MongoDB知识点总结
一:MongoDB 概述
一、NoSQL 简介
1. 概念:NoSQL(Not Only SQL的缩写),指的是非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。用于超大规模数据的存储,数据存储不需要固定的模式,无需多余操作就可以横向扩展。
2. 特点
1. 优点:具有高可扩展性、分布式计算、低成本、架构灵活且是半结构化数据,没有复杂的关系等。
2. 缺点:没有标准化、有限的查询功能、最终一致是不直观的程序等。
3. 分类


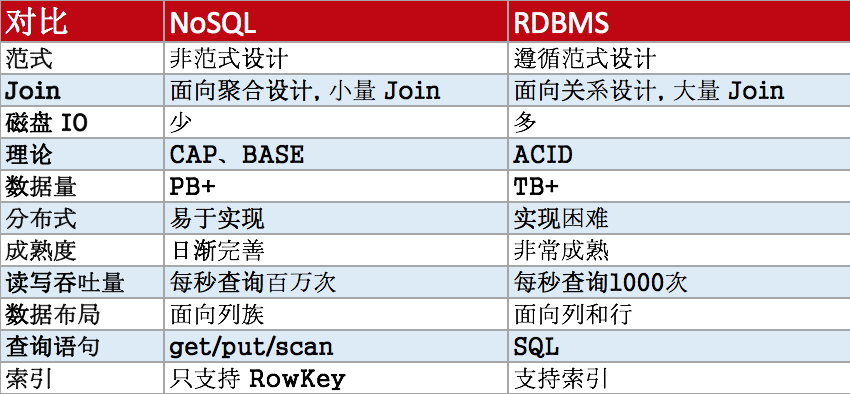
4. NoSQL 和 RDBMS 的对比
二、MongoDB 简介
1. 概念:MongoDB 是由C++语言编写的一个基于分布式文件存储的开源文档型数据库系统。
2. 功能:JSON 文档模型、动态的数据模式、二级索引强大、查询功能、自动分片、水平扩展、自动复制、高可用、文本搜索、企业级安全、聚合框架MapReduce、大文件存储GridFS。
1. 面向集合文档的存储:适合存储Bson(json的扩展)形式的数据;
2. 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
3. 强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
4. 完整的索引支持,支持查询计划;
5. 使用分片集群提升系统扩展性;
3. 适用场景
1. 网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2. 缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源 过载。
3. 在高伸缩性的场景,用于对象及JSON数据的存储。

