Innodb-内存架构与特性
参考文档
Innodb特性buffer_pool
http://mysql.taobao.org/monthly/2017/05/01/?spm=a2c4e.11153940.blogcont281249.10.5156506e7F6GpK
一.Innodb结构图
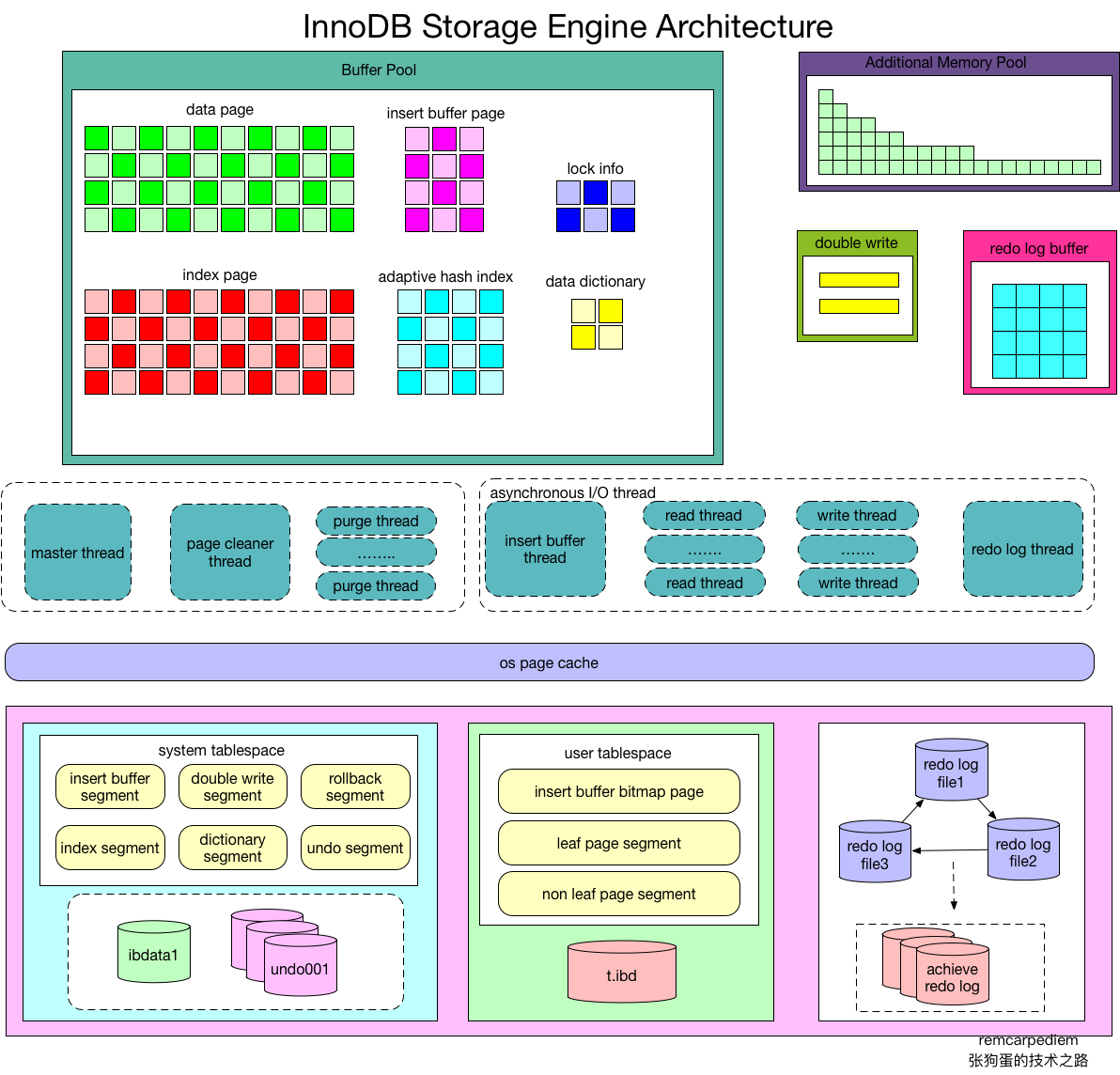
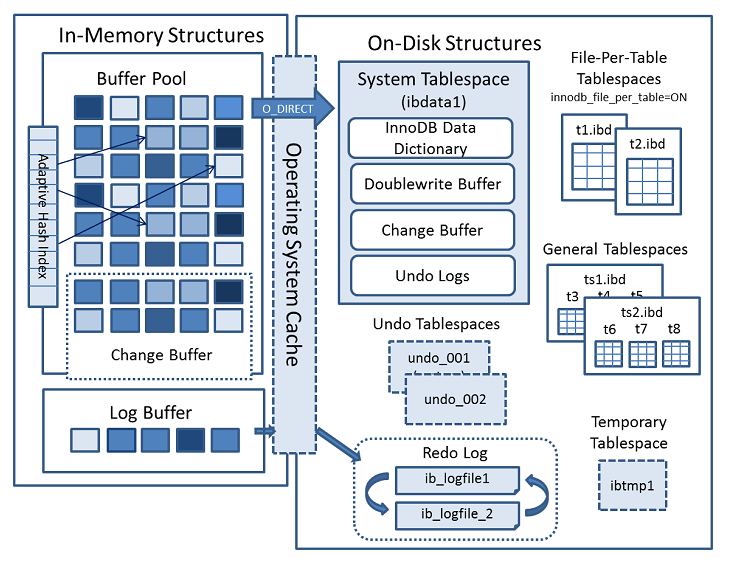
二.Innodb-内存结构
Innodb缓冲池
- Innodb是基于磁盘存储的,并将其中的记录按照页(默认16K)的方式进行管理,(基于磁盘的数据库系统Disk-baseDatabase)。
- 数据库系统中由于CPU速度与磁盘速度之间差距甚远,所以基于磁盘的数据库系统通常使用缓冲池(buffer pool)的技术来提高数据库的整体性能。
- 缓冲池就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库的影响。
- 要注意的是数据库中对于数据页的修改操作都是在缓冲池中完成的。
