爬虫之使用requests爬取某条标签并生成词云
一、爬虫前准备
1.工具:pychram(python3.7)
2.库:random,requests,fake-useragent,json,re,bs4,matplotlib,worldcloud,numpy,PIL,jieba
random:生成随机数
requests:发送请求获取网页信息
fake-useragent:生成代理服务器
json:数据转换
re:用于正则匹配
bs4:数据过滤
matpotlib:图像处理
worldcloud:生成词云
numpy:图像处理
PIL:图像处理
jieba:对中文进行分词(本次未用到)
3.爬虫流程
使用代码模拟浏览器发送请求-->浏览器返回信息(html/json)-->提取有用的信息-->进行储存
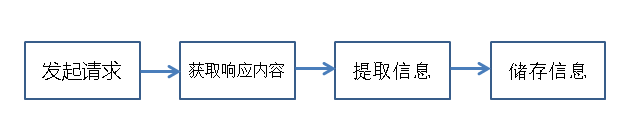
1)发起请求
使用代码向目标站点发送请求,即发送一个Request
请求应包含:请求头、请求体等
2)获取响应内容
发送请求成功后,会获得站点返回的信息(Response)
3)提取信息
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery,xpath等
解析json数据:json模块
4)储存信息
以文件存储
存入数据库
二、开始爬虫
1.防止ip被封
为了防止多次访问某站点导致IP被封,对IP进行伪装。
找一些提供免费IP的网站爬取IP数据存储到本地文件中,将爬虫进行到底。
- # __Author__ :"Chen Yang"
- # __Time__: 2019/8/22 20:56
- import requests
- from fake_useragent import UserAgent
- import re
- def create_pool(ur):
- url = ur
- ua = UserAgent()
- # fake_useragent 提供的随机生成代理服务器
- headers = {"User-Agent": ua.random}
- r = requests.get(url, headers=headers)
- # 正则匹配所有IP
- comment = re.findall('<td data-title="IP">(.*)</td>', r.text)
- # 正则匹配所有端口
- port = re.findall('<td data-title="PORT">(.*)</td>', r.text)
- print(r.text)
- print(comment)
- print(port)
- # 将IP和端口对应 存入文件
- with open('ip-port.text', 'a', encoding='utf-8') as f:
- for i in range(len(comment) - 1):
- f.write(comment[i] + ":" + port[i])
- f.write('\n')
- if __name__ == "__main__":
- # 爬取该网页前7页IP
- for i in range(6):
- ur = 'http://www.qydaili.com/free/?action=china&page=' + str(i)
- create_pool(ur)
IP爬取
2.IP爬取成功后正式开始爬取某条
xhr:XMLHttpRequest 对象提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。
某条文章是动态随机推荐的,每次进入头条页面的文章都不同。
在多次分析后找到realtime_news/的xhr




访问open_url,爬取标签
至此,基本可以确定realtime_news的xhr就是要爬的文件。
思路:爬取realtime_news的xhr的文件-->获取其中open_url-->爬取标签-->生成词云
- import random
- import requests
- from fake_useragent import UserAgent
- import json
- import re
- from bs4 import BeautifulSoup
- import matplotlib.pyplot as plt # 用于图像处理
- from wordcloud import WordCloud# 用于生成词云
- import numpy as np
- from PIL import Image
- # 词云形状文件 需要替换成你本地的图片
- backgroud_Image = np.array(Image.open("man.jpg"))
- # 词云字体 需要替换成你本地的字体
- WC_FONT_PATH = '黄引齐招牌体.ttf'
- def get_ip():
- f = open("ip-port.text", 'r') # 从IP-port中读取IP
- ip_all = []
- for k in f:
- line = f.readline()
- ip_all.append(line[:-1]) # 去除/n
- f.close()
- # print(ip_all)
- i = random.randint(0, len(ip_all)-1)
- pr = ip_all[i]
- print("ip地址为:{}".format(pr))
- return pr
- def get_info():
- '''
- 使用爬取的ip来进行ip代理
- 使用fake_useragent进行服务器代理,防止IP被封
- '''
- url = 'https://www.toutiao.com/api/pc/realtime_news/'
- ua = UserAgent()
- agent = ua.random
- print("代理为:{}".format(agent))
- header = {"User-Agent": agent}
- ip = get_ip()
- proxies = {'url': ip}
- try:
- # 获取首页信息
- r = requests.get(url, headers=header, proxies=proxies)
- global_json = json.loads(r.text)
- print(global_json)
- except:
- print("请求头条主页失败")
- # 获取首页信息动态推荐文章的地址
- article = []
- for i in range(len(global_json['data'])):
- article.append(global_json['data'][i]['open_url'])
- # 头条得子文章页标号 会随机发生变化
- #print(article)
- # 取8篇文章得label
- for i in range(7):
- # 访问动态推荐文章地址
- content = "http://toutiao.com" + article[i]
- try:
- respon = requests.get(content, headers=header, proxies=proxies)
- # 输入返回对象的文本值
- # print(respon.text)
- except:
- print("请求文章失败")
- # 指定编码等于原始页面编码
- respon.encoding = respon.apparent_encoding
- # 获取想要地址对应的BeautifulSoup
- html = BeautifulSoup(respon.text, 'lxml')
- # 选择 第六个script标签 即数据所在标签
- try:
- src = html.select('script')[6].string
- #print(src)
- except:
- print("获取数据失败!")
