五年双十一:SLS数据管道发展之路
日志服务SLS是一款飞天团队自研产品,服务云上云下3W+客户,并在阿里经济体中作为日志数据的基础设施,在过去几年中经历多次双十一、双十二、新春红包锤炼。
在2019双十一中:
- 服务阿里经济体3W+ 应用,1.5W外部独立客户
- 峰值30TB/min、单集群峰值11TB/min
- 单日志峰值600GB/min
- 单业务线峰值1.2TB/min
- 支持核心电商、妈妈、蚂蚁、菜鸟、盒马、优酷、高德、大文娱、中间件、天猫精灵等团队日志的全量上云
- 与30+数据源、20+数据处理、计算系统无缝打通(如下)
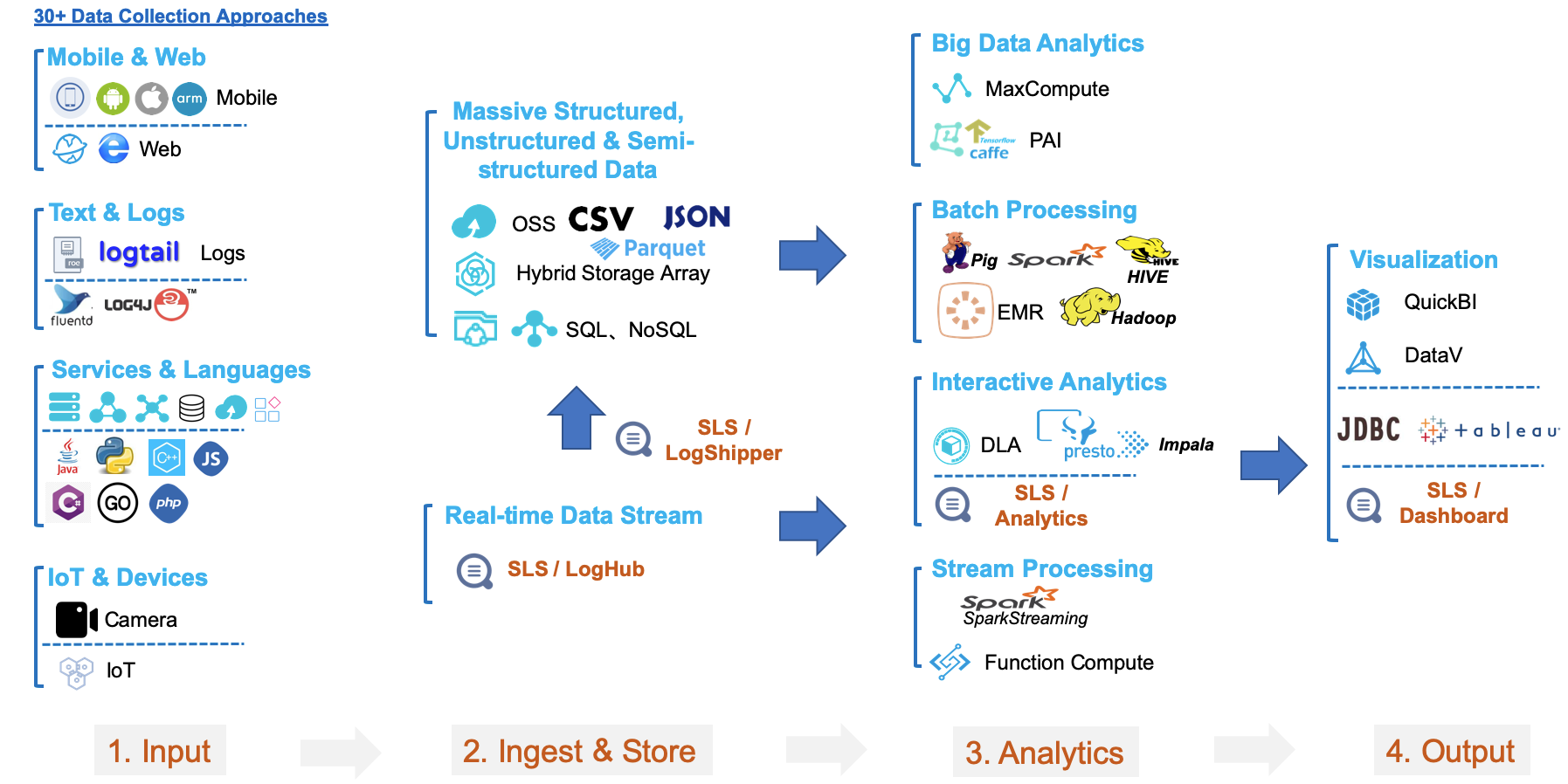
能够服务这个体量和用户规模,对产品的功能、体验、系统的稳定性和可靠性的要求是很高的。感谢阿里经济体独一无二的环境与挑战,使得我们过去五年中持续不断地对产品与技术进行考验与磨炼。
数据管道是企业的基础设施
数据管道是什么?