- 修改数据时,先修改缓冲池中的页数据,然后刷新到磁盘,并不是每次都刷新而是通过Checkpoint机制刷新到磁盘。
- 数据页类型:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引、锁信息、数据字典信息等。
缓冲池LRU算法(Latest,Recent Used)最近最少使用算法
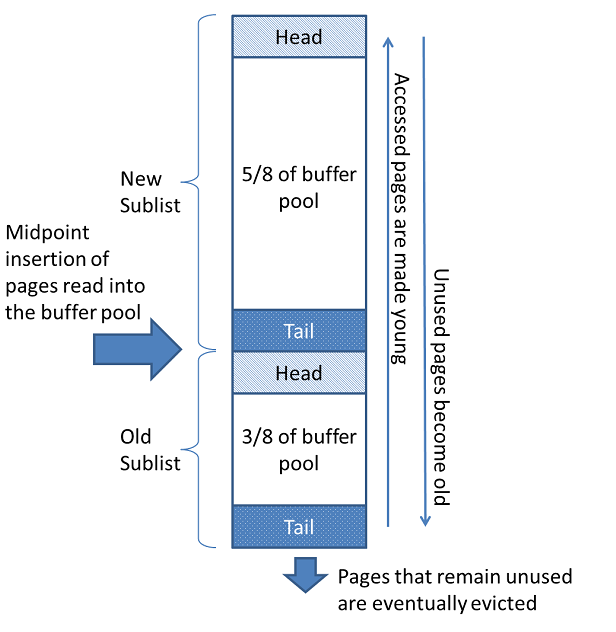
相关参数:
innodb_old_blocks_pct | 37 旧数据和新数据页的分界线,默认设置为37%,意味旧数据页占整个LRU列表的37%
innodb_old_blocks_time | 1000 单位毫秒(默认1s)
Innodb在读取新的数据页时,并不是直接将这个数据页直接放到LRU列表的首部(如果直接放到首部,会导致之前正在使用的热数据被刷出列表),而是通过midpoint点,放入midpoint位置(innodb_old_blocks_pct空值)。midpoint之前的位置就是new列表,之后的位置就是old列表
Q:为什么热数据不直接放到LRU列表的首部?
