JavaEE高级-Hibernate学习笔记
*什么是Hibernate?
> 一个框架
> 一个Java领域的持久层框架
> 一个ORM框架
*对象的持久化
> 狭义的理解:“持久化”仅仅指把对象永久保存到数据库中
> 广义的理解:“持久化”包括和数据库相关的各种操作:
- 保存:把对象永久保存到数据库中
- 更新:更新数据库中对象(记录)的状态
- 删除:从数据库中删除一个对象
- 查询:根据特定的查询条件,把符合查询条件的一个或多个对象从数据库加载到内存中
- 加载:根据特定的OID,把一个对象从数据库加载到内存中
*ORM(Object/Relation Mapping):对象/关系映射
> ORM主要解决对象-关系的映射
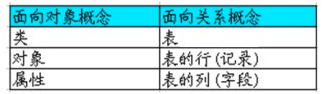
> ORM的思想:将关系数据库中表中的记录映射成为对象,以对象的形式展现,程序员可以把对数据库的操作转换为对对象的操作
> ORM采用元数据来描述对象-关系映射细节,元数据通常采用XML格式,并且存放在专门的对象-关系映射文件中
*流行的ORM框架
> Hibernate:
- 非常优秀、成熟的ORM框架
- 完成对象的持久化操作
- Hibernate允许开发者采用面向对象的方式来操作关系数据库
- 消除那些针对特定数据库厂商的SQL代码
> myBatis:
- 相对于Hibernate灵活性高、运行速度快
- 开发速度慢,不支持纯粹的面向对象操作,需要熟悉SQL语句,并且熟练使用SQL语句优化功能
> TopLink
> OJB
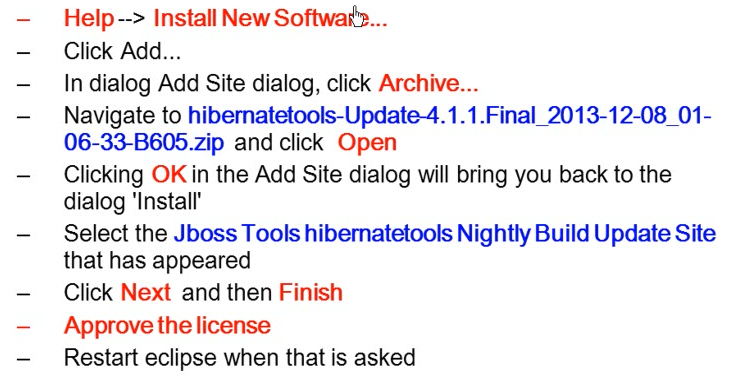
*安装hibernate插件
> 安装说明(hibernatetools-4.1.1.Final):
*准备Hibernate环境
> 导入Hibernate必须的jar包:
> 加入数据库驱动的jar包:

*Hibernate开发步骤
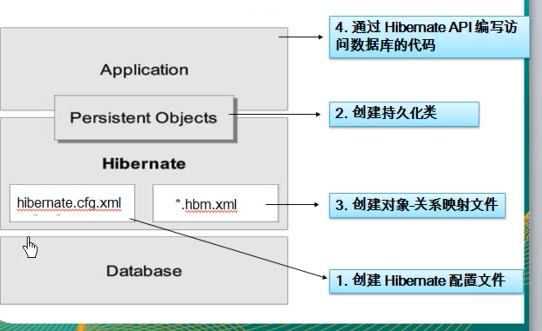
1.创建持久化Java类
> 提供一个无参构造器:使Hibernate可以使用Constructor.newInstance()来实例化持久类
> 提供一个标识属性(identifier property):通常映射为数据库表的主键字段,如果没有该属性,一些功能将不起作用,如:Session.saveOrUpdate()
> 为类的持久化类字段声明访问方法(get/set):Hibernate对JavaBean风格的属性实行持久化
> 使用非final类:在运行时生成代理是Hibernate的一个重要的功能,如果持久化类没有实现任何接口,Hibernate使用CGLIB生成代理,如果使用的是final类,则无法生成CGIB代理
> 重写equals和hashCode方法:如果需要把持久化类的实例放到Set中(当需要进行关映射时),则应该重写这两个方法
> Hibernate不要求持久化类继承任何父类或实现接口,这可以保证代码不被污染。这就是Hibernate被称为低侵入设计的原因
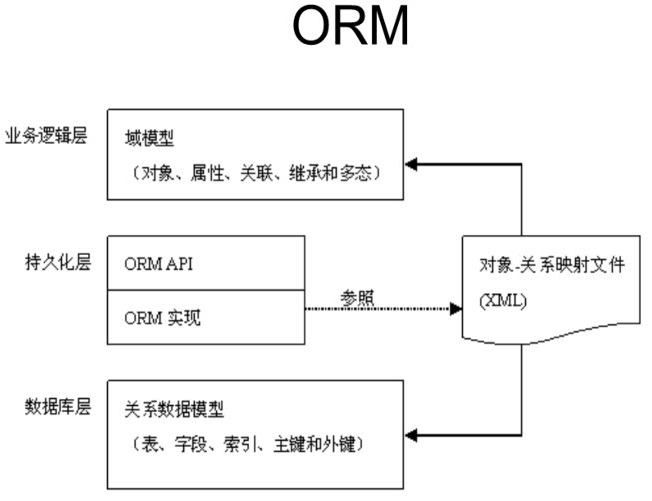
2.创建对象-关系映射文件
> Hibernate采用XML格式的文件来指定对象和关系数据之间的映射,在运行时Hibernate将根据这个映射文件来生成各种SQL语句
> 映射文件的扩展名为 .hbm.xml
3.创建Hibernate配置文件
> Hibernate从其配置文件中读取和数据库连接的有关信息,这个文件应该位于应用下的classpath下

4.通过HibernateAPI编写访问数据库的代码
> 测试代码
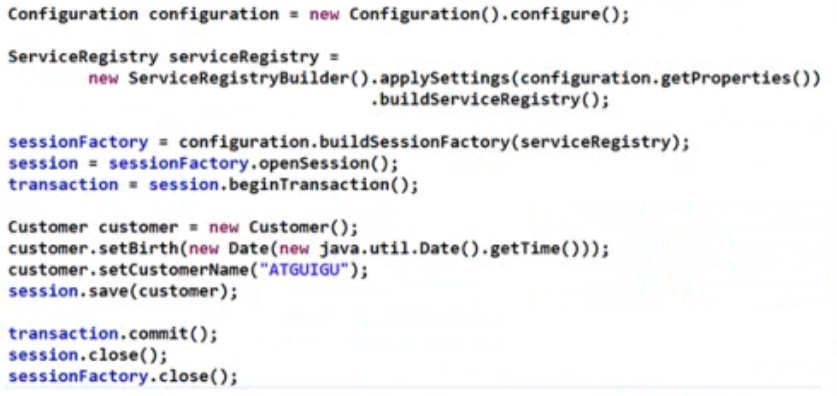
> 下边是控制台输出的SQL语句

*Configuration类
> Configuration类负责管理Hibernate的配置信息。包括如下信息内容:
- Hibernate运行的底层信息:数据库的URL、用户名、密码、JDBC驱动类,数据库Dialect,数据库连接池等(对应hibernate.cfg.xml文件)
- 持久化类与数据库的映射关系(*.hbm.xml文件)
> 创建Configuration的两种方式
- 属性文件(hibernate.properties):Configuration cfg = new Configuration();
- Xml 文件(hibernate.cfg.xml):Configuration cfg = new Configuration().configure();
- Configuration的configure方法还支持带参数的访问:
* File file = new File("simpleit.xml");
* Configuration cfg = new Configuration().configure(file);
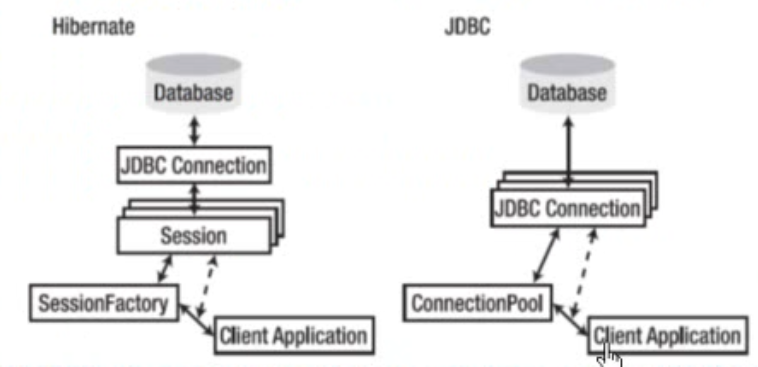
*SessionFactory接口
> 针对单个数据映射关系经过编译后的内存镜像,是线程安全的。
> SessionFactory对象一旦构造完成,即被赋予特定的信息
> SessionFactory是生成Session的工厂
> 构造SessionFactory很消耗资源,一般情况下一个应用中只初始化一个SessionFactory对象
> Hibernate4新增了一个ServiceRegistry接口,所有基于Hibernate的配置或者服务都必须统一向这个ServiceRegistry注册后才能生效
> Hibernate4中创建SessionFactory的步骤

