openstack cinder-backup流程与源码分析
在现在的云计算大数据环境下,备份容灾已经变成了一个炙手可热的话题,今天,和大家一起分享一下openstack是怎么做灾备的。
【首先介绍快照】
snapshot可以为volume创建快照,快照中保存了volume当前的状态,此后可以通过snapshot回溯。
主要采用了Copy On Write算法。进行快照时,不牵涉到任何档案复制动作,它所作的只是通知服务器将目前有数据的磁盘区块全部保留起来,不被覆写。
接下来档案修改或任何新增、删除动作,均不会覆写原本数据所在的磁盘区块,而是将修改部分写入其它可用的磁盘区块中。
资源的复制只有在需要写入的时候才进行,此前,是以只读方式共享,使实际的拷贝被推迟到实际发生写入的时候。
【备份和快照区别】
在openstack中,cinder主要负责volume的创建以及管理工作,cinder-backup负责备份操作,cinder-snapshot负责快照操作。
大家都知道,备份和快照具有类似的功能,都可以保存当前volume的内容,以便于以后进行恢复。但是二者在用途上是由差别的:具体表如有以下几点:
- snapshot依赖于源volume,不能独立存在;而backup不依赖于volume,就算volume被删除了,也可以单独做恢复。
- snapshot通常和源volume存储在一起,而backup一般会被作为异地容灾放在其他的存储后端。
以上两点,注定了快照和备份是作为不同用法出现的,快照主要用于便捷回溯,备份主要用于异地容灾。
【cinder-backup配置】
Cinder 的 backup 功能是由 cinder-backup 服务提供的,openstack 默认没有启用该服务,需要手工启用。
与 cinder-volume 类似,cinder-backup 也通过 driver 架构支持多种备份 backend,包括 POSIX 文件系统、NFS、Ceph、GlusterFS、Swift 和 IBM TSM。
支持的driver 源文件放在 /cinder/cinder/backup/drivers/中

不同的备份存储系统以Driver的形式得以支持,driver.py文件中定义了各种Driver的基类backupDriver,所有具体Driver的实现都位于drivers子目录,通过配置文件的backup_driver选项指定使用的Driver。
如:
|
backup_drive=cinder.backup.drivers.swift |
【backup基本流程】
cinder-backup服务在接到RPC请求后会找到该操作对应的host以及相应的存储后端Driver,然后调用该Driver中与backup相关的接口,比如backup_volume()和restore_backup(),这些接口最终会调用cinder-backup服务中Driver来对该Volume进行备份或者恢复操作。
下面代码是备份一个卷的入口(早期版本的代码,P版本代码比较冗长未列)
|
#cinder/backup/manager.py class BackupManager(manager.SchedulerDependentManager): def create_backup(self, context, backup_id): """Create volume backups using configured backup service.""" backup = self.db.backup_get(context, backup_id) #创建一个卷先找到对应的主机 volume_host = volume_utils.extract_host(volume['host'], 'backend') backend = self._get_volume_backend(host=volume_host) self.db.backup_update(context, backup_id, {'host': self.host, 'service': self.driver_name}) backup_service = self.service.get_backup_driver(context) #调用Driver中与backup相关的接口 self._get_driver(backend).backup_volume(context, backup, backup_service) |
工作流程大致如下:

cinder-api接收到备份请求后,会转发到cinder-backup,由cinder-backup负责监听请求并转发,中间会包括一些卷类型的检查以及服务的检测,这里不多说,我们主要查看driver的工作情况。
如下图所示:
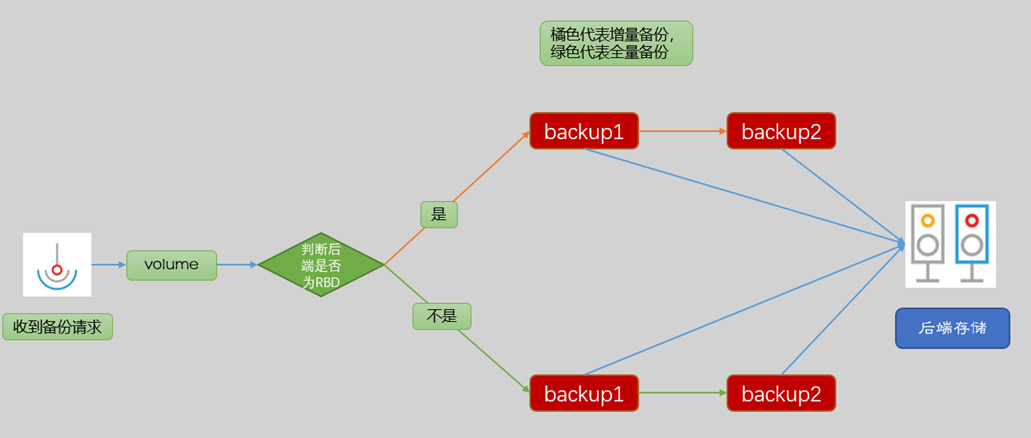
对于不同的备份后端,后文会对ceph和chunk两种模式分别做介绍。
【接口介绍】
表中,是backup相关的层次结构,备注了接口功能以及调用关系:
|
层次 |
功能 |
|
cinder-api的API层接口 |
暴露给客户端的API接口 |
|
cinder-backup的API层接口 |
将RPC的接口进行封装使被import |
|
cinder-backup的RPCAPI层接口 |
与manager.py进行交互 |
|
cinder-backup的manager层接口 |
与cinder-backup的driver进行交互 |
|
cinder-backup的driver层接口 |
与存储后端或后端提供的库进行交互 |
【代码结构】
|
/cinder/backup/__init__.py |