这是由于某些慢语句可能需要全表扫描,这种情况以及类似的需要扫描大量数据的情况下,如果按照朴素的LRU算法,将磁盘上的数据页都读到LRU中,直接放到LRU列表的首部,就会将LRU列表中正在使用的热数据被刷新出列表,如果这个SQL只是使用了一次就不再使用了。那么现在LRU列表中的数据大部分就是不再使用的冷数据。下次读取数据,就要再次去磁盘中读取,加大了IO。
Q:那么如何规定新读进来的数据页放在LRU的规则?
除了上面制定LRU中new列表和old列表的分界线之外,还有一个参数,innodb_old_blocks_time 改参数的含义:读进来的新数据页先放入midpoint位置的冷端(冷端的头部),如果这个数据页在这个冷端能挺过改参数指定的时长,就将这个数据页放到热端(热端的尾部)。
mysql5.7对于LRU算法的改进
https://yq.aliyun.com/articles/281249
LRU List,Free List,Flush List
- LRU List:这个是InnoDB中最重要的链表。所有新读取进来的数据页都被放在上面。链表按照最近最少使用算法排序,最近最少使用的节点被放在链表末尾,如果Free List里面没有节点了,就会从中淘汰末尾的节点。LRU List还包含没有被解压的压缩页,这些压缩页刚从磁盘读取出来,还没来的及被解压。LRU List被分为两部分,默认前5/8为young list,存储经常被使用的热点page,后3/8为old list。新读入的page默认被加在old list头,只有满足一定条件后,才被移到young list上,主要是为了预读的数据页和全表扫描污染buffer pool。
- Free List:数据库启动时LRU表为空,页均存放在Free List中。需要使用时从该表中获取。如果需要从数据库中分配新的数据页,直接从上获取即可。InnoDB需要保证Free List有足够的节点,提供给用户线程用,否则需要从FLU List或者LRU List淘汰一定的节点。InnoDB初始化后,Buffer Chunks中的所有数据页都被加入到Free List,表示所有节点都可用。
- Flush List管理缓存中被修改过的页。这个链表中的所有节点都是脏页,也就是说这些数据页都被修改过,但是还没来得及被刷新到磁盘上。在FLU List上的页面一定在LRU List上,但是反之则不成立。一个数据页可能会在不同的时刻被修改多次,在数据页上记录了最老(也就是第一次)的一次修改的lsn,即oldest_modification。不同数据页有不同的oldest_modification,FLU List中的节点按照oldest_modification排序,链表尾是最小的,也就是最早被修改的数据页,当需要从FLU List中淘汰页面时候,从链表尾部开始淘汰。加入FLU List,需要使用flush_list_mutex保护,所以能保证FLU List中节点的顺序。
相关监控:
通过 show engine innodb status \G
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 1117782016
Dictionary memory allocated 234666
Internal hash tables (constant factor + variable factor)
Adaptive hash index 17740608 (17706944 + 33664)
Page hash 139112 (buffer pool 0 only)
Dictionary cache 4661402 (4426736 + 234666)
File system 854280 (812272 + 42008)
Lock system 2659448 (2657176 + 2272)
Recovery system 0 (0 + 0)
Buffer pool size 65528
Buffer pool size, bytes 1073610752
Free buffers 65014
Database pages 514
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 476, created 38, written 347
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 514, unzip_LRU len: 0 LRU列表中包含了unzip_LRU的项
I/O sum[]:cur[], unzip sum[]:cur[]
----------------------
主要看两个指标:
youngs/s:使数据页边年轻的此时(不是页数)过大
- pct过大 不容易被刷出来
- time过小
non-youngs/:使数据页边老的次数(不是页数)过大
- 可能存在严重的全表扫描
- 也可能是pct的设置过小
- 也可能是times设置的过大
unzip_LRU
这个链表中存储的数据页都是解压页,也就是说,这个数据页是从一个压缩页通过解压而来的。
Innodb从1.0开始支持压缩也的功能。原本16KB的页可以压缩为1KB,2KB,4KB,8KB,对于这些非16KB的页是同坐unzip_LRU来管理的。
Q:压缩后的数据页大小可能都不一样,那么如果需要从缓冲池中申请的页大小为4KB,如何申请?