*Session接口
> Session是应用程序与数据库之间交互操作的一个单线程对象,是Hibernate运作的中心,所有持久化对象必须在Session的管理下才可以进行持久化操作,此对象
的声明周期很短。Session对象有一个一级缓存,显示执行flush之前,所有的持久层操作的数据都缓存在Session对象中。相当于JDBC中的Connection
> 持久化类与Session关联起来后就具有了持久化的能力。
> Session类的方法:
- 取得持久化对象的方法:get()load()
- 持久化对象都得保存,更新和删除:save(),update(),saveOrUpdate(),delete()
- 开启事务:beginTransaction()
- 管理Session的方法:isOpen(),flush(),clear(),evict(),close()等
*Transaction(事务)
> 代表一次原子操作,它具有数据库事务的概念。所有持久化都应该在事务管理下进行,即使是只读操作
Transaction tx = session.beginTransaction();
> 常用方法:
- commit():提交相关联的session实例
- rollback():撤销事务操作
- wasCommitted():检查事务是否提交
*Hibernate配置文件的两个配置项
> hbm2ddl.auto:该属性可帮助程序员实现正向工程,即由java代码生成数据库脚本,进而生成具体的表结构。取值有:create | update | create-drop | validate
- create:会根据 .hbm.xml文件来生成数据表,但是每次运行都会删除上一次的表,重新生成表,哪怕二次没有任何改变
- create-drop:会根据 .hbm.xml 文件生成表,但是SessionFactory一关闭,表就会自动删除
- update:最常用的属性值,也会根据 .hbm.xml文件生成表,但若 .hbm.xml文件的数据库中对应的数据表的表结构不同,Hibernate将更新数据表结构,但不会删除已有的行和列
- validate:会和数据库中的表进行比较,若 .hbm.xml文件中的列在数据表中不存在,则抛异常
> format_sql:是否将SQL转化为格式良好额SQL. 取值 true | false
> Hibernate配置文件:
- Hibernate配置文件主要用于配置数据库连接和Hibernate运行时所需的各种属性
- 每个Hibernate配置文件对应一个Configuration对象
- Hibernate配置文件可以有两种格式:1)hibernate.properties 。2)hibernate.cfg.xml
- hibernate.cfg.xml的常用属性:
>> JDBC连接属性
- connection.url:数据库URL
- connection.username:数据库用户名
- connection.password:数据库用户密码
- connection.driver_class:数据库JDBC驱动
- dialect:配置数据库的方言,根据底层的数据库不同产生不同的SQL语句,Hibernate会针对数据库的特性在访问时进行优化
>> C3P0数据库连接池属性
- hibernate.c3p0.max_size:数据库连接池的最大连接数
- hibernate.c3p0.min_size:数据库连接池的最小连接数
- hibernate.c3p0.timeout:数据库连接池中连接对象在多长时间没有使用过后,就应该被销毁
- hibernate.c3p0.max_statements:缓存Statement对象的数量
- hibernate.c3p0.idle_test_period:表示连接池检测线程多长时间检测一次池内的所有链接对象是否超时. 连接池本身不会把自己从连接池中移除而是专门有一个线程按照
一定的时间间隔来做这件事,这个线程通过比较连接对象最后一次被使用时间和当前时间的时间差来和timeout做对比,进而决定是否撤销这个对象
- hibernate.c3p0.acquire_increment:当数据库连接池中的连接耗尽时,同一时刻获取多少个数据库连接
>>其他:
- show_sql:是否将运行期生成的SQL输出到日志以供调式。取值true | false
- format_sql:是否将SQL转化为格式良好的SQL. 取值true | false
- hbm2ddl.auto:在启动和停止时自动地创建、更新或删除数据库模式。取值create | update | create-drop | validate
- hibernate.jdbc.fetch_size
- hibernate.jdbc.batch_size
*通过Session操作对象
> Session概述
- Session接口是Hibernate向应用程序提供的操纵数据库的最主要的接口,它提供了基本的保存,更新,删除和加载Java对象的方法
- Session具有一个缓存,位于缓存中的对象称为持久化对象,它和数据库中的相关记录对应,Session能够在某个时间点,按照缓存中对象的变化来执行相关的SQL语句,来同步更新数据库,这一过程被称为刷新缓存(flush)
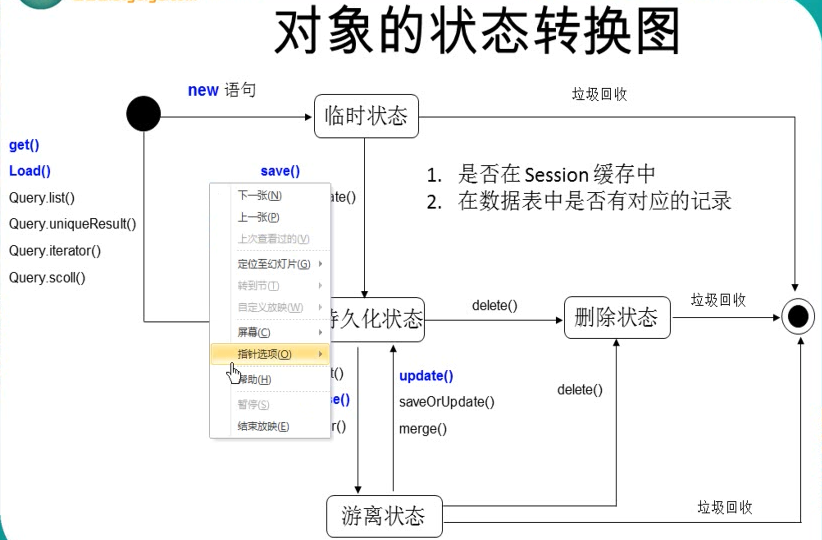
- 站在持久化的角度,HIbernate把对象分为4中状态:持久化状态,临时状态,游离状态,删除状态. Session的特定方法能是对象从一个状态转换到另一个状态
> Session缓存
- 在Session接口的实现中包含一系列的Java集合,这些Java集合构成了Session缓存,只要Session实例没有结束生命周期,存放在它缓存中的对象也不会结束生命周期

