HiBench成长笔记——(1) HiBench概述
测试分类
HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming。
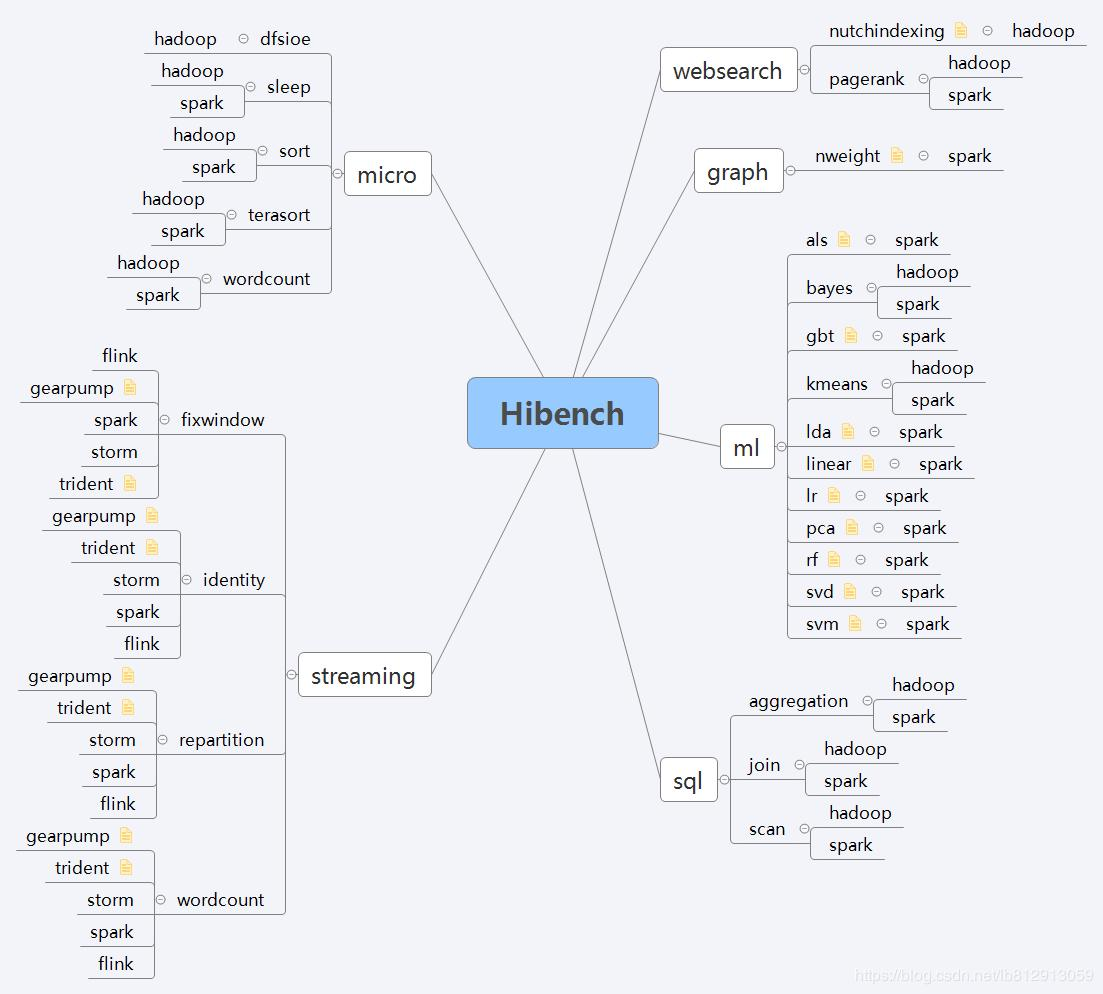
2.1 micro Benchmarks
- 排序(sort)
此工作负载对其文本输入数据进行排序,该数据是使用RandomTextWriter生成的。 - 词频统计(wordcount)
此工作负载计算输入数据中每个单词的出现次数,这些单词是使用RandomTextWriter生成的。它代表了一种典型的MapReduce作业。 - TeraSort(terasort)
TeraSort是由Jim Gray创建的标准基准测试。其输入数据由Hadoop TeraGen示例程序生成。 - 休眠(sleep)
此工作负载在每个任务中休眠几秒钟以测试框架的调度性能。 - 增强型DFSIO(dfsioe)
增强型DFSIO通过生成大量同时执行写入和读取的任务来测试Hadoop集群的HDFS吞吐量。它测量每个映射任务的平均I / O速率,每个映射任务的平均吞吐量以及HDFS集群的聚合吞吐量。注意:此基准测试没有Spark相应的实现。
2.2 Machine Learning
- 贝叶斯分类(Bayes)
朴素贝叶斯是一种简单的多类分类算法,假设每对特征之间具有独立性。此工作负载在spark.mllib中实现,并使用自动生成的文档,其文字遵循zipfian分布。用于生成文本的dict也来自默认的linux文件/usr/share/dict/linux.words.ords。 - K均值聚类(Kmeans)
此工作负载测试spark.mllib中的K-means(一种众所周知的知识发现和数据挖掘聚类算法)聚类。输入数据集由GenKMeansDataset基于Uniform Distribution和Guassian Distribution生成。 - 逻辑回归(LR)
Logistic回归(LR)是一种预测分类响应的常用方法。此工作负载在带有LBFGS优化器的spark.mllib中实现,输入数据集由LogisticRegressionDataGenerator基于随机平衡决策树生成。它包含三种不同的数据类型,包括分类数据,连续数据和二进制数据。 - 交替最小二乘(ALS)
交替最小二乘(ALS)算法是用于协同过滤的众所周知的算法。此工作负载在spark.mllib中实现,输入数据集由RatingDataGenerator为产品推荐系统生成。 - 梯度增强树(GBT)
梯度提升树(GBT)是一种使用决策树集合的流行回归方法。此工作负载在spark.mllib中实现,输入数据集由GradientBoostingTreeDataGenerator生成。 - 线性回归(Linear)