A: 1.检查4KB的unzip_LRU列表,检查是否有可用的空闲页
2.如果有,直接使用
3.否则,检查8KB的unzip_LRU列比哦啊
4.如果能够得到空闲页,将页分成2个4KB的页,存放到4KB的unzip_LRU列表中
5.如果不能得到空闲页,从LRU列表中申请一个16KB的页,将页分为一个8KB和2个4KB的页,分别存放到对应的unzip_LRU列表中
缓冲池相关监控
1.show engine innodb status \G
2.information_schema
mysql> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_BUFFER%';
+-----------------------------------------------+
| Tables_in_INFORMATION_SCHEMA (INNODB_BUFFER%) |
+-----------------------------------------------+
| INNODB_BUFFER_PAGE |保存有关InnoDB缓冲池中每个页面的信息
| INNODB_BUFFER_POOL_STATS |提供缓冲池状态信息。许多相同的信息由SHOW ENGINE INNODB STATUS输出提供 ,或者可以使用InnoDB缓冲池服务器状态变量获得
| INNODB_BUFFER_PAGE_LRU |保存有关InnoDB缓冲池中页面的信息,特别是它们在LRU列表中的排序方式,它确定哪些页面在缓冲池变满时从缓冲池中逐出
+-----------------------------------------------+
查询INNODB_BUFFER_PAGE或 INNODB_BUFFER_PAGE_LRU表可能会影响性能。除非您了解性能影响并确定其可接受,否则请勿在生产系统上查询这些表。为避免影响生产系统的性能,请重现要调查的问题并在测试实例上查询缓冲池统计信息。
一些查询:
查询INNODB_BUFFER_PAGE表中的系统数据
此查询通过排除TABLE_NAME值为 NULL或者包含表名中的斜杠/ 或句点的页面来提供包含系统数据的页面的近似计数 .,表示用户定义的表。
mysql> SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE WHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);
+----------+
| COUNT(*) |
+----------+
| 65497 |
+----------+
此查询返回包含系统数据的大致页数,缓冲池页的总数以及包含系统数据的页的大致百分比。
SELECT
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0)
) AS system_pages,
(
SELECT COUNT(*)
FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
) AS total_pages,
(
SELECT ROUND((system_pages/total_pages) * 100)
) AS system_page_percentage;
查询PAGE_TYPE值来确定缓冲池中的系统数据类型。例如,以下查询PAGE_TYPE在包含系统数据的页面中返回八个不同的 值:
SELECT DISTINCT PAGE_TYPE FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);
INNODB_BUFFER_PAGE表中查询用户数据
此查询通过计算TABLE_NAME值为NOT NULL和的页面来提供包含用户数据的页面的近似计数 NOT LIKE '%INNODB_SYS_TABLES%'。
SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME IS NOT NULL AND TABLE_NAME NOT LIKE '%INNODB_SYS_TABLES%';
返回包含用户数据的大致页数,缓冲池页面的总数以及包含用户数据的页面的大致百分比
SELECT
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME IS NOT NULL AND (INSTR(TABLE_NAME, '/') > 0 OR INSTR(TABLE_NAME, '.') > 0)
) AS user_pages,
(
SELECT COUNT(*)
FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
) AS total_pages,
(
SELECT ROUND((user_pages/total_pages) * 100)
) AS user_page_percentage;
此查询使用缓冲池中的页面标识用户定义的表
SELECT DISTINCT TABLE_NAME FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME IS NOT NULL AND (INSTR(TABLE_NAME, '/') > 0 OR INSTR(TABLE_NAME, '.') > 0)
AND TABLE_NAME NOT LIKE '`mysql`.`innodb_%';
查询INNODB_BUFFER_PAGE表中的索引数据