- Session缓存可减少Hibernate应用程序访问数据库的频率
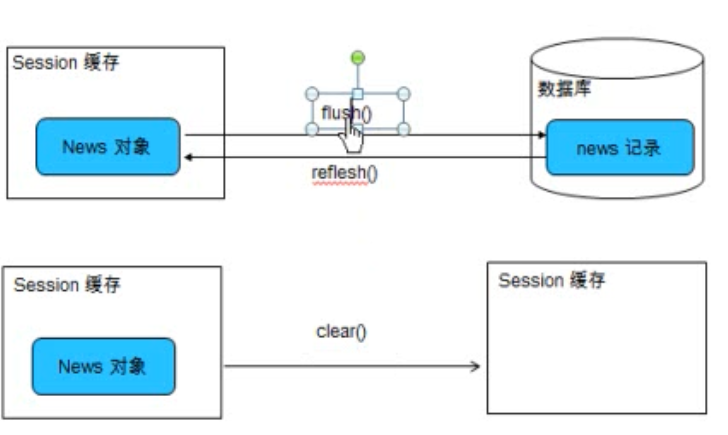
> flush缓存
- flush:Session按照缓存中对象的属性变化来同步更新数据库
- 默认情况下Session在以下时间点刷新缓存:
---> 显示调用Session的flush()方法
---> 当应用程序调用Transaction的commit()方法时,该方法先刷新缓存,然后再向数据库提交事务
---> 当应用程序执行一些查询(HQL,Criteria)操作时,如果缓存中持久化对象的属性已经发生了变化,会先flush缓存,以保证查询结果能够反映持久化对象的最新状态
- flush缓存的例外情况:如果对象使用native生成器生成OID,那么当调用Session的save()方法保存对象时,会立即执行向数据库插入该实体的insert语句
- commit()和flush()方法的区别:flush执行一系列SQL语句,但不提交事务;commit方法先调用flush()方法,然后提交事务,提交事务意味着对数据库操作永久保存下来
- 设定刷新缓存的时间点

> 数据库的隔离级别
- 对于同时运行的多个事务,当这些事务访问数据库中相同额数据时,如果没有采取必要的隔离机制,就会导致各种并发问题:
---> 脏读:对于两个事务T1,T2,T1读取了已经被T2更新但还没有被提交的字段,之后,若T2回滚,T1读取的内容就是临时无效的
---> 不可重复读:对于两个事务T1,T2,T1读取了一个字段,然后T2更新了该字段,之后,T1再次读取同一个字段,值就不同了
---> 幻读:对于两个事务T1,T2,T1从一个表中读取了一个字段,如何T2在该表中插入了一些新的行,之后,若T1再次读取同一个表,就会多出几行
- 数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力,使它们不会相互影响,避免各种并发问题
- 一个事务与其他事务隔离的程度称为隔离级别,数据库规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱
- 数据库提供的4中事务隔离级别

- 在MySQL中设置隔离级别

- 在Hibernate中设置隔离级别

> 对象的状态转换图
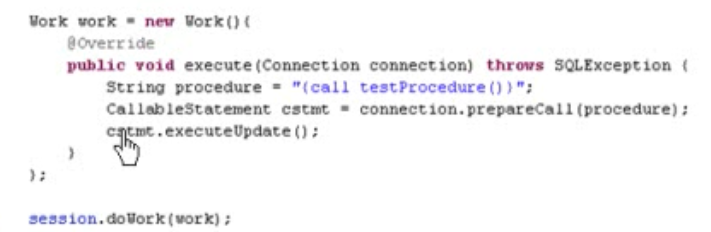
> 通过Hibernate调用存储过程
- Work接口:直接通过JDBC API来访问数据库的操作

- Session的doWork(Work)方法用于执行Work对象指定的操作,即调用Work对象的execute()方法,Session会把当前使用的数据库传递给execute()方法
> Hibernate与触发器协同工作
- Hibernate与数据库中的触发器协同工作,会造成两类问题:
---> 触发器是Session的缓存中的持久化对象与数据库中对应的数据不一致:触发器运行在数据库中,它执行的操作对Session是透明的
---> Session的update()方法盲目地激发触发器:无论游离对象的属性是否发生变化,都会执行update语句,而update语句会激发数据库中相应的触发器
- 解决方案:
---> 在执行完Session的相关操作后,立即调用Session的flush()和refresh()方法,迫使Session的缓存与数据库同步

---> 在映射文件的<class>元素中设置select-before-update属性:当Session的update或saveOrUpdate()方法更新一个游离对象时,会先执行select语句,
获得当前游离对象在数据库中的最新数据,只有在不一致的情况下才会执行update语句
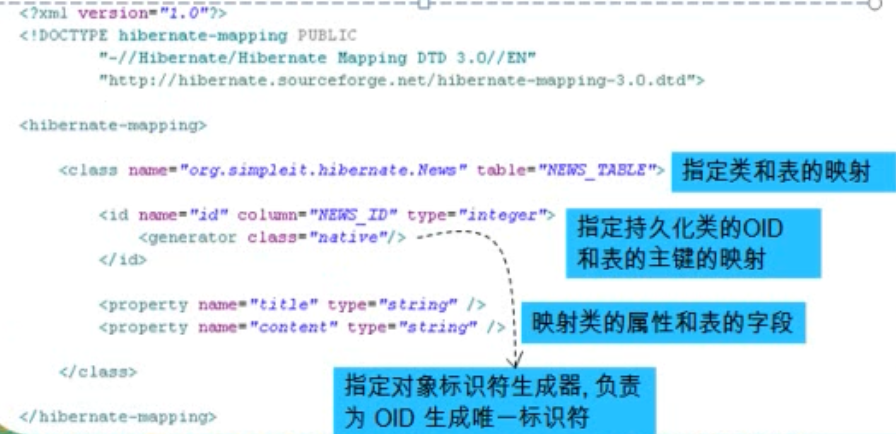
*对象关系映射文件
- POJO类和数据库的映射文件 *.hbm.xml
> POJO类和关系数据库之间的映射可以用一个XML文档来定义
> 通过POJO类的数据库映射文件,Hibernate可以理解持久化类和数据库表之间的对应关系,也可以理解持久化类属性与数据库表列之间的对应关系
> 在运行是Hibernate将根据这个映射文件来生成各种SQL语句
> 映射文件的扩展名为 .hbm.xml
- 映射文件说明
> hibernate-mapping
类层次:class
>> 主键:id
>> 基本类型:property
>> 实体引用类:many-to-one | one-to-one
>> 集合:set | list | map | array
--- one-to-many
--- many-to-many
>> 子类:subclass | joined-subclass
>> 其它:component | any等
查询语句:query
>> 用来放置查询语句,便于对数据库查询的统一管理和优化
> 每个Hibernate-mapping中可以同时定义多个类,但更推荐为每个类都创建一个单独的映射文件
- 映射对象标识符
> Hibernate使用对象标识符(OID)来建立内存中的对象和数据库表中记录的对应关系. 对象的OID和数据表的主键对应. HIbernate通过标识符生成器来为主键赋值
> HIbernate推荐在数据库表中使用代理主键,即不具备业务含义的字段. 代理主键通常为整数类型,因为整数类型比字符串类型要节省更多的数据库空间
> 在对象-关系映射文件中,<id>元素用来设置对象标识符. <generator>子元素用来设定标识符生成器
> HIbernate提供了标识符生成器接口:IdentifierGenerator,并提供了各种内置实现
- increment标识符生成器
> increment标识符生成器由Hibernate以递增的方式为代理主键赋值
> Hibernate会先读取NEWS表中的主键的最大值,而接下来向NEWS表中插入记录时,就在max(id)的基础上递增,增量为1.
> 适用范围:
由于increment生成标识符机制不依赖于底层数据库系统,因此它适合所有的数据库系统
适用与只有单个Hibernate应用进程访问同一个数据库的场合,在集群环境下不推荐使用
OID必须为long,int或short类型,如果把OID定义为byte类型,在运行时会抛异常
- identity标识符生成器
> identity标识符生成器由底层数据库来负责生成标识符,它要求底层数据库把主键定义为自动增长字段类型
> 适用范围:
由于identity生成标识符的机制依赖于底层数据库系统,因此,要求底层数据库系统必须支持自动增长字段类型,支持自动增长字段类型的数据库包括:DB2、MySQL,MSSQLServer、Sybase等
OID必须为long,int或short类型,如果把OID定义为byte类型,在运行时会抛异常
- native标识符生成器
> native标识符生成器依据底层数据库对自动生成标识符的支持能力,来选择使用identity,sequence或hilo标识符生成器
> 适用范围:
由于native能根据底层数据库系统的类型,自动选择合适的标识符生成器,因此很适合于数据库跨平台开发
OID必须为long,int或short类型,如果把OID定义为byte类型,在运行时会抛异常
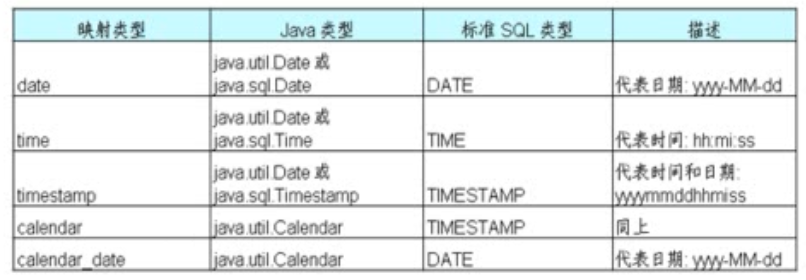
- Java时间和日期类型的Hibernate映射
> 在Java中,代表时间和日期的类型包括:java.util.Date和java.util.Calendar. 此外,在JDBC API中还提供了3个扩展java.util.Date类的子类:java.sql.Date,
java.sql.Time和java.sql.Timestamp,这三个类分别和标准SQL类型中的DATE,TIME和TIMESTAMP类型对应
> 在标准SQL中,DATE类型表示日期,TIME类型表示时间,TIMESTAMP类型表示时间戳,同时包含日期和时间信息
- 映射组成关系
> 建立域模型和关系数据模型有着不同的出发点:
>> 域模型:由程序代码组成,通过细化持久化类的粒度可提高代码的可重用性,简化编程
>> 在没有数据冗余的情况下,应该尽可能减少表的数目,简化表之间的参数关系,以便提高数据的访问速度
> Hibernate把持久化类的属性分为两种:
>> 值(value)类型:没有OID,不能被单独持久化,生命周期依赖于所属的持久化类的对象的生命周期
>> 实体(entity)类型:有OID,可以被单独持久化,有独立的声明周期
> 显然无法直接用property映射pay属性
> Hibernate使用<component>元素来映射组成关系,该元素表名pay属性是Worker类的一个组成部分,在Hibernate中称之为组件
> component
- <component>元素用来映射组成关系
>> class:设定组成关系属性的类型,此处表明pay属性为Pay类型
- <parent>元素指定组价属性所属的整体类
>> name:整体类在组件类中的属性名
- <set>元素的inverse属性
> 在hibernate中通过对inverse属性来决定是由双向关联的哪一方来维护表和表之间的关系. inverse=false的为主动方,inverse=true的为被动方,由主动方负责维护关联关系
> 在没有设置inverse=true的情况下,父子两边都维护父子关系
> 在1-n关系中,将n方设为主控方将有助于性能改善
> 在1-N关系中,若将1方设为主控方:
- 会额外多出update语句
- 插入数据时无法同时插入外键列,因而无法为外键列添加非空约束
- <set>元素的cascade属性
> 在对象-关系映射文件中,用于映射持久化类之间关联关系的元素,<set>,<many-to-one>和<one-to-one>都有一个cascade属性,它用于指定如何操纵与当前对象关联的其他对象

