<强化学习>开门帖
(本系列只用作本人笔记,如果看官是以新手开始学习RL,不建议看我写的笔记昂)
今天是2020年2月7日,开始二刷david silver ulc课程。https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
还记得去年九月份在YOUTUBE上硬刚david silver课的时候的激情。
david silver课件汇总:(共10节课)
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
课程资料下载(我的蓝奏云):https://www.lanzous.com/b00z7vhcd ,密码david
强化学习,比较形象地说,是找到求生法则的一门技术。这是我最开始对这门技术感兴趣的原因。我最初对RL感兴趣是因为机器通过这门技术竟然能像智慧生命体一样摸爬滚打学到求生法则并“活”下去。这就很迷了。当时下决心一定要搞清楚是怎么回事。
强化学习把世界抽象为两部分,主观能动体agent和客观环境env。 智能主体,称为agent。相当于生命体。而外部环境称为env(envirnment)。
我们要做的,就是训练这个agent,提升它的智力能力,使之更好的应对env。就像大自然草原上刚出生的一只小鹿,逐渐学会在草原上生存。
将事物的发展变化抽象为一组State序列。每一个State是具体某个时间点的状态。
对于agent。把agent的行为抽象为行为空间A。A可以是离散的可以是连续的。把agent应对环境的反应方案抽象为策略pai:OxA—>[0,1]
对于env。reward激励是agent在做出行为a之后env给agent的feedback。比如说,小鹿吃到草了,那么reward为+1,小鹿被老虎吃了,reward为-99。
一些小总结:
1.强化学习不同于其他机器学习算法,它们的基础理论可以说正交.其他的机器学习算法大多在贝叶斯理论的基础上发展而来.而强化学习是以马尔可夫决策过程MDP<S,A,R,seta,P>为基础而来.它依靠反馈有一定延时的Reward激励信号而学习.
2.马尔可夫性:
未来stage只受当前stage影响,而与过去stage无关,即

3.agent状态 & env状态 辩解(摘自叶强知乎)
- 完全可观测的环境 Fully Observable Environments(个体对环境的观测 = 个体状态 = 环境状态)
正式地说,这种问题是一个马儿可夫决定过程(Markov Decision Process, MDP)
- 部分可观测的环境 Partially Observable Environments(个体状态 ≠ 环境状态)
个体间接观测环境。举了几个例子:
- 一个可拍照的机器人个体对于其周围环境的观测并不能说明其绝度位置,它必须自己去估计自己的绝对位置,而绝对位置则是非常重要的环境状态特征之一;
- 一个交易员只能看到当前的交易价格;
- 一个扑克牌玩家只能看到自己的牌和其他已经出过的牌,而不知道整个环境(包括对手的牌)状态。
正式地说,这种问题是一个部分可观测马儿可夫决策过程。个体必须构建它自己的状态呈现形式,比如:记住完整的历史:
这种方法比较原始、幼稚。还有其他办法,例如 :
1. Beliefs of environment state:此时虽然个体不知道环境状态到底是什么样,但个体可以利用已有经验(数据),用各种个体已知状态的概率分布作为当前时刻的个体状态的呈现:
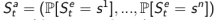
2. Recurrent neural network:不需要知道概率,只根据当前的个体状态以及当前时刻个体的观测,送入循环神经网络(RNN)中得到一个当前个体状态的呈现:
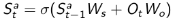
4.两对儿哲学理念辩解
4(1).预测和控制 Prediction & Control
预测:根据一个给出的POLICY,评价未来。可以看成是求解在给定策略下的价值函数(value function)的过程。
|——How well will I(an agent) do if I(the agent) follow a specific policy?
控制:找到最大化未来奖励的方案。
|——同样的条件,在所有可能的策略下最优的价值函数,最优策略是什么?
4(2).探索和利用 Exploration & Exploitation
在线广告推广时,显示最受欢迎的广告和显示一个新的广告;
油气开采时选择一个已知的最好的地点同在未知地点进行开采;
玩游戏时选择一个你认为最好的方法同实验性的采取一个新的方法。
5.学习和规划 learning & planning
learning和planning是设计一个RL算法以及理解一个RL算法要考虑的两个哲学概念。
learning就是去获知R(s,a)=?,planning就是根据已知迭代优化agent。
我们去设计一个RL算法,
如果env是给出的,那只搞planning就完了。
如果env没有给出,那肯定要先有learning再搞planning。
(env给出与否 = R(s,a) for any (s,a)是否给出)
<强化学习>开门帖的更多相关文章
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
随机推荐
- 每天一点点之laravel框架 - Laravel5.6 + Passport实现Api接口认证
1.首先通过 Composer 包管理器安装 Passport: composer require laravel/passport 注:如果安装过程中提示需要更高版本的 Laravel:larave ...
- Nginx、MySQL、PHP 编译安装
RHEL 7.0 编译安装Nginx1.6.0+MySQL5.6.19+PHP5.5.14运行环境 准备篇: RHEL 7.0系统安装配置图解教程 http://www.jb51.net/os/192 ...
- 2.6 UI控件与后台联系实现
完成的结果如下 : 当点击 左按钮时 最上边的显示栏更改为左 反之则为右 点击开关显示为开或者关 下边两个为显示加载的界面 在输入栏输入数值可以控制进度条的百分比并且显示在最上边 点击图片一二切换图 ...
- JVM探秘:MAT分析内存溢出
本系列笔记主要基于<深入理解Java虚拟机:JVM高级特性与最佳实践 第2版>,是这本书的读书笔记. MAT是分析Java堆内存的一个工具,全称是 The Eclipse Memory A ...
- Map—数据结构
map是数据结构的一种,map总是以key-value的形式保存数据的, 根据key来查找value的值,但是key的值是唯一的,在同一个map中不能重复. 常用的实现类java.util.hashM ...
- 【Linux】linux磁盘管理
在服务器管理中,我们会关心硬盘用了多少,还有多少剩余空间,哪些文件占用空间最大等等.以便我们在合适的时机为服务器添加硬盘分区以及管理磁盘文件等操作,让磁盘的利用率最大化,现在我们看下linux系统中和 ...
- (day 1)创建项目--1
1.利用cmd(命令行)创建项目myblog 确定好项目要放在哪个directory. dir一下创建好的项目看下有什么 django自带有一个小型的服务器可通过 runserver 启动它 可取浏 ...
- 如何用Python统计《论语》中每个字的出现次数?10行代码搞定--用计算机学国学
编者按: 上学时听过山师王志民先生一场讲座,说每个人不论干什么,都应该学习国学(原谅我学了计算机专业)!王先生讲得很是吸引我这个工科男,可能比我的后来的那些同学听课还要认真些,当然一方面是兴趣.一方面 ...
- dxSkinController1 皮肤使用
unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System ...
- hook键盘钩子 带dll
library Key; uses SysUtils, Classes, HookKey_Unit in 'HookKey_Unit.pas'; {$R *.res} exports HookOn,H ...