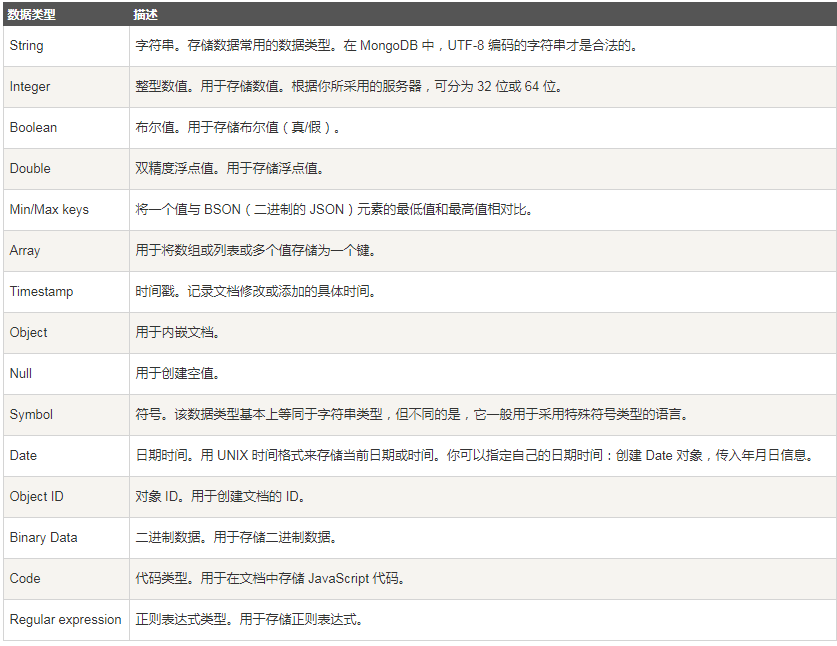
4. 数据类型
三、概念详解
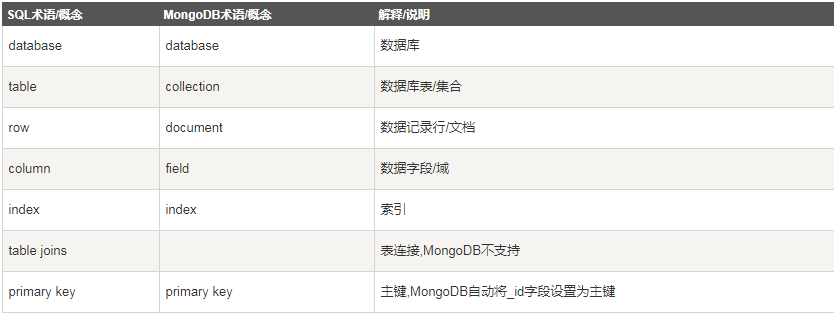
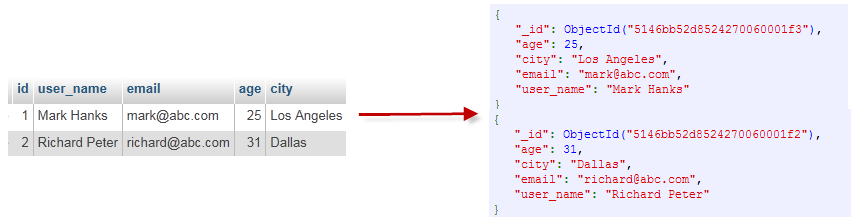
1. 数据库:MongoDB 默认的数据库为"db",该数据库存储在data目录中。单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
2. 集合:集合就是 MongoDB 文档组,类似于 RDBMS 的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
3. 文档:一个键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
四、安装配置
1. Windows
1. 下载(4.2.7版本以上)并直接安装
2. 配置环境变量

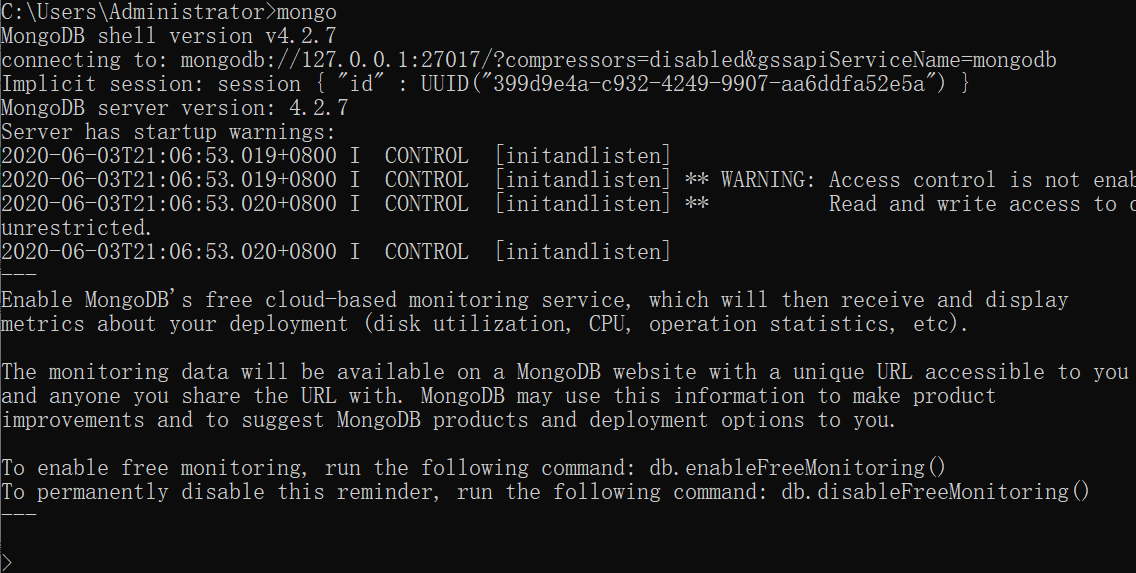
3. 测试
=
2. Linux

- # 解压到指定目录
- tar -zxvf mongodb-linux-x86_64-rhel70-4.2.7.tgz -C /opt/
- # 配置环境变量
- # MONGODB_HOME
- export MONGODB_HOME=/opt/mongodb-linux-x86_64-rhel70-4.2.7
- export PATH=$PATH:$MONGODB_HOME/bin
- # 测试
- [root@controller ~]# mongo
- MongoDB shell version: 4.2.7
- connecting to: test
二:MongoDB CLI
一、增删改