- <set>元素的order-by属性
> 如果设置了该属性,当Hibernate通过select语句到数据库中检索集合对象时,利用order by子句进行排序
> order-by属性中还可以加入SQL函数

*映射一对多关联关系
- 一对多关联关系
> 在领域模型中,类与类之间最普遍的关系就是关联关系
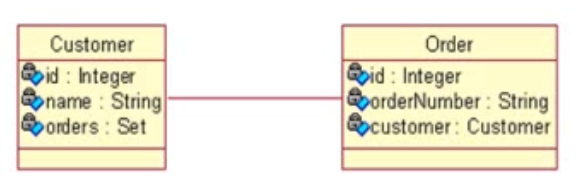
> 在UML中,关联是有方向的.
>> 以Customer和Order为例:一个用户能发出多个订单,而一个订单只能属于一个用户,从Order到Customer的关联是多对一关联,而从Customer到Order 是一对多关联
>> 单向关联

>> 双向关联

> 单向n-1
>> 单向n-1关联只需从n的一端可以访问1的一端
>> 域模型:从Order到Customer的多对一单向关联需要在Order类中定义一个Customer属性,而在Customer类中无需定义存放Order对象的集合属性
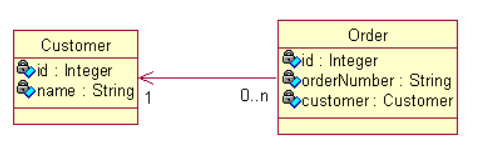
>> 关系数据模型:ORDERS表中的CUSTOMER_ID参照CUSTOMER表的主键

>> 显然无法直接用property映射customer属性
>> HIbernate使用<many-to-one>元素来映射多对一关联关系

>> <many-to-one>元素用来映射组成关系
---> name:设定待映射的持久化类的属性的名字
---> column:设定和持久化类的属性对应的表的外键
---> class:设定待映射的持久化类的属性的类型
> 双向1-n
>> 双向1-n和n-1是完全相同的两种情形
>> 双向1-n需要在1的一端可以访问n的一端,同样,n的一端也可以访问1的一端
>> 域模型:从Order到Customer的多对一双向关联需要在Order类中定义一个Customer属性,而在Customer类中需定义一个存放Order对象的集合属性
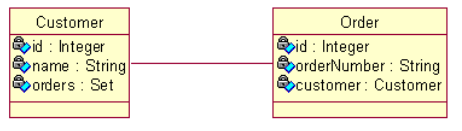
>> 关系数据模型:ORDERS表中的CUSTOMER_ID参照CUSTOMER表的主键

>> 当Session从数据库中加载Java集合时,创建的是Hibernate内置集合类的实例,因此在持久化类中定义集合属性时必须把属性声明为Java接口类型
Hibernate的内置集合类具有代理功能,支持延迟检索策略
事实上,Hibernate的内置集合类封装了JDK中的集合类,这使得Hibernate能够对缓存中的集合对象进行脏检查,按照集合对象的状态来同步更新数据库。
>> 在定义集合属性时,通常把它初始化为集合实现类的一个实例. 这样可以提高程序的健壮性,避免应用程序访问取值为null的集合抛出NullPointerException

>> Hibernate使用<set>元素来映射set类型的属性

>> <set>元素用来映射持久化类的set类型的属性
- name:设定待映射的持久化类的属性
- key:元素设定与所关联的持久化类对应的表的外键,column ----> 指定关联表的外键名
- one-to-many:元素设定集合属性中所关联的持久化类,class ---> 指定关联的持久化类的类名
*映射一对一关联关系
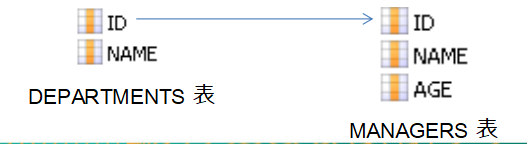
> 1-1:
- 域模型

- 关系数据模型:
>> 按照外键映射:
>> 按照主键映射:
- 基于外键映射的1-1
>> 对于基于外键的1-1关联,其外键可以存放在任意一边,在需要存放外键的一端,增加many-to-one元素。为many-to-one元素增加unipue="true"属性来表示为1-1关联

>> 另一端需要使用one-to-one元素,该元素使用property-ref属性指定使用被关联实体主键以外的字段作为关联字段
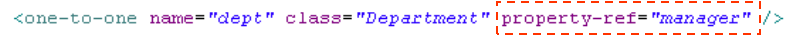
- 基于主键映射的1-1
>> 基于主键的映射策略:指一端的主键生成器使用foreign策略,表明根据“对方”的主键来生成自己的主键,自己并不能独立生成主键. <param>子元素指定使用当前持久化类的哪个属性作为“对方”

>> 采用foreign主键生成器策略的一端增加one-to-one元素映射关联属性,其one-to-one属性还应增加constrained="true"属性;另一端增加one-to-one元素映射关联属性
>> constrained(约束):指定为当前持久化类对应的数据库表的主键添加一个外键约束,引用被关联的对象(“对方”)所对应的数据库表主键