指定并导入cinder-backup的API类; |
|
/cinder/backup/api.py |
处理所有与卷备份服务相关的请求; class API(base.Base): 卷备份管理的接口API; 主要定义了卷的备份相关的三个操作的API: create:实现卷的备份的建立; delete:实现删除卷的备份; restore:实现恢复备份; 这三个操作都需要通过backup_rpcapi定义的RPC框架类的远程调用来实现; |
|
/cinder/backup/driver.py |
class BackupDriver(base.Base): 所有备份驱动类的基类; |
|
/cinder/backup/manager.py |
卷备份的管理操作的实现; 核心代码; class BackupManager(manager.SchedulerDependentManager):块存储设备的备份管理; 主要实现的是三个远程调用的方法: create_backup:实现卷的备份的建立(对应api.py中的create方法); restore_backup:实现恢复备份(对应api.py中的restore方法); delete_backup:实现删除卷的备份(对应api.py中的delete方法); |
|
/cinder/backup/rpcapi.py |
volume rpc API客户端类; class BackupAPI(cinder.openstack.common.rpc.proxy.RpcProxy):volume rpc API客户端类 主要实现了三个方法: create_backup:远程调用实现卷的备份的建立(对应api.py中的create方法); restore_backup:远程调用实现恢复备份(对应api.py中的restore方法); delete_backup:远程调用实现删除卷的备份(对应api.py中的delete方法); |
|
/cinder/backup/drivers/ceph.py |
ceph备份服务实现; class CephBackupDriver(BackupDriver):Ceph对象存储的Cinder卷备份类; 这个类确认备份Cinder卷到Ceph对象存储系统; |
|
/cinder/backup/drivers/swift.py |
用swift作为后端的备份服务的实现; class SwiftBackupDriver(ChunkedBackupDriver):用swift作为后端的备份服务的各种管理操作实现类; |
|
/cinder/backup/drivers/tsm.py |
IBM Tivoli存储管理(TSM)的备份驱动类; class TSMBackupDriver(BackupDriver):实现了针对TSM驱动的卷备份的备份、恢复和删除等操作; |
|
/cinder/backup/drivers/other driver |
同上 |
【chunk driver】
swift、nfs,Google,glusterfs,posix的备份是基于chunk的备份。
其中有两个参数解释一下:
|
chunk_size |
表示将volume分成多大的块进行备份。 在NFS中这个值叫做backup_file_size,默认是1999994880 Byte,大约1.8G。 在Swift中这个值叫做backup_swift_object_size,默认是52428800Byte,也就是50M。 在Ceph中这个值叫做backup_ceph_chunk_size,默认值是128M。 |
|
sha_block_size |
这个值用于增量备份,它决定了增量备份的粒度。 在NFS中,这个值叫做backup_sha_block_size_bytes。 在Swift中,这个值叫做backup_swift_block_size。 默认都是32768Byte,也就是32K。 在Ceph,没有对应的概念。 |
swift、nfs,Google,glusterfs,posix继承自ChunkedBackupDriver(/cinder/backup/chunkeddriver.py),实现机制为将原始volume拆分成chunk,然后保存到对应的存储上。
做全量备份时,每次从volume读入chunk_size字节数据,从头每sha_block_size个字节做一次SHA计算,并保存结果,然后将chunk_size数据(可压缩)保存到存储上,形成一个object,循环将整个volume保存到backend 上,会生成两个文件:metadata、sha256file。
其中metadata记录volume对应存储上的哪些object、object大小、压缩算法、长度、偏移量。
sha256file按顺序记录每次SHA计算结果。
当增量备份时,将每sha_block_size数据的SHA值与上次保存在sha256file中的SHA值比对,若不等则备份相应sha_block。
全量备份恢复时先指定volume id,通过metadata文件将存储端的备份文件和volume对应起来,而增量备份恢复时,由于增量备份的特性,使得增量备份间有依赖,形成备份链。
配置如下:
|
[DEFAULT] backup_driver = cinder.backup.drivers.nfs backup_mount_point_base = /backup_mount backup_share=172.16.8.99:/backup |
手动启动cinder-backup服务:
|