二、操作符

三、查询
1. 基本操作

2. 聚合查询

3. 管道操作:MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理

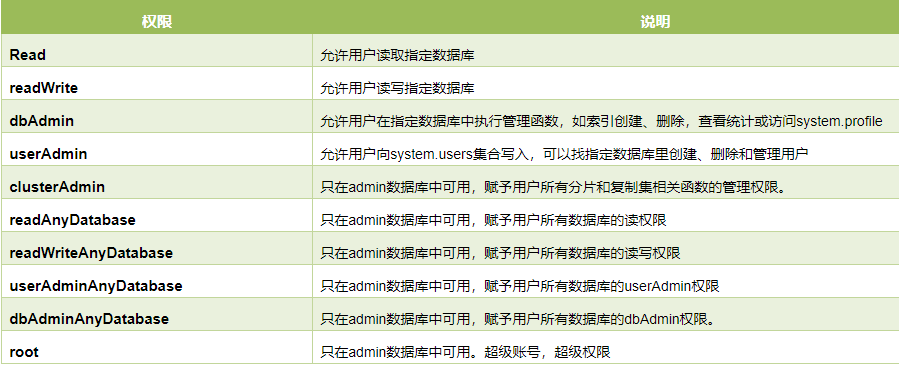
五、管理

六、索引和高可用
1. 索引
- 简介
- 作用:索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索。
- MongoDB使用 ensureIndex() 方法来创建索引,ensureIndex()方法基本语法格式如下所示:
- db.collection.createIndex(keys, options)
- 语法中 Key 值为要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1,也可以指定为hashed(哈希索引)。
- 索引属性:
- background:是否后台构建索引,在生产环境中,如果数据量太大,构建索引可能会消耗很长时间,为了不影响业务,可以加上此参数,后台运行同时还会为其他读写操作让路,这个建议配置为true开启,这样来提高效率。
- unique:是否为唯一索引
- 索引类型:
- 单键索引:
- 在某一个特定的属性上建立索引,例如:db.users. createIndex({age:-1});
- 1,mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询;
- 2,在索引字段上进行精确匹配、排序以及范围查找都会使用此索引;
- 复合索引:
- 在多个特定的属性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1});
- 1,复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;
- 2,在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;
- 3,为了性能考虑,应删除存在与第一个键相同的单键索引
- 多键索引:
- 在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1});
- 哈希索引:
- 不同于传统的B-树索引,哈希索引使用hash函数来创建索引。
- 1,在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash;
- 2,Hash索引上的入口是均匀分布的,在分片集合中非常有用;
- 优化
- 1,开启内置的查询分析器,记录读写操作效率:
- db.setProfilingLevel(n,{m}),n的取值可选0,1,2;
- 0是默认值表示不记录;
- 1表示记录慢速操作,如果值为1,m必须赋值单位为ms,用于定义慢速查询时间的阈值;
- 2表示记录所有的读写操作;
- 2,分析慢速查询
- 就是查看执行计划,使用explain分析慢速查询。
- explain的入参可选值为:
- "queryPlanner":是默认值,表示仅仅展示执行计划信息;
- "executionStats":表示展示执行计划信息同时展示被选中的执行计划的执行情况信息;
- "allPlansExecution":表示展示执行计划信息,并展示被选中的执行计划的执行情况信息,还展示备选的执行计划的执行情况信息
- 3,合理建立索引
- 建立索引的规则:
- 1,索引很有用,但是它也是有成本的——它占内存,让写入变慢;
- 2,mongoDB通常在一次查询里使用一个索引,所以多个字段的查询或者排序需要复合索引才能更加高效;
- 3,复合索引的顺序非常重要,例如此脚本所示:
- 4,在生成环境构建索引往往开销很大,时间也不可以接受,在数据量庞大之前尽量进行查询优化和构建索引;
- 5,避免昂贵的查询,使用查询分析器记录那些开销很大的查询便于问题排查;
- 6,通过减少扫描文档数量来优化查询,使用explain对开销大的查询进行分析并优化;
- 7,索引是用来查询小范围数据的,不适合使用索引的情况:
- 1,每次查询都需要返回大部分数据的文档,避免使用索引
- 2,写比读多
- 优化目标:
- 1,根据需求建立索引
- 2,每个查询都要使用索引以提高查询效率, winningPlan. stage 必须为IXSCAN ;