*映射多对多关联关系
> 单向n-n
- 域模型:
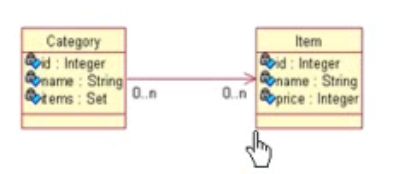
- 关系数据模型:
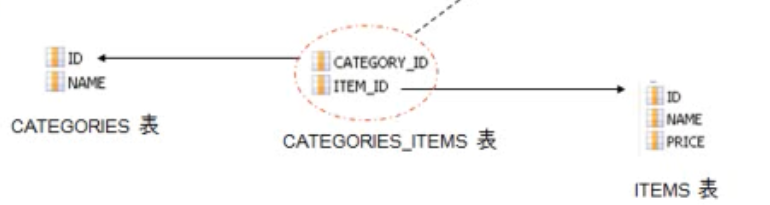
- n-n的关联必须使用连接表
- 与1-n映射类似,必须为set集合元素添加key子元素,指定CATEGORIES_ITEMS表中参照CATEGORIES表的外键为CATEGORIY_ID. 与1-n关联映射不同的是,建立n-n关联时,集合中的元素
使用many-to-many. many-to-many子元素的class属性指定items集合中存放的是Item对象,column属性指定CATEGORIES_ITEMS表中参照ITEMS表的外键为ITEM_ID

> 双向n-n
- 域模型:
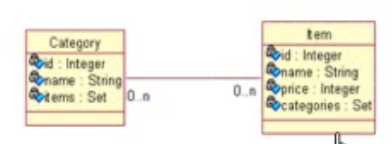
- 关系数据模型
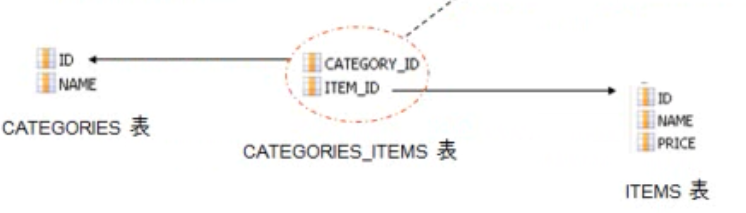
- 双向n-n关联需要两端都使用集合属性
- 双向n-n关联必须使用连接表
- 集合属性应增加key子元素用以映射外键列,集合元素里还应增加many-to-many子元素关联实体类
- 在双向n-n关联的两边都需指定连接表的表名及外键列的列名. 两个集合元素set的table元素的值必须指定,而且必须相同。set元素的两个子元素:key和many-to-many的都必须指定column属性,
其中,key和many-to-many分别指定本持久化类和关联类在连接表中的外键列名,因此两边的key与many-to-many的column属性交叉相同。也就是说,一边的set元素的key的column值为a,
many-to-many的column为b;则另一边的set元素的key的column值为b,many-to-many的column值为a
- 对于双向n-n关联,必须把其中一端的inverse设置为true,否则两端都维护关联关系可能会造成主键冲突
*继承映射
- 对于面向对象的程序设计语言而言,继承和多态是两个最基本的概念。Hibernate的继承映射可以理解为持久化类之间的继承关系。
例如:人和学生之间的关系。学生继承了人,可以认为学生是一个特殊的人,如果对人进行查询,学生的实例也将被得到。
- Hibernate支持三种继承映射策略:
> 使用subclass进行映射:将域模型中的每一个实体对象映射到一个独立的表中,也就是说不用在关系数据模型中考虑模型中的继承关系和多态
> 使用joined-subclass进行映射:对于继承关系中的子类使用同一个表,这就需要在数据库表中增加额外的区分子类类型的字段
> 使用union-subclass进行映射:域模型中的每个类映射到一个表,通过关系数据模型中的外键来描述表之间的继承关系。这也就相当于按照域模型的结构来建立数据库中的表,并通过外键来建立表之间的继承关系
- 采用subclass元素的继承映射
> 采用subclass的继承映射可以实现对于继承关系中父类和子类使用同一张表
> 因为父类和子类的实例全部保存在同一张表中,因此需要在该表内增加一列,使用该列来区分每行记录到底是哪个类的实例,此列被称为辨别者列(discriminator)
> 在这种映射策略下,使用subclass来映射子类,使用class或subclass的discriminator-value属性指定辨别者列的值
> 所有子类定义的字段都不能有非空约束。若为那些字段添加非空约束,则父类的实例在那些列中其实没有值,这将引起数据库完整性冲突,导致父类的实例无法保存到数据库中
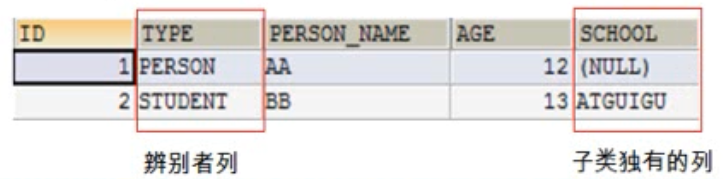
- 采用joined-subclass元素的继承映射
> 采用joined-subclass元素的继承映射可以实现每个子类一张表
> 采用这种映射策略时,父类实例保存在父类表中,子类实例由父类表和子类表共同存储。因为子类实例也是一个特殊的父类实例,因此必然也包含了父类实例的属性。
于是将子类和父类共有的属性保存在父类表中,子类增加的属性,则保存在子类表中。
> 在这种映射策略下,无须使用辨别者列,但需要为每个子类使用key元素映射共有主键
> 子类增加的属性可以添加非空约束。因为子类的属性和父类的属性没有保存在同一个表中

- 采用union-subclass元素的继承映射
> 采用union-subclass元素可以实现将每一个实体对象映射到一个独立的表中
> 子类增加的属性可以有非空约束,即父类实例的数据保存在父表中,而子类实例的数据保存在子类表中。
> 子类实例的数据仅保存在子类表中,而在父类表中没有任何记录
> 在这种映射策略下,子类表的字段会比父类表的映射字段多,因为子类表的字段等于父类表的字段加子类增加属性的总和
> 在这种策略下,既不需要使用辨别者列,也不需要使用key元素来映射共有主键
> 使用union-subclass映射策略hi不可使用identity的主键生成策略的,因为同一类继承层次中所有实体类都需要使用同一主键种子,即多个持久化实体对应的记录的主键应该是连续的,受此影响,
也不该使用native主键生成策略,因为native会根据数据库来选择使用identity或sequence

- 三种继承映射方式的比较

*Hibernate检索策略
- 概述:
> 检索数据时的2个问题:
>> 不浪费内存:当HIbernate从数据库中加载Customer对象时,如果同时加载所有关联的Order对象,而程序实际上仅仅需要访问Customer对象,那么这些关联的Order对象就白白浪费了许多内存
>> 更高的查询效率:发送尽可能少的SQL语句
- 类级别的检索策略:
> 无论<class>元素的lazy属性是true还是false,session的get()方法及Query的list()方法在类级别总是使用立即检索策略
> 若<class>元素的lazy属性为true或取默认值,Session的load()方法不会执行查询数据表的SELECT语句,仅返回代理类对象的实例,该代理类实例有如下特征:
- 由Hibernate在运行时采用CGLIB工具动态生成
- Hibernate创建代理类实例时,仅初始化其OID属性
- 在应用程序第一次访问代理类实例的非OID属性时,Hibernate会初始化代理类实例
> 类级别可选的检索策略包括立即检索和延迟检索,默认为延迟检索
- 立即检索:立即加载检索方法指定的对象
- 延迟检索:延迟加载检索方法指定的对象
> 类级别的检索策略可以通过<class>元素的lazy属性进行设置
> 如果程序加载一个对象的目的是为了访问它的属性,可以采用立即检索,如果程序加载一个持久化对象的目的仅仅为了获得它的引用,可以采用延迟检索
- 一对多和多对多的检索策略
> 在映射文件中,用<set>元素来配置一对多关联及多对多关联关系. <set>元素有lazy和fetch属性
- lazy:主要决定order集合被初始化的时机,即是在加载Customer对象时就被初始化,还是在程序访问order集合时被初始化
- fetch:取值为“select”或"subselect"时,决定初始化order的查询语句的形式,若取值为“join”,则决定order集合被初始化时机
- 若把fetch设置为“join”,lazy属性将被忽略
- <set>元素的batch-size属性:用来为延迟检索策略或立即检索策略设定批量检索的数量,批量检索能减少SELECT语句的数目,提高延迟检索或立即检索的运行性能
- <set>元素的fetch属性:取值为“select”或“subselect”时,决定初始化order的查询语句的形式;若取值为“join”,则决定orders集合被初始化的时机,默认值为select
- 当fetch属性为“subselect”时:
>> 假定Session缓存中有n个orders集合代理类实例没有被初始化,Hibernate能够通过带子查询的select语句,来批量初始化n个orders集合代理类实例
>> batch-size属性将被忽略
>> 子查询中的select语句为最初查询CUSTOMERS表OID的SELECT语句
- 当fetch属性为“join”时:
>> 检索Customer对象时,会采用迫切左外连接(通过左外连接加载与检索指定的对象关联的对象)策略来检索所有关联的Order对象
>> lazy属性将被忽略
>> Query的list()方法会忽略映射文件中配置的迫切左外连接检索策略,而依旧采用延迟加载策略
- 延迟检索和增强延迟检索
> 在延迟检索(lazy属性值为true)集合属性时,Hibernate在以下情况下初始化集合代理类实例
- 应用程序第一次访问集合属性:iterator(),size(),isEmpty(),contains()等方法
- 通过Hibernate.initialize()静态方法显示初始化
> 增强延迟检索(lazy属性为extra):与lazy="true"类似. 主要区别是增强延迟检索策略能进一步延迟Customer对象的order集合代理实例的初始化时机:
- 当程序第一次访问orders属性的iterator()方法时,会导致orders集合代理类实例的初始化
- 当程序第一次访问order属性的size()、contains()和isEmpty()方法时,Hibernate不会初始化orders集合类的实例,仅通过特定额select语句查询必要的信息,不会检索所有的Order对象
- 多对一和一对一关联的检查策略
> 和<set>一样,<many-to-one>元素也有一个lazy属性和fetch属性

