不仅给你学习的压力,还更直观的给介绍 ...
- h5-任意元素居中
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- CodeForces - 350B(反向建图,)
B - Resort CodeForces - 350B B. Resort time limit per test 2 seconds memory limit per test 256 megab ...
- [De1CTF 2019]SSRF Me-MD5长度扩展攻击&CVE-2019-9948
0x00 打开题目查看源代码,开始审计 这里贴上网上师傅的博客笔记: https://xz.aliyun.com/t/6050 #! /usr/bin/env python #encoding=utf ...
- Python 安装modules问题及import问题
>>>modules问题 在学习Python的数据可视化时,安装了matplotlib,在安装完成后还特意在终端测试了一下,结果显示能正常import 但是在sublime Text ...
- Tomcat启动报内存溢出错误:java.lang.OutOfMemoryError: PermGen space
windows操作系统 找到D:\Tomcat-7\apache-tomcat-7.0.28\bin(解压安装的Tomcat)目录下的catalina.bat文件,打开该文件,找到下图所示的内容:添加 ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...