- 3,追求totalDocsExamined = nReturned
2. 高可用
- 1,可复制集
- 可复制集是跨多个MongDB服务器(节点)分布和维护数据的方法。mongoDB可以把数据从一个节点复制到其他节点并在修改时进行同步,集群中的节点配置为自动同步数据;旧方法叫做主从复制,mongoDB 3.0以后推荐使用可复制集;
- 作用:
- 1,避免数据丢失,保障数据安全,提高系统安全性;
- (最少3节点,最大50节点)
- 2,自动化灾备机制,主节点宕机后通过选举产生新主机;提高系统健壮性;
- (7个选举节点上限)
- 3,读写分离,负载均衡,提高系统性能;
- 4,生产环境推荐的部署模式;
- 原理:
- 数据同步:从节点与主节点保持长轮询;1.从节点查询本机oplog最新时间戳;2.查询主节点oplog晚于此时间戳的所有文档;3.加载这些文档,并根据log执行写操作;
- 阻塞复制:与writeconcern相关,不需要同步到从节点的策略(如: acknowledged Unacknowledged 、w1),数据同步都是异步的,其他情况都是同步;
- 心跳机制:成员之间会每2s 进行一次心跳检测(ping操作),发现故障后进行选举和故障转移;
- 选举制度:主节点故障后,其余节点根据优先级和bully算法选举出新的主节点,在选出主节点之前,集群服务是只读的;
- 注意:
- MongoDB复制集里Primary节点是不固定的,所以生产环境千万不要直连Primary。
- 2,分片集群
- 分片是把大型数据集进行分区成更小的可管理的片,这些数据片分散到不同的mongoDB节点,这些节点组成了分片集群。
- 作用:
- 1,数据海量增长,需要更大的读写吞吐量:存储分布式
- 2,单台服务器内存、cpu等资源是有瓶颈的:负载分布式
- 注意:分片集群是个双刃剑,在提高系统可扩展性和性能的同时,增大了系统的复杂性,所以在实施之前请确定是必须的。
- 容易发生的状况:
- 请求分流:通过路由节点将请求分发到对应的分片和块中;
- 数据分流:内部提供平衡器保证数据的均匀分布,数据平均分布式请求平均分布的前提;
- 块的拆分:3.4版本块的最大容量为64M或者10w的数据,当到达这个阈值,触发块的拆分,一分为二;
- 块的迁移:为保证数据在分片节点服务器分片节点服务器均匀分布,块会在节点之间迁移。一般相差8个分块的时候触发;
- 分片注意点:
- 热点 :某些分片键会导致所有的读或者写请求都操作在单个数据块或者分片上,导致单个分片服务器严重不堪重负。自增长的分片键容易导致写热点问题;
- 不可分割数据块:过于粗粒度的分片键可能导致许多文档使用相同的分片键,这意味着这些文档不能被分割为多个数据块,限制了mongoDB均匀分布数据的能力;
- 查询障碍:分片键与查询没有关联,造成糟糕的查询性能。
- 建议:
- 1,不要使用自增长的字段作为分片键,避免热点问题;
- 2,不能使用粗粒度的分片键,避免数据块无法分割;
- 3,不能使用完全随机的分片键值,造成查询性能低下;
- 4,使用与常用查询相关的字段作为分片键,而且包含唯一字段(如业务主键,id等);
- 5,索引对于分区同样重要,每个分片集合上要有同样的索引,分片键默认成为索引;分片集合只允许在id和分片键上创建唯一索引;
三:MongoDB API
一、
二、
三、
MongoDB知识点总结的更多相关文章
- MongoDB知识点拾遗梳理
MongoDB数据库安装: >apt-get install mongodb 0.MongoDB状态查看.启动.停止 >/etc/init.d/mongodb status或s ...
- MongoDB 知识点
左边是mongodb查询语句,右边是sql语句.对照着用,挺方便. db.users.find() select * from users db.users.find({"age" ...
- 金九银十跳槽高峰,面试必备之 Redis + MongoDB 常问80道面试题
前言 有着“金九银十”之称的招聘旺季已经开启,跳槽高峰期也如约而至. 本文为主要是 Redis + MongoDB 知识点的攻略,希望能帮助到大家. 内容较多,大家准备好耐心和瓜子矿泉水. Redis ...
- 操作MongoDB数据库知识点
一.命令行操作mongo: 1.开启数据库 mongo 如果启动mongo报以下错误: 运行brew services start mongodb 2.创建数据库并进入实例 use test 3.查看 ...
