python-day3爬虫基础之下载网页
今天主要学习了关于网页下载器的一些内容,下边做一下总结:
1.网页下载器,顾名思义,就是将URL所对应的网页以HTML的形式下载到本地,最终存储成本地文件或者还是本地内存字符串,然后进行后续的分析与处理;
网页下载器主要有:urllib2和requests
下边介绍下urllib下载网页的方法:

首先是引入urllib.request
然后打开我们所定义的url,最后打印出状态码(getcode的作用就获取状态码),如果状态码是200的话,就代表是正常的。运行之后的结果如下所示:

2.网页解析器:它是以下载好的html网页字符串作为输入,然后从中提取出有价值的数据以及新的URL。
其中常见的网页解析器有:正则表达式(这是一种模糊化思想,个人认为就跟搜索关键词一样)
html.parser
Beautiful Soup(比较强大且比较常用)
lxml
其中后三者主要适用于结构化解析,这里还涉及到一个词叫做DOM(Document Object Model)树,这个今天理解的不是很透彻,以后在慢慢谈。Beautiful Soup属于python的第三方库,主要是从html和xml中提取数据。
这里给大家举个例子:
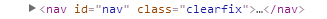
在这里,节点名称就是 nav,节点属性:id=“nav” class=“clearfix” ,节点内容:...
除此之外,今天还接触到了实例爬虫的过程:
第一步就是确定目标;第二步就是分析目标,这里边包括URL格式、数据格式以及网页编码;第三步就是编写代码了,最后执行爬虫。
今天白天帮老师干活,晚上身体有点不舒服,学的比较少,写的也比较范范,希望大家理解,如果有写的不对的,欢迎指出,大家共同学习,一起进步。
python-day3爬虫基础之下载网页的更多相关文章
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- Python扫描器-爬虫基础
0x1.基础框架原理 1.1.爬虫基础 爬虫程序主要原理就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 1.1.基础原理 1.发起HTTP请求 2 ...
- Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习.Threading多线程库.Time库.json库.BeautifulSoup4 爬虫库.py基本语法
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Python归纳 | 爬虫基础知识
1. urllib模块库 Urllib是python内置的HTTP请求库,urllib标准库一共包含以下子包: urllib.error 由urllib.request引发的异常类 urllib.pa ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
- 自学Python五 爬虫基础练习之SmartQQ协议
BAT站在中国互联网的顶端,引导着中国互联网的发展走向...既受到了多数程序员的关注,也在被我们所惦记着... 关于SmartQQ的协议来自HexBlog,根据他的博客我自己也一步一步的去分析,去尝试 ...
随机推荐
- cf 1241 D. Sequence Sorting(思维)
题意: 一个序列有n个数,有一种操作,你可以选一个数x,使这个序列中等于x的数都移到序列头或尾. 问最少几次操作后,可以使这个序列非降序. 思路: (以下说bi移动到哪里,其实就是指a1……an中等于 ...
- java嵌套循环练习
打印一个等腰三角形 package com.lv.jj; import java.util.Scanner; public class DemoDy { public static void main ...
- mac安装和启动mongodb
使用使用 brew安装mongodb 可以使用 OSX 的 brew 来安装 mongodb: sudo brew install mongodb 如果要安装支持 TLS/SSL 命令如下: sudo ...
- POJ 1584:A Round Peg in a Ground Hole
A Round Peg in a Ground Hole Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 5741 Acc ...
- 关于RxJS 处理多个Http请求 串行与并行方法
mergeMap mergeMap 操作符用于从内部的 Observable 对象中获取值,然后返回给父级流对象. 合并 Observable 对象 123456 import { of } from ...
- swift中利用系统线程实现异步加载数据同步更新UI
swift中的使用案例样式 // Mark: -数据源更新 typealias AddDataBlock = () ->Void var updataBlock:AddDataBlock? fu ...
- 第三章,数据和C
3.1 数据类型关键字 位:计算机内部数据存储的最小存储单位(bit). 字节:计算机中数据处理的基本单位(Byte)),1B=8bit. 字:计算机进行数据处理时,一次存取,加工和传送的数据长度.( ...
- Excel----考勤表制作自动更新日期
起初效果 1. 我们首先输入年月日,如图 选择日期 按`ctrl+1` 来调出下图: 2. 数据填充 3.设置星期 点击1下面的单元格
- [ACTF2020 新生赛]Include
0x00 知识点 本地文件包含 ?file=php://filter/read/convert.base64-encode/resource=index.php ?file=php://filter/ ...
- winform使用钩子限制windows热键
新增类KeybordHookProc using System; using System.Collections.Generic; using System.Diagnostics; using S ...