- result = []
- try:
- # 正则找到数据中标签字段
- labels = re.findall('tags:(.*),', respon.text)
- #print(type(labels))
- # strip()去空格
- # 把字符串转为列表
- result = labels[0].strip()
- # print(type(result))
- # print(labels)
- # eval() 将字符串列表 转为列表
- result = eval(result)
- # print(result)
- except:
- print("未获得labels")
- with open("labels.json", 'a', encoding='utf-8') as f:
- for i in range(len(result)-1):
- f.write(result[i]['name'])
- f.write(' ')
- def cut_word():
- '''
- 生成词云
- :return:
- '''
- with open("labels.json", 'r', encoding='utf-8') as f:
- label =f.read()
- wl = "".join(label)
- print(wl)
- return wl
- def create_word_cloud():
- '''
- 生成词云
- :return:
- '''
- # 设置词云形状图片
- #wc_mask = np.array(WC_MASK_IMG)
- # 设置词云配置 字体 背景 大小等
- wc = WordCloud(background_color='white', max_words=2000, mask=backgroud_Image, scale=4,
- max_font_size=50, random_state=42, font_path=WC_FONT_PATH)
- # 生成词云
- wc.generate(cut_word())
- # 在只设置mask情况下, 你会得到一个图片形得词云
- plt.imshow(wc, interpolation='bilinear')
- #plt.axis("off")
- plt.figure()
- plt.show()
- if __name__ == '__main__':
- get_info()
- create_word_cloud()
爬虫
爬虫之使用requests爬取某条标签并生成词云的更多相关文章
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- scrapy-redis爬取豆瓣电影短评,使用词云wordcloud展示
1.数据是使用scrapy-redis爬取的,存放在redis里面,爬取的是最近大热电影<海王> 2.使用了jieba中文分词解析库 3.使用了停用词stopwords,过滤掉一些无意义的 ...
- python爬取微信信息--显示性别/地域/词云(附代码)
看到一篇有意思的博客 利用微信开放的接口itchat 可以获取登录的微信好友信息 并且利用图像工具显示分析结果 非常的有意思 记录下实现过程 并提供可执行代码 首先要 import itchat 库 ...
- 爬虫-----selenium模块自动爬取网页资源
selenium介绍与使用 1 selenium介绍 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. sel ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
- 一起学爬虫——使用Beautiful Soup爬取网页
要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
随机推荐
- pymysql常见报错
错误一: AttributeError: module 'pymysql' has no attribute 'connect' 有道翻译 AttributeError:模块'pymysql'没有属性 ...
- gradle配置多个代码仓库repositories
repositories { mavenCentral() maven { url "https://jitpack.io" } maven { url "http:// ...
- c2000 N2A1 设置 KonNaD Settings & User Manual
KonNaD Settings & User Manual c2000 N2A1 两个开关都推到左边,都设置成off
- UML-FURPS+与补充性规格说明
1.FURPS+ 在统一过程(UP)中,需求按照“FURPS+”模型进行分类. 功能性(Functional):特性.功能.安全性: 可用性(Usability):人性化因素.帮助.文档: 可靠性(R ...
- Dynamics CRM - 为 sub-grid 添加 OnChange 事件
目的: 有的时候我们需要对 sub-grid 内容进行监控,比如在 sub-grid 上添加.删除了一条记录后,要对 Form 上的某个字段值进行更新. 解决方案: 对 sub-grid 添加一个 O ...
- Python笔记_第二篇_面向过程_第二部分_3.模块的概述
这部分内容是非常重要的,分模块的基本概念和一些常用模块的使用,其实常用模块使用这部分也不是太全面,后续或者有机会再通过其他材料进行讲解. 1. 模块的概述: 目前代码比较少,写在一个文件中还体现不出什 ...
- Collection接口介绍
Collection接口介绍 一个Collection代表一组对象,是集合体系中的根接口.一些允许有重复的元素一些不允许,一些有顺序一些没有顺序.JDK不提供此接口具体类的直接实现,只会有子接口和抽象 ...
- iOS高仿微信项目、阴影圆角渐变色效果、卡片动画、波浪动画、路由框架等源码
iOS精选源码 iOS高仿微信完整项目源码 Khala: Swift 编写的iOS/macOS 路由框架 微信左滑删除效果的实现与TableViewCell的常用样式介绍 实现阴影圆角并存,渐变色背景 ...
- Hadoop_课堂笔记1
1.课程目标 实践性 2.课下需要 在家搭建一个伪分布式 3.大数据概念和意义 08年Nature第一次正式提出大数据概念 常规的数据库:结构化的数据库 TB级的结构化数据管理就很困难,需要分布式 当 ...
- c# winform清空ie缓存的几种方法
很明显 IE的缓存在其目录中显示的并不是真正的文件所处的位置,文件的位置是在隐藏的文件夹中,而且这个隐藏的文件夹我们一般找不到.在网上几种清空缓存的方法,在此我一一把代码和处理的效果显示出来.供大家参 ...