- 一个线程知识点, 一个MongoDB的知识点
//WINForm窗体中切换前后台线程执行任务: protected void RunOnUI(Action action) { Invoke(action); } protected void Ru ...
- 前端知识点回顾——mongodb和mongoose模块
mongodb和mongoose模块 数据库 数据库有关系型数据库(MySQL)和非关系型数据库(mongodb),两者的语法和数据存储形式不一样. mySQL 关系型数据库 类似于表格的形式,每一条 ...
- MongoDB一些应用知识点
1.在生产环境中至少需要三个节点的复制集架构. 2.在多数的场景中WT引擎比MMAPv1更加出色. 3.要想达到极致的速度,那么一定要给MongoDB足够的内存. 4.避免使用短链接,充分利用连接池, ...
- 【干货分享】前端面试知识点锦集04(Others篇)——附答案
四.Others部分 技术类 1.http状态码有哪些?分别代表是什么意思? (1).成功2×× 成功处理了请求的状态码.200 服务器已成功处理了请求并提供了请求的网页.204 服务器成功处理了请求 ...
- MongoDB学习笔记(二:入门环境配置及与关系型数据库区别总结)
一.下载及安装MongoDB MongoDB下载官网链接:http://www.mongodb.org/downloads 具体安装步骤教程:http://www.shouce.ren/api/vie ...
随机推荐
- 记一条distinct 语句的优化。
语句是这条 SELECT DISTINCT bank, account FROM sdb_payments WHERE status="succ": status 上有索引,但不是 ...
- 「雕爷学编程」Arduino动手做(37)——MQ-3酒精传感器
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...
- k8s搭建实操记录一(master)
#1)关闭CentOS7自带的防火墙服务 systemctl disable firewalld systemctl stop firewalld swapoff -a ##虚拟机要关闭交换 ...
- STM32F103出现CPU could not be halted问题的解决方案
问题描述: **JLink Warning: CPU could not be halted ***JLink Error: Can not read register 15 (R15) while ...
- APM 上报信息分析与应用
在入正题之前我们再回顾下它的架构图: 本文章主要分析AMP各索引的作用,与及结合1.7环境上已接入的服务数据对比后,对索引中的主要字段进行解析.文章分为四个小章节. 1.索引类型 apm索引分为四种类 ...
- 【解决办法】IIS环境中,打开网站后就直接列出了所有文件
有时候访问一个不应当被访问的网站目录时网站会列出该目录下的所有文件,这很不安全,尤其是我们希望我们自己的网站不出现这种情况,如下图所示. 解决办法,在网站根目录新建web.config文件,内容如下: ...
- 通过swagger json一键解析为html页面、导出word和excel的解析算法分享
写在前面: 完全通过Spring Boot工程 Java代码,将swagger json 一键解析为html页面.导出word和execel的解析算法,不需要任何网上那些类似于“SwaggerMark ...
- Android_适配器(adapter)之ArrayAdapter
ArrayAdapter是一个很简单的适配器,是BaseAdapter的子类. ArrayAdapter绑定的数据是集合或数组,比较单一.视图是列表形式,ListView 或 Spinner. Arr ...
- require.js与IDEA的配合
本文主要讲述在html中使用requirejs时,如何让IDEA更加智能识别javascript的方法. 测试时的目录结构,一种典型的 thinkphp 的结构,同时,在 a.thml 中通过 req ...
- 02)php基础知识
综述 学习网址 菜鸟教程-PHP 所有学习内容皆来自以上网站. 基础 语法 PHP 脚本以 结束; PHP 文件的默认文件扩展名是 ".php". <?php echo &q ...