线性回归(线性)是使用SGD优化器在spark.mllib中实现的工作负载。输入数据集由LinearRegressionDataGenerator生成。 - 狄利克雷分布(LDA)
狄利克雷分布(LDA)是一个主题模型,它从一组文本文档中推断出主题。此工作负载在spark.mllib中实现,输入数据集由LDADataGenerator生成。 - 主成分分析(PCA)
主成分分析(PCA)是一种统计方法,用于查找旋转,使得第一个坐标具有尽可能大的方差,并且每个后续坐标又具有可能的最大方差。PCA广泛用于降维。此工作负载在spark.mllib中实现。输入数据集由PCADataGenerator生成。 - 随机森林(RF)
随机森林(RF)是决策树的集合。随机森林是用于分类和回归的最成功的机器学习模型之一。它们结合了许多决策树,以降低过度拟合的风险。此工作负载在spark.mllib中实现,输入数据集由RandomForestDataGenerator生成。 - 支持向量机(SVM)
支持向量机(SVM)是大规模分类任务的标准方法。此工作负载在spark.mllib中实现,输入数据集由SVMDataGenerator生成。 - 奇异值分解(SVD)
奇异值分解(SVD)将矩阵分解为三个矩阵。此工作负载在spark.mllib中实现,其输入数据集由SVDDataGenerator生成。
2.3 SQL
- 扫描(Scan),连接(Join),聚合(Aggregate)
这些工作量是基于SIGMOD 09论文“大规模数据分析方法的比较”和HIVE-396开发的。它包含Hive查询(Aggregate和join),执行本文中描述的典型OLAP查询。它的输入是Zipfian分布后自动生成的带有超链接的Web数据。
2.4 Websearch Benchmarks
- 网页排名(PageRank)
此工作负载基准测试PageRank算法在Spark-MLLib / Hadoop(包含在pegasus 2.0中的搜索引擎排名基准)示例中实现。数据源是从Web数据生成的,其超链接遵循Zipfian分布。 - Nutch索引(nutchindexing)
大规模搜索索引是MapReduce最重要的用途之一。这个工作负载测试Nutch的索引子系统,Nutch是一个流行的开源(Apache项目)搜索引擎。工作负载使用自动生成的Web数据,其超链接和单词都遵循Zipfian分布和相应的参数。用于生成网页文本的字典是默认的linux dict文件。
2.5 Graph Benchmark
- NWeight(nweight)
NWeight是Spark GraphX和pregel实现的迭代图并行算法。该算法计算两个顶点的关联,这两个顶点是n跳。
2.6 Streaming Benchmarks
- 一致性(identity)