> 若fetch属性设为join,那么lazy属性被忽略
> 迫切左外连接检索策略的优点在于比立即检索策略使用的SELECT语句更少
> 无代理延迟检索需要增强持久化类的字节码才能实现
> Query的list方法会忽略映射文件配置的迫切左外连接检索策略,而采用延迟检索策略
> 如果在关联级别使用了延迟加载或立即加载检索策略,可以设定批量检索的大小,以帮助提高延迟检索或立即检索的运行性能
> Hibernate允许在应用程序中覆盖映射文件中设定的检索策略
- 检索策略小结
> 类级别和关联级别可选的检索策略及默认的检索策略

> 3种检索策略的运行机制
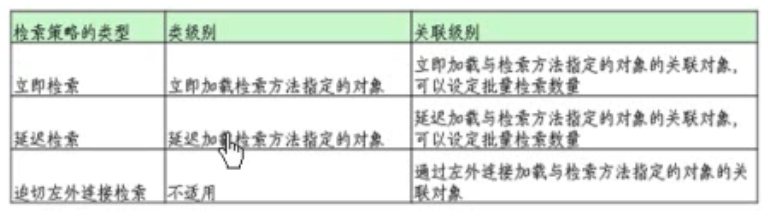
> 映射文件中用于设定检索策略的几个属性

*Hibernate检索方式
- Hibernate提供了以下几种检索对象的方式:
> 导航对象图检索方式:根据已经加载的对象导航到其他对象
> OID检索方式:按照对象的OID来检索对象
> HQL检索方式:使用面向对象的HQL查询语言
> QBC检索方式:使用QBC(Query By Criteria)API来检索对象. 这种API封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口
> 本地SQL检索方式:使用本地数据库的SQL查询语句
* HQL(Hibernate Query Language)是面向对象的查询语言,它和SQL查询语言有些相似。在Hibernate提供的各种检索方式中,HQL是使用最广的一种检索方式,它有如下功能:
> 在查询语句中设定各种查询条件
> 支持投影查询,即仅检索出对象的部分属性
> 支持分页查询
> 支持连接查询
> 支持分组查询,允许使用HAVING和GROUP BY关键字
> 提供内置聚集函数,如sum()、min()、max()
> 支持子查询
> 支持动态绑定参数
> 能够调用用户定义的SQL函数或标准的SQL函数
- HQL检索方式
> HQL检索方式包括以下步骤:
>> 通过Session的createQuery()方法创建一个Query对象,它包括一个HQL查询语句,HQL查询语句中可以包含命名参数
>> 动态绑定参数
>> 调用Query相关方法执行查询语句
> Query接口支持方法链编程风格,它的setXxx()方法返回自身实例,而不是void类型
> HQL vs SQL:
>> HQL查询语句是面向对象的,Hibernate负责解析HQL查询语句,然后根据对象-关系映射文件中的映射信息,把HQL查询语句翻译成相应的SQL语句,HQL查询语句中的主体是域模型中的类及类的属性
>> SQL查询语句是与关系数据库绑定在一起的. SQL查询语句中的主体是数据库表及表的字段
> 绑定参数:
>> Hibernate的参数绑定机制依赖与JDBC API中的PreparedStatement的预定义SQL语句功能
>> HQL的参数绑定有两种形式:
* 按参数名字绑定:在HQL查询语句中定义命名参数,命名参数以“:”开头
* 按参数位置绑定:在HQL查询语句中用“?”来定义参数位置
>> 相关方法:
* setEntity():把参数与一个持久化类绑定
* setParameter():绑定任意类型的参数. 该方法的第三个参数显示指定Hibernate映射类型
> HQL采用ORDERBY关键字对查询结果排序
- 分页查询:
> setFirstResult(int firstResult):设定从哪一个对象开始检索,参数firstResult表示这个对象在查询结果中的索引位置,索引位置的起始值为0,默认情况下,Query从查询结果中的第一个对象开始检索
> setMaxResults(int maxResults):设定一次最多检索出的对象的数目,在默认情况下,Query和Criteria接口检索出查询结果中所有的对象
- 在映射文件中定义命名查询语句
> Hibernate允许在映射文件中定义字符串形式的查询语句
> <query>元素用于定义一个HQL查询语句,它和<class>元素并列.