有关索引页的信息,请INDEX_NAME使用索引名称查询 列。例如,以下查询返回表中emp_no定义的索引 的页数和页面总数据大小 employees.salaries:
SELECT INDEX_NAME, COUNT(*) AS Pages,
ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))/1024/1024)
AS 'Total Data (MB)'
FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE INDEX_NAME='emp_no' AND TABLE_NAME = '`employees`.`salaries`';
此查询返回employees.salaries表中定义的所有索引的页数和页面总数据大小
SELECT INDEX_NAME, COUNT(*) AS Pages,
ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))/1024/1024)
AS 'Total Data (MB)'
FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE TABLE_NAME = '`employees`.`salaries`'
GROUP BY INDEX_NAME;
具体参考官方文档:
https://dev.mysql.com/doc/refman/5.7/en/innodb-information-schema-buffer-pool-tables.html#innodb-information-schema-buffer-pool-stats-example
相关的状态变量:
+-----------------------------------------+--------------------------------------------------+
| Variable_name | Value |
+-----------------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_dump_status | Dumping of buffer pool not started |
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 181126 10:00:00 |
| Innodb_buffer_pool_resize_status | |
| Innodb_buffer_pool_pages_data | 1852 |
| Innodb_buffer_pool_bytes_data | 30343168 |
| Innodb_buffer_pool_pages_dirty | 3 |
| Innodb_buffer_pool_bytes_dirty | 49152 |
| Innodb_buffer_pool_pages_flushed | 4356 |
| Innodb_buffer_pool_pages_free | 63676 |
| Innodb_buffer_pool_pages_LRU_flushed | 0 |
| Innodb_buffer_pool_pages_made_not_young | 0 |
| Innodb_buffer_pool_pages_made_young | 0 |
| Innodb_buffer_pool_pages_misc | 0 |
| Innodb_buffer_pool_pages_old | 0 |
| Innodb_buffer_pool_pages_total | 65528 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 0 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 52000 |
| Innodb_buffer_pool_reads | 477 |
| Innodb_buffer_pool_wait_free | 0 |
| Innodb_buffer_pool_write_requests | 39180 |
| Innodb_buffered_aio_submitted | 0 |
+-----------------------------------------+--------------------------------------------------+
三.后台线程
1.master thread
具有最高的线程优先级级别,内部有多个loop组成:
主循环 mian loop
后台循环background loop
刷新循环 flush loop
暂停循环 suspend loop
主要负责将脏缓存页刷新到数据文件,执行purge操作,触发检查点checkponit,合并插入缓冲区insert buffer
innodb 1.0.x 版本之前的master thread
每秒一次的操作:
- 日志缓冲刷新到磁盘,即使该事务没有提交(总是)
- 合并插入缓冲(可能)判断前一秒内io是否小于5次,如果小于,认为当前io压力小,可以执行insert buffer合并
- 最多刷新100个innodb的缓冲池中的脏页到磁盘(可能)
- 如果当前没有用户活动,就切换到background loop(可能) 根据buf_get_modified_pct 大小决定,如果超过90%的时候惠认为需要做磁盘同步操作,将100个脏页刷新到磁盘控制参数:innodb_max_dirty_pages_pct.