此工作负载从Kafka读取输入数据,然后立即将结果写入Kafka,不涉及复杂的业务逻辑。 - 重分区(repartition)
此工作负载从Kafka读取输入数据,并通过创建更多或更少的分区步骤来更改并行度。它测试流式框架中数据混洗的效率。 - 有状态的Wordcount(wordcount)
此工作负载计算每隔几秒钟从Kafka累积收到的单词。这将测试流式框架中的有状态运算符性能和Checkpoint / Acker成本。 - 窗口(fixwindow)
工作负载执行基于窗口的聚合。它测试流式框架中窗口操作的性能。
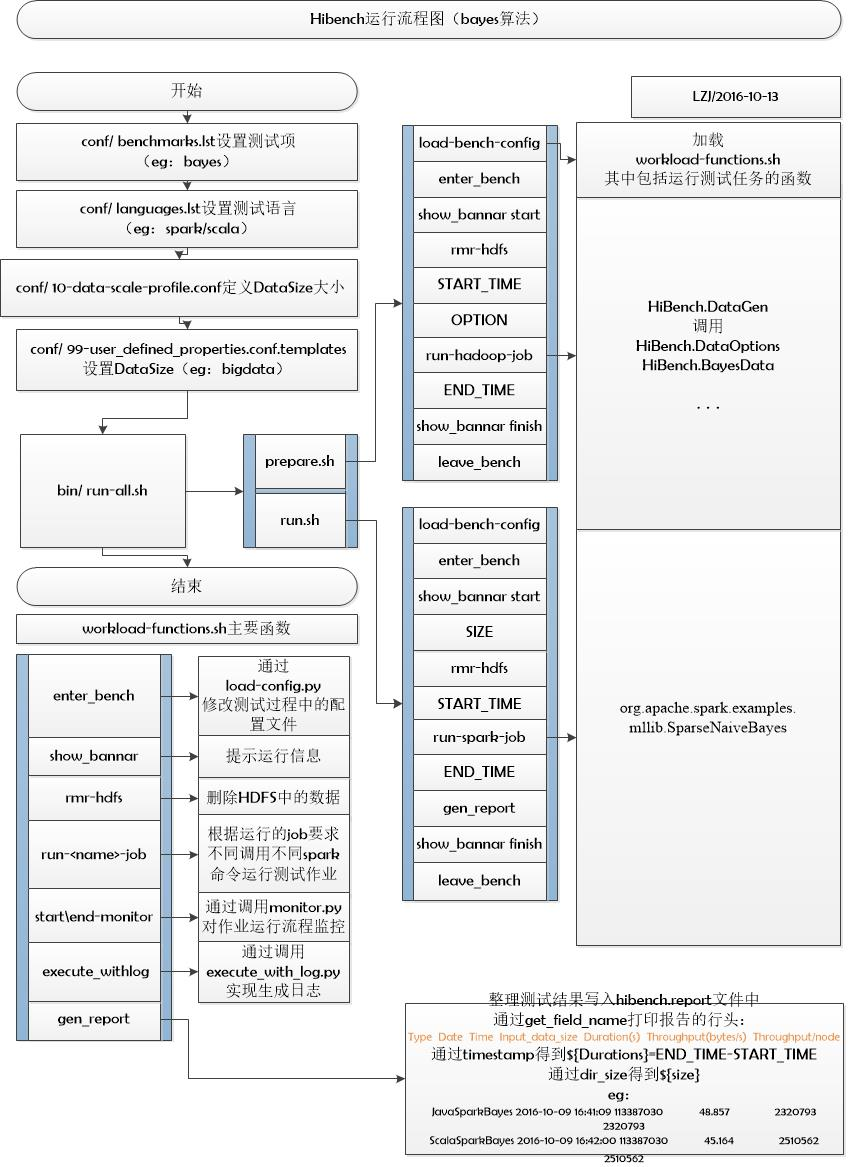
HiBench运行流程
- prepare.sh->run.sh为run-all.sh的子流程;
- enter_bench->…->leave_bench为prepare.sh和run.sh的子流程;
- enter_bench…..gen_report等为workload-functions.sh中的公共函数。
流程图如下:
参考:http://www.pianshen.com/article/7307183210/ ; https://blog.csdn.net/wangyaninglm/article/details/52901301
HiBench成长笔记——(1) HiBench概述的更多相关文章
- HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnb ...
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(6) HiBench测试结果分析
Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Ag ...
- HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》
<The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis>内容精选 We th ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala 使用spark-shell命令进入shell模式,查看spark版本和Scala版本: 下载Scala2.10.5 wget https://downloads.lightbend.c ...
- HiBench成长笔记——(11) 分析源码run.sh
#!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor licen ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
随机推荐
- day03-MyBatis的动态SQL语句查询