> 在程序中通过Session的getNamedQuery()方法获取查询语句对应的Query对象
- 投影查询
> 投影查询:查询结果仅包含实体的部分属性. 通过SELECT关键字实现
> Query的list()方法返回的集合中包含的是数组类型的元素,每个对象数组代表查询结果的一条记录
> 可以在持久化类中定义一个对象的构造器来包装投影查询返回的记录,使程序代码可以完全运用面向对象的语义来访问查询结果集
> 可以通过DISTINCT关键字来保证查询结果不会返回重复元素
- 报表查询
> 报表查询用于对数据分组和统计,与SQL一样,HQL利用GROUP BY 关键字对数组分组,用HAVING关键字对分组数据设定约束条件
> 在HQL查询语句中可以调用以下聚集函数
count()、min()、max()、sum()、avg()
- HQL(迫切)左外连接
> 迫切左外连接:
>> LEFT JOINFETCH关键字表示迫切左外连接检索策略
>> list()方法返回的集合中存放实体对象的引用,每个Department对象关联的Employee集合都被初始化,存放所有关联的Employee的实体对象
>> 查询结果中可能会包含重复元素,可以通过一个HashSet来过滤重复元素
> 左外连接:
>> LEFT JOIN关键字表示左外连接查询
>> list()方法返回的集合中存放的是对象数组类型
>>根据配置文件来决定Employee集合的检索策略
>> 若希望list()方法返回的集合中仅包含Department对象,可以在HQL查询语句中使用SELECT关键字
- HQL(迫切)内连接
> 迫切内连接:
>> INNER JOIN FETCH关键字表示迫切内连接,也可以省略INNER关键字
>> list()方法返回的集合中存放Department对象的引用,每个Department对象的Employee集合都被初始化,存放所有关联的Employee对象
> 内连接:
>> INNER JOIN 关键字表示内连接,也可以省略INNER关键字
>> list()方法的集合中存放的每个元素对应查询结果的一条记录,每个元素都是对象数组类型
>> 如果希望list()方法返回的集合仅包含Department对象,可以在HQL查询语句中使用SELECT关键字
- 关联级别运行时的检索策略
> 若在HQL中没有显示指定检索策略,将使用映射文件配置的检索策略
> HQL会忽略映射文件中设置的迫切左外连接检索策略,若希望HQL采用迫切左外连接策略,就必须在HQL查询语句中显示的指定它
> 若在HQL代码中显示指定了检索策略,就会覆盖映射文件中的检索策略
- QBC检索和本地SQL检索
> QBC查询就是通过使用Hibernate提供的Query By Criteria API来查询对象,这种API封装了SQL语句的动态拼装,对查询来提供了更加面向对象的功能接口
> 本地SQL查询来完善HQL不能涵盖所有的查询特性
* Hibernate缓存
- 缓存(Cache):计算机领域非常通用的概念。它介于应用程序和永久性数据存储源(如硬盘上的文件或数据库)之间,其作用是降低应用程序直接读写永久性数据存储源的频率,从而提高应用
的运行性能。缓存中的数据是数据存储源中数据的拷贝。缓存的物理介质通常是内存
- Hibernate中提供了两个级别的缓存
> 第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存有Hibernate管理
> 第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围的缓存
- SessionFactory的缓存可以分为两类:
> 内置缓存:Hibernate自带的,不可卸载. 通常在Hibernate的初始化阶段,Hibernate会把映射元数据和预定义的SQL语句放到SessionFactory的缓存中,映射元数据是映射文件中数据
(.hbm.xml文件中的数据)的复制,该内置缓存是只读的.
> 外置缓存(二级缓存):一个可配置的缓存插件. 在默认的情况下,SessionFactory不会启用这个缓存插件,外置缓存中的数据是数据库数据的复制,外置缓存的物理介质可以是内存或硬盘
- 使用Hibernate的二级缓存
> 适合放入二级缓存中的数据:
>> 很少被修改
>> 不是很重要的数据,允许出现偶尔的并发问题
> 不适合放入二级缓存中的数据:
>> 经常被修改
>> 财务数据绝对不允许出现并发问题
>> 与其他应用程序共享的数据
> Hibernate二级缓存的架构

> 二级缓存的并发策略
>> 两个并发的事务同时访问持久层的缓存的相同数据时,也有可能出现各类并发问题
>> 二级缓存可以设定以下4中类型的并发访问策略,每种访问策略对应一种事务隔离级别
- 非严格读写(Nonstrict-read-write):不保证缓存与数据库中数据的一致性,提供Read Uncommited事务隔离级别,对于极少被修改,而且允许脏读的数据,可以采用这种策略
- 读写型(Read-write):提供Read Commited数据隔离级别. 对于经常读但很少被修改的数据,可以采用此隔离类型,因为它可以防止脏读
- 事务型(Transactional):仅在受管理环境下使用,它提供了Repeatable Read事务隔离级别. 对于经常读但是很少被修改的数据,可以采用这种隔离类型,因为它可以防止脏读和不可重复读
- 只读型(Read-only):提供Serializable数据隔离级别,对于从来不会被修改的数据,可以采用此隔离级别
> 管理Hibernate的二级缓存
>> Hibernate的二级缓存是进程或集群范围内的缓存
>> 二级缓存是可配置的插件,Hibernate允许选用以下类型的缓存插件:
- EHCache:可作为进程范围内的缓存,存放数据的物理介质可以使内存或硬盘,对Hibernate的查询缓存提供了支持
- OpenSymphony OSCache:可作为进程范围内的缓存,存放数据的物理介质可以使内存或硬盘,提供了丰富的缓存数据过期策略,对Hibernate的查询提供了支持
- SwarmCache:可作为集群范围内的缓存,但不支持Hibernate的查询缓存
- JBossCache:可作为集群范围内的缓存,支持Hibernate的查询缓存
>> 4中缓存插件支持的并发访问策略(x代表支持,空白代表不支持)