每10秒一次的操作:
- 刷新100个脏页(可能) 判断过去10秒内io是否小于200,如果小于,认为当前io能力足够,将刷新100个脏页
- 合并最多5个插入缓冲(总是) 刷完脏页后紧接着合并insert buffer,总会执行
- redo日志刷新到磁盘(总是)
- 删除无用的undo log(总是) 每次最多删除20个undo页
- 刷新100个或者10个脏页到磁盘(总是) 根据buf_get_modified_pct判断,如果>70%,刷100个脏页,如果<70%,刷10个脏页
以上是主循环
如果没有用户活动(数据库空闲)或者数据库关闭(suhtdown)就会切换到,background loop
- 删除没用的undo页(总是)
- 合并20个insert buffer(总是)
- 跳回main loop(总是)
- 不断刷新100个页知道符合条件(可能,跳转到flush loop中完成)
如果flush loop中也没事做了,就切换到supspend loop 将master thread挂起,等事件发生.
innodb 1.2.X版本之前的master thread
改进点1:
不再按照规定值刷新(之前最多1秒内只能处理100个脏页合并20个insert buffer)
而是按照参数innodb_io_capacity(表示io吞吐量,默认值200)做参考,对于刷新页的数量,按照参数规定的百分比控制:合并insert buffer时,数量为参数的25%,刷脏页时数量为参数设定值
改进点2:
设置innodb_max_dirty_pages_pct默认值为75%,因为之前的90%才刷脏页而且每次只能刷100个,如果内存很大,数据库压力很大,反而降低了刷脏页的效率,数据库恢复阶段可能需要更多的时间.
改进点3:
innodb 1.0.X 新增自适应刷新脏页,通过参数innodb_adaptive_fluhsing控制,根据redo log产生速度来决定合适刷新脏页数量,即使脏页比例小于innodb_max_dirty_pages_pct,也会刷新一定的脏页
改进点4:
每次full purge时最多刷新20个undo页,1.0.X版本后引入参数:innodb_purge_batch_size 来修改这个数量
innodb 1.2.X 版本的master thread
分离出一个单独的page cleaner thread ,减轻master thread的工作,提高系统并发性
2.purge thread
回收undo页
净化线程,MySQL5.5之后用单独的purge thread执行purge操作
参数控制:
innodb_purge_threads
3.page cleaner thread
innodb 1.2.x引入,刷新脏页(从master thread中分出来)
4.IO thread
innodb使用大量异步IO(Async IO)
参数:
innodb_read_io_threads
innodb_write_io_threads
redo log刷新机制
1:master thread 每一秒刷新
2.每个事务提交的时候刷新
3.redo log buffer 剩余空间小于1/2时刷新
四.文件系统
Innodb是以页为基本单位管理存储空间的,默认的页大小为16KB.
1.系统表空间(system tablespace)
这个所谓的系统表空间可以对应文件系统上一个或多个实际的文件,默认情况下,InnoDB会在数据目录下创建一个名为ibdata1.大小为12M的文件
对应参数:
[server]
innodb_data_file_path=data1:512M;data2:512M:autoextend
这样在MySQL启动之后就会创建这两个512M大小的文件作为系统表空间,其中的autoextend表明这两个文件如果不够用会自动扩展data2文件的大小
我们也可以把系统表空间对应的文件路径不配置到数据目录下,甚至可以配置到单独的磁盘分区上,涉及到的启动参数就是innodb_data_file_path和innodb_data_home_dir
参数文档:https://blog.csdn.net/demonson/article/details/79863166
2.独立表空间(file-per-table tablespace)
共享表空间越来越大,会对IO产生瓶颈,
控制参数
innodb_file_per_table,
开启后每张表的表空间只存放自己的:数据,索引和插入缓冲BITMAP页。其它信息仍放在默认表空间。
3.其他表空间
Innodb-内存架构与特性的更多相关文章
- InnoDB体系架构(二)内存
InnoDB体系架构(二)内存 上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread.IO Thread.Purge Thread. ...