场景一: 例如当我们想实现这样的查询的时候之前的操作貌似满足不了我们. 场景二: 还有些时候我们如果输入的信息越多满足要求的就越多,所查找出来的用户就越少 当我们之输入姓名的时候可能查找出10个人, ...
- php 安装 swoole
1.安装swoole cd /usr/local/src wget https://github.com/swoole/swoole-src/archive/v1.9.1-stable.tar.gz ...
- js 模拟鼠标拖动
window.addEventListener('message', function (event) { if (event.source != window) return; if (event. ...
- Spring学习(一)
搭建环境 1.创建普通的Java工程 2.添加相应的jar包,下载链接:https://files.cnblogs.com/files/AmyZheng/lib.rar,此外,为了打印信息,我们还需要 ...
- 南京江行智能获得百度和松禾资本的A+轮融资
导读 据公司情报专家<财经涂鸦>消息,南京江行联加智能科技有限公司(江行智能)获得百度 和松禾资本的A+ 轮融资. 天眼查信息显示,12 月 8 日,公司工商信息发生变更,股东新增了广州百 ...
- Linux centosVMware Linux监控平台介绍、zabbix监控介绍、安装zabbix、忘记Admin密码如何做
一.Linux监控平台介绍 cacti.nagios.zabbix.smokeping.open-falcon等等 cacti.smokeping偏向于基础监控,成图非常漂亮 cacti.nagios ...
- web前端面试第一次[定时器]
BOM中定时器--计时器 定时器参数两个:(函数,时间(单位ms(1000ms=1s))) 时间设置1s,每过1s执行一次函数 //设置定时器 setInterval(funtion(){ alert ...
- JS array delete splice 区别
Delete in this case will only set the element as undefined: > myArray =['a','b','c','d'] >dele ...
- Ubuntu安装TTF字体
sudo mkdir /usr/share/fonts/ttf sudo cp ~/ttf/* /usr/share/fonts/ttf cd /usr/share/fonts/ttf sudo ch ...
- CSS - 滑动门技术
1. 概念: 1.1 为了使各种特殊形状的背景能够自适应元素中文本内容的多少,出现了CSS滑动门技术. 1.2 使各种特殊形状的背景能够自由拉伸滑动,以适应元素内部的文本内容,可用性更强. 1.3 最 ...