> 配置进程范围内的二级缓存
>> 步骤:
- 选择合适的缓存插件:EHCache(jar包和配置文件),并编译器配置文件
- 在Hibernate的配置文件中启用二级缓存并指定和EHCache对应的缓存适配器
- 选择需要使用的二级缓存的持久化类,设置它的二级缓存的并发访问策略:
* <class>元素的cache子元素表明Hibernate会缓存对象的简单属性,但不会缓存集合属性,若希望缓存集合属性中的元素,必须在<set>元素中加入<cache>子元素
* 在hibernate配置文件中通过<class-cache/>节点配置使用缓存
> ehcache.xml
>> <diskStore>:指定一个目录:当EHCache把数据写到硬盘上时,将把数据写到这个目录下
>> <defaultCache>:设置缓存的默认数据过期策略
>> <cache>设定具体的命名缓存的数据过期策略。每个命名缓存代表一个缓存区域
>> 缓存区域(region):一个具体名称的缓存快,可以给每一个缓存块设置不同的缓存策略。若没有设置任何的缓存区域,则所有被缓存的对象,都将使用默认的缓存策略。即:<defaultCache.../>
>> Hibernate在不同的缓存区域保存不同的类/集合。
* 对于类而言,区域的名称是类名。如:com.atguigu.domain.Customer
* 对于集合而言,区域的名称是类名加属性名。如:com.atguigu.domain.Customer.orders
>> cache元素的属性
* name:设置缓存的名字,它的取值为类的全限定名或类的集合的名字
* maxInMemory:设置基于内存的缓存中可存放的对象最大数目
* eternal:设置对象是否为永久的,true表示永不过期,此时将忽略timeToldleSeconds和timeToLiveSeconds属性;默认值是false
* timeToldleSeconds:设置对象空闲最长时间,以秒为单位,超过这个时间,对象过期。当对象过期时,EHCache会把它从缓存中清除。如果此值为0,表示对象可以无限期地处于空闲状态
* timeToLiveSeconds:设置对象生存最长时间,超过这个时间,对象过期。如果此值为0,表示对象可以无期限地存在与缓存中,该属性值必须大于或等于timeToldleSeconds属性值
* overflowToDisk:设置基于内存的缓存中的对象数量达到上限后,是否把溢出的对象写到基于硬盘的缓存中
- 查询缓存
> 对于经常使用的查询语句,若启用了查询缓存,当第一次执行查询语句时,Hibernate会把查询结果存放在查询缓存中. 以后再次执行该查询语句时,只需从缓存中获取查询结果,从而提高查询性能
> 查询缓存使用于如下场合:
>> 应用程序运行时经常使用查询语句
>> 很少对与查询语句检索到的数据进行插入,删除和更新操作
> 启用查询缓存的步骤
>> 配置二级缓存,因为查询缓存依赖于二级缓存
>> 在hibernate配置文件中启用查询缓存
>> 对于希望启用查询缓存的语句,调用Query的setCacheable()方法
- Query接口的iterate()方法
> Query接口的iterator()方法
>> 同list()一样也能执行查询操作
>> list()方法执行的SQL语句包含实体类对应的数据表的所有字段
>> Iterator()方法执行的SQL语句中仅包含实体类对应的数据表的ID字段
>> 当遍历访问结果集时,该方法先到Session缓存及二级缓存中查看是否存在特定OID的对象,如果存在,就直接返回该对象,如果不存在该对象就通过相应的SQL Select语句到数据库中加载特定的实体对象
> 大多数情况下,应考虑使用list()方法执行查询操作. iterator()方法在满足以下条件的场合,可以稍微提高查询性能:
>> 要查询的数据表中包含大量字段
>> 启用了二级缓存,且二级缓存中可能已经包含了待查询的对象
* 管理Session&批量处理数据
- Hibernate自身提供了三种管理Session对象的方法
> Session对象的生命周期与本地线程绑定
> Session对象的生命周期与JTA事务绑定
> HIbernate委托程序管理Session对象的生命周期
- 在Hibernate的配置文件中,hibernate.current_session_context_class属性用与指定Session管理方式,可选值包括:
> thread:Session对象的生命周期与本地线程绑定
> jta*:Session对象的生命周期与JTA事务绑定
> managed:Hibernate委托程序来管理Session对象的生命周期
- Session对象的生命周期与本地线程绑定
> 如果把Hibernate配置文件的hibernate.current_session_context_class属性值设为thread,Hibernate就会按照与本地线程绑定的方式来管理Session
> Hiebrnate按一下规则把Session与本地线程绑定
>> 当一个线程(threadA)第一次调用SessionFactory对象的getCurrentSeesion()方法时,该方法会创建一个新的Session(sessionA)对象,把该对象与threaA绑定,并将sessionA返回
>> 当threadA再次调用SessionFactory对象的getCurrentSession()方法时,该方法将返回sessionA对象
>> 当threadA提交sessionA对象关联的事务时,Hibernate会自动flush sessionA对象的缓存,然后提交事务,关闭sessionA对象,当threadA撤销sessionA对向关联的事务时,也会自动关闭sessionA对象
>> 若threadA再次调用SessionFactory对象的getCurrentSession()方法时,该方法会又创建一个新的Session(sessionB)对象,把该对象与threadA绑定,并将sessionB返回
- 批量处理数据
> 批量处理数据是指在一个事务中处理大量数据.
> 在应用层进行批量操作,主要有以下方式:
>> 通过Session
>> 通过HQL
>> 通过StatelessSession
>> 通过JDBC API
> 通过Session来进行批量操作
>> Session的save()及update()方法都会把处理的对象存放在自己的缓存中. 如果通过一个Session对象来处理大量持久化对象,应该及时从缓存中清空已经处理完毕并且不会再访问的对象.
具体的做法是在处理完一个对象或小批量对象后,立即调用flush()方法刷新缓存,然后调用clear()方法清空缓存
>> 通过Session来进行处理操作会受到以下约束:
* 需要在Hibernate配置文件中设置JDBC单次批量处理的数目,应保证每次向数据库发送的批量的SQL语句数目与batch_size属性一致
* 若对象采用“identity”标识符生成器,则Hibernate无法在JDBC层进行批量插入操作
* 进行批量操作时,建议关闭Hibernate的二级缓存
>> 批量更新:在进行批量更新时,若一下子把所有对象都加载到Session缓存,然后在缓存中一一更新,显然是不可取的
>> 使用可滚动结果集org.hibernate.ScrollableResults,该对象中实际上并不包含任何对象,只包含用于在线定位记录的游标. 只有当程序遍历访问ScrollableResult对象的特定元素时,它才会到数据库中加载相应的对象
>> org.hibernateScrollableResults对象由Query的scroll方法返回
> 通过HQL来进行批量操作
>> 注:HQL只支持INSERT INTO...SELECT形式的插入语句,但不支持INSERT INTO...VALUES形式的插入语句,所以使用HQL不能进行批量插入操作
> 通过StatelessSession来进行批量操作
>> 从形式上看,StatelessSession与session的用法类似。StatelessSession与session相比,有以下区别:
* StatelessSession没有缓冲,通过StatelessSession来加载、保存或更新后的对象处于游离状态
* StatelessSession不会与Hibernate的第二级缓存交互
* 当调用StatelessSession的save()、update()或delete()方法时,这些方法会立即执行相应的SQL语句,而不会仅计划执行一条SQL语句
* StatelessSession不会进行脏检查,因此修改了Customer对象属性后,还需要调用StatelessSession的update()方法来更新数据库中的数据
* StatelessSession不会对关联的对象进行任何级联操作
* 通过同一个StatelessSession对象两次加载OID为1的Customer对象,得到的两个对象内存地址不同
* StatelessSession所做的操作可以被Interceptor拦截器捕获到,但是会被Hibernate的事件处理系统忽略掉
JavaEE高级-Hibernate学习笔记的更多相关文章
- JavaEE高级-SpringMVC学习笔记
*SpringMVC概述 - Spring为展示层提供的基于MVC设计理念的优秀Web框架,是目前最主流的MVC框架之一 - Spring3.0后全面超越Struts2,成为最优秀的MVC框架 - S ...
- JavaEE高级-MyBatis学习笔记
一.MyBatis简介 - MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架. - MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集. - My ...
- JavaEE高级-Spring学习笔记
*Spring是什么? - Spring是一个开源框架 - Spring为简化企业级应用开发而生.使用Spring可以使简单的JavaBean实现以前只有EJB才能实现的功能 - Spring是一个I ...
- JavaEE高级-JPA学习笔记
*JPA概述 *JPA是什么? - Java Persistence API :用于对象持久化的API - Java EE 5.0平台标准的ORM规范,使得应用程序以统一的方式访问持久化层 - JPA ...
- JavaEE高级-MyBatisPlus学习笔记
第 1 章 简介 1.1 MyBatisPlus 介绍 -MyBatis-Plus(简称 MP),是一个 MyBatis 的增强工具包,只做增强不做改变. 为简化开发工作.提高生产率而生我们的愿景是成 ...
- JavaEE高级-Struts2学习笔记
Struts2是一个用来来发MVC应用的框架,它提供了Web应用程序开发过程中一些常见问题的解决方案: - 对来自用户的输入数据进行合法的验证 - 统一的布局 - 可扩展性. - 国际化和本地化 - ...
- JavaEE高级-Maven学习笔记
Maven简介 1.Maven是一款服务于Java平台的自动化构建工具. 2.构建: - 概念:以“Java源文件”.“框架配置文件”.“JSP”.“HTML”.“图片”等资源为“原料”,去“生产”一 ...
- Hibernate学习笔记(二)
2016/4/22 23:19:44 Hibernate学习笔记(二) 1.1 Hibernate的持久化类状态 1.1.1 Hibernate的持久化类状态 持久化:就是一个实体类与数据库表建立了映 ...
- Hibernate学习笔记(一)
2016/4/18 19:58:58 Hibernate学习笔记(一) 1.Hibernate框架的概述: 就是一个持久层的ORM框架. ORM:对象关系映射.将Java中实体对象与关系型数据库中表建 ...
随机推荐
- Python_020(几个经典内置方法)
一.内置方法 1.内置方法表示:__名字__ 几种名称: 1)双下方法 2)魔术方法 3)类中的特殊方法/内置方法 类中的每一个双下方法都有它自己的特殊意义;所有的双下方法没有 需要你在外部直接调用的 ...
- RabbitMQ 工作图解
(转网上的图) (原文地址 ,http://www.cnblogs.com/knowledgesea/p/5296008.html)
- android读取xml
/*** 从config.xml中获取版本信息以及应用id* * @param urlPath* @return* @throws Exception*/public List getUpdateIn ...
- [CF1093E]Intersection of Permutations:树套树+pbds
分析 裸的二维数点,博主用树状数组套平衡树写的,顺便pbds真好用. Update on 2018/12/20:再解释一下为什么是二维数点,第一维是\(la \leq i \leq ra\),第二维是 ...
- POJ 1385 Lifting the Stone (多边形的重心)
Lifting the Stone 题目链接: http://acm.hust.edu.cn/vjudge/contest/130510#problem/G Description There are ...
- 嵌入式Linux之虚拟内存地址空间布局(Virtual Memory Space)
虚拟内存地址空间 Linux内核属于微内核的范畴,内核控制计算机的硬件资源,运行在特权模式:用户态应用程序运行在普通用户模式,无法直接访问硬件资源,必须依托于内核提供的资源,如CPU资源.Memory ...
- ASM磁盘组删除磁盘
ASM磁盘组删除磁盘 [oracle@dbserver1 ~]$ su - gridsqlplus / as sysasmConnected.SQL> alter diskgroup data ...
- xpath 算法
w https://www.w3.org/TR/xpath20/ Before an expression can be processed, its input data must be repre ...
- 阶段1 语言基础+高级_1-3-Java语言高级_04-集合_08 Map集合_2_Map常用子类
常用的实现类HashMap 它的子类.LinkedHaspMap
- @SuppressWarnings https://www.cnblogs.com/fsjohnhuang/p/4040785.html
一.前言 编码时我们总会发现如下变量未被使用的警告提示: 上述代码编译通过且可以运行,但每行前面的“感叹号”就严重阻碍了我们判断该行是否设置的断点了.这时我们可以在方法前添加 @SuppressWar ...