- InnoDB的4个特性
innodb 的四个特性 insert buffer innodb使用insert buffer"欺骗"数据库:对于为非唯一索引,辅助索引的修改操作并非实时更新索引的叶子页,而是把 ...
- InnoDB体系架构(三)Checkpoint技术
Checkpoint技术 前篇 InnoDB体系架构(二)内存 从缓冲池.缓冲池的管理.重做日志缓冲.额外内存缓冲这四个点介绍了InnoDB存储引擎的内存结构,而在将缓冲池的数据刷新到磁盘的过程中使用 ...
- InnoDB体系架构(一)后台线程
InnoDB体系架构——后台线程 上一篇已经了解了MySQL数据库的体系结构 这一篇除了介绍InnoDB存储引擎的体系架构外,同时进一步了解InnoDB的后台线程. InnoDB存储引擎是多线程的模型 ...
- InnoDB体系架构
MySQL支持插件式存储引擎,常用的存储引擎则是MyISAM和InnoDB,通常在OLTP(Online Transaction Processing 在线事务处理)中,我们选择使用InnoDB,所以 ...
- MySQL内存表的特性与使用介绍
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- 14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器
14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器 当InnoDB 被开发时,内存分配提供了操作系统和 run-time ...
- MySQL内存表的特性与使用介绍 -- 简明现代魔法
MySQL内存表的特性与使用介绍 -- 简明现代魔法 MySQL内存表的特性与使用介绍
- Java 内存模型和硬件内存架构笔记
前言 可跟<主存存取和磁盘存取原理笔记>串着看 https://blog.csdn.net/suifeng3051/article/details/52611310 杂技 Java 内存模 ...
- InnoDB体系架构(四)Master Thread工作方式
Master Thread工作方式 在前面的文章:InnoDB体系架构——后台线程 说到:InnoDB存储引擎的主要工作都是在一个单独的后台线程Master Thread中完成.这篇具体介绍该线程的具 ...
随机推荐
- Python 中 unittest 框架加载测试用例的常用方法
unittest 当中为我们提供了许多加载用例的方法,这里说下常用的两种方法...推荐使用第二种 第一种加载测试用例的方法:使用加载器加载两个模块 需要把所有的模块加载到套件中 那么就可以自动的运行所 ...
- PhotoView 实现与图片进行简单的交互
本文的category是根据VIPhotoView来做参考,在此基础上添加个加载网络图片. 此category主要功能是与图片进行交互,双击放大图片,捏合等操作. 感谢vitoziv ! VIPhot ...
- codeforces 594
D 给你一个长度为n的括号序列,然后你可以选择交换两个位置,你需要使得能够变成 合法括号序列的起点最多. 题解 人尽皆知的东西:合法的括号序列是,令'('为1,')'为-1,那么前缀和需要>=0 ...
- spring boot集成mybatis(1)
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Cheat Engine 入门操作
Cheat Engine(简称CE,中文名-作弊引擎),用于查找.修改内存数据,是游戏逆向的基础工具. 本文仅介绍基础操作. 1.打开进程 运行游戏程序,并将CE附加到进程 2.寻找数据地址,并修改数 ...
- CGridCtrl添加右键菜单
头文件下添加: afx_msg void OnMergeCell(); afx_msg void OnContextMenu(CWnd* /*pWnd*/, CPoint /*point*/); 添加 ...
- 吴裕雄--天生自然 JAVASCRIPT开发学习:字符串
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- spring boot集成mybatis(3) - mybatis generator 配置
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- repr. str, ascii in Python
repr和str a="Hello" print(str(a)) print(repr(a)) 结果: Hello 'Hello' 可以看出,repr的结果中多了左右两个引号. r ...
- [ACTF2020 新生赛]Include
0x00 知识点 本地文件包含 ?file=php://filter/read/convert.base64-encode/resource=index.php ?file=php://filter/ ...