/usr/bin/python /usr/local/bin/cinder-backup --config-file /etc/cinder/cinder.conf |
我们可以通过日志去查看cinder-backup到底做了些什么事情:
- 启动 backup 操作,mount NFS。
- 创建 volume 的临时快照。
- 创建存放 backup 的 container 目录。
- 对临时快照数据进行压缩,并保存到 container 目录。
- 创建并保存 sha256(加密)文件和 metadata 文件。
- 删除临时快照。
Backup 完成后,可以通过 cinder backup-list 查看当前存在的 backup。
查看一下 container 目录的内容,发现下面有以下内容:
|
backup-00001 |
压缩后的 backup 文件 |
|
backup_metadata |
metadata 文件 |
|
backup_sha256file |
sha值文件 |
在cinder backup-create中有以下几个可选项:
|
--force |
允许 backup 已经 attached 的 volume |
|
--incremental |
表示可以执行增量备份。 |
【恢复操作】
restore 的过程其实很简单,两步走:
在存储节点上创建一个空白 volume。
将 backup 的数据 copy 到空白 volume 上。
详细流程如下:
- 向 cinder-api 发送 restore 请求
- cinder-api 发送消息
- cinder-scheduler 挑选最合适的 cinder-volume
- cinder-volume 创建空白 volume
- 启动 restore 操作,mount NFS。
- 读取 container 目录中的 metadata。
- 将数据解压并写到 volume 中。
- 恢复 volume 的 metadata,完成 restore 操作。
所以,其实对于卷恢复来讲,其实就是创建了一个与原备份卷时间点内容相同的新卷,不会对老的卷造成任何的影响。
【CEPH备份】
按照cinder-volume所用的backend分两种情况介绍:一种是使用非RBD作为backend,另一种是使用RBD作为backend。
cinder-volume使用非RBD作为backend
这种情况下比较简单,并且仅支持全量备份。
在创建备份时,首先创建一个base backup image,然后每次从源卷读入chunk_size(即backup_ceph_chunk_size,默认是128MB)大小的数据,写入到backup image,直到把整个源卷都复制完。
注意,这里不支持对chunk的压缩。
因为volume上的数据都会写入到创建的这个backup image上去,也就是说volume和backup是一对一的,因此也不需要metadata文件。
cinder-volume使用RBD作为backend
在这种情况下,即cinder-volume和cinder-backup都是用rbd作为backend,是支持增量备份的。
增量备份的实现完全依赖于ceph处理差量文件的特性,所谓ceph处理差量文件的能力,即ceph可以将某个rbd image不同时刻的状态进行比较,并且将其差量导出成文件。
另外,ceph也可以将这个差量文件导入到某个image中。
全量备份:
- 调用librbd创建backup base image,与源 volume 大小一致,name 的形式为 "volume-VOLUMD_UUID.backup.base"
- 调用cinder-volume的rbd driver获取该image相关元数据( 池子、用户、配置文件等);
- 从源卷传输数据到该image;
源 rbd image 新建一个快照,name形式为 backup.BACKUP_ID.snap.TIMESTRAMP
源rbd image 上使用 export-diff 命令导出从刚开始创建时到上一步快照时的差异数据,其实就是现在整个rbd的数据,然后通过import-diff将差量数据导入刚刚在备份集群上新创建的base image中。
增量备份:
- 判断是否有backup base image;
- 若没有,判断source image是否具有snap(from_snap),有的话删除该snap;
若有,寻找满足"^backup.([a-z0-9-]+?).snap.(.+)$" 的最近一次快照,若不存在则报错;
- 给source image创建一个新的snap,name 形式为 backup.BACKUP_ID.snap.TIMESTRAMP;
- 源rbd image 上使用export-diff命令导出与最近的一次快照比较的差量数据,然后使用import-diff进行数据传输。
ceph 增量备份其实就是基于ceph rbd的export-diff,import-diff 功能实现的:
|
export-diff |
将某个 rbd image 在两个不同时刻的数据状态比较不同后导出补丁文件。 |
|
import-diff |
将某个补丁文件合并到某个 rbd image 中。 |
恢复时相反,只需要从备份集群找出对应的快照并导出差量数据,导入到原volume即可。
openstack cinder-backup流程与源码分析的更多相关文章
- SpringMVC执行流程及源码分析
SpringMVC流程及源码分析 前言 学了一遍SpringMVC以后,想着做一个总结,复习一下.复习写下面的总结的时候才发现,其实自己学的并不彻底.牢固.也没有学全,视频跟书本是要结合起来一起, ...
- Android应用层View绘制流程与源码分析
1 背景 还记得前面<Android应用setContentView与LayoutInflater加载解析机制源码分析>这篇文章吗?我们有分析到Activity中界面加载显示的基本流程原 ...
- Struts2请求处理流程及源码分析
1.1 Struts2请求处理 1. 一个请求在Struts2框架中的处理步骤: a) 客户端初始化一个指向Servlet容器的请求: b) 根据Web.xml配置,请求首先经过ActionConte ...
- django Rest Framework----APIView 执行流程 APIView 源码分析
在django—CBV源码分析中,我们是分析的from django.views import View下的执行流程,这篇博客我们介绍django Rest Framework下的APIView的源码 ...
- cinder migrate基础内容-源码分析
一.cinder-api服务入口 D:\code-program\cinder-codejuno\api\contrib\admin_actions.py from cinder import vol ...
- Django 基于类的视图(CBV)执行流程 CBV 源码分析
一.CBV(基于类的视图) 视图是可以调用的,它接受请求并返回响应,这不仅仅是一个函数,Django提供了一些可以用作视图的类的例子,这些允许您通过继承或mixin来构建视图并重用代码. 基本示例 D ...
- Yarn任务提交流程(源码分析)
关键词:yarn rm mapreduce 提交 Based on Hadoop 2.7.1 JobSubmitter addMRFrameworkToDistributedCache(Configu ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- apiserver源码分析——启动流程
前言 apiserver是k8s控制面的一个组件,在众多组件中唯一一个对接etcd,对外暴露http服务的形式为k8s中各种资源提供增删改查等服务.它是RESTful风格,每个资源的URI都会形如 / ...
随机推荐
- Java实现 LeetCode 258 各位相加
258. 各位相加 给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数. 示例: 输入: 38 输出: 2 解释: 各位相加的过程为:3 + 8 = 11, 1 + 1 = 2. 由 ...
- Java实现蓝桥杯勾股定理
勾股定理,西方称为毕达哥拉斯定理,它所对应的三角形现在称为:直角三角形. 已知直角三角形的斜边是某个整数,并且要求另外两条边也必须是整数. 求满足这个条件的不同直角三角形的个数. [数据格式] 输入一 ...
- Java实现 蓝桥杯 历届试题 大臣的旅费
问题描述 很久以前,T王国空前繁荣.为了更好地管理国家,王国修建了大量的快速路,用于连接首都和王国内的各大城市. 为节省经费,T国的大臣们经过思考,制定了一套优秀的修建方案,使得任何一个大城市都能从首 ...
- 美女面试官问我Python如何优雅的创建临时文件,我的回答....
[摘要] 本故事纯属虚构,如有巧合,他们故事里的美女面试官也肯定没有我的美,请自行脑补... 小P像多数Python自学者一样,苦心钻研小半年,一朝出师投简历. 这不,一家招聘初级Python开发工程 ...
- OV2640读ID全是FF问题
最近刚好在Cyclone IV上通过LVDS把一个7寸的屏点亮,赶着热度,淘宝买了OV2640这个摄像头模块,初始化因为用Vrilog比C复杂得多,易调试性不如C,所以使用STM32初始化,模块有F3 ...
- Java培训Day02——制作疫情地图(一)
一.前言 此次培训,是为期三天的网上培训.最终的目的是制作出疫情地图.首先我们来看看主要的讲课内容大纲. Day1 |-Java语法学习(个人感觉讲得还可以,主要围绕本次培训作出的讲解,没有像网上的基 ...
- mysql基础-新版5.7.10源码安装-记录(一)
0x01 MySQL 从 5.5 版本开始,通过 ./configure 进行编译配置方式已经被取消,取而代之的是 cmake 工具 引用一句话 cmake的重要特性之一是其独立于源码(out-of- ...
- Spark Streaming + Kafka Integration Guide原文翻译及解析
前面写了关于kafka和spark streaming的结合使用(https://www.cnblogs.com/qfxydtk/p/11662591.html),其具体使用用法其实来自于原文:htt ...
- Nice Jquery Validator 自定义规则
规则定义方式 (1). 正则 适用于使用单个正则能搞定的验证. // 使用数组包裹正则和错误消息,规则不通过时提示该消息 mobile: [/^1[3458]\d{9}$/, '请检查手机号格式'] ...
- 关于微信小程序的文档-手撸
学习小程序的人如果有vue基础的话应该有很好的帮助作用.没有也关系,反正很简单. 首先理解一个完整的小程序app都有什么页面: pages页面放置所有的页面文件. 一个完整的小程序页面文件包括: in ...