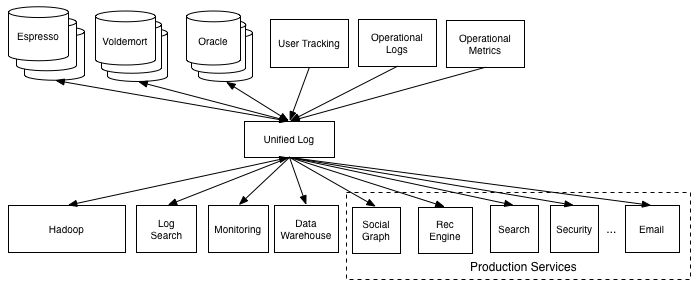
数据管道概念诞生在2009年,提出的是LinkedIn工程师Jay Krep,Jay也是Apache Kafka作者+Confluent公司CEO。2012年他在文章《The Log: What every software engineer should know about real-time data's unifying abstraction》中提到设计管道设施的两个初衷:
- 解耦生产者与消费者,降低系统对接复杂性
- 定义出统一格式与操作语义
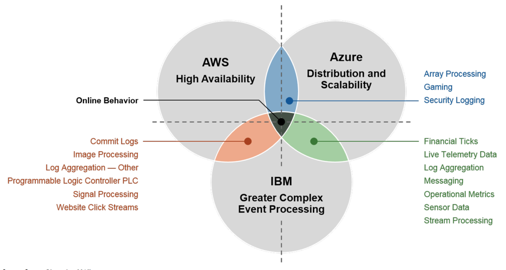
这两个核心痛点的解决+实时系统的兴起使得Kafka类产品在几年间有了一个量的飞跃,成了脍炙人口的基础软件。随着数据分析系统成为企业标配,各大厂商也逐步将数据管道产品化成服务互联网的服务,比较有代表性的有:
- AWS:Kinesis
- Azure:EventHub
- IBM:BlueMix Event Pipeline
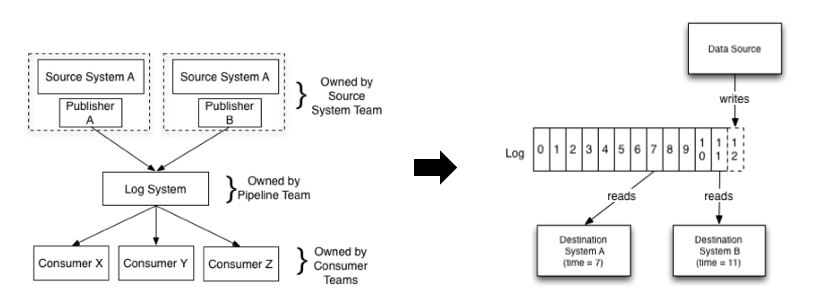
数据管道(Data Pipeline)是实现系统之间数据迁移的载体,因此包括数据的采集、传输链路、存储队列、消费/转储等都属于数据管道的范畴。在SLS这里,我们专为数据管道相关的功能集合起了一个单独的名称:LogHub,LogHub提供数30+种数据接入方式、提供实时数据管道、对接各类下游系统等功能。
然而数据管道因足够底层,在企业数字化过程中担任重要的业务,必须足够可靠、足够稳定、确保数据的通畅,并且能够弹性满足流量变化需求。我们把过去5年来我们遇到的挑战展开,和大家回顾下。
数据管道的挑战
管道这个概念非常简单,以至于每个开发者都能用20行代码写一个原型出来:
- Immutable队列,只支持写入,不支持更改
- 消费者写入后返回,写入时保序
- 消费者可以根据点位来消费数据
- 数据无法更改,只能根据TTL(写入先后顺序)进行删除
但在现实过程中,维护一个每天读写百亿次,几十PB数据流量,并且被万级用户依赖的管道是一件很有挑战的事情,举几个例子:
- 生产者:某个消费者程序写错了,突然引起一大波流量把管道入口都占满了。某些数据源因促销活动,流量在一个小时内上涨至原先十几倍或几百倍
- 消费者:对一个数据源,同时有20+订阅者来同时消费数据
- 每天有几百个数据源接入,方式各不相同,需要大量适配
这样例子每天都在发生,如何把简单的管道做得不简单,需要大量的工作,在下面篇幅中我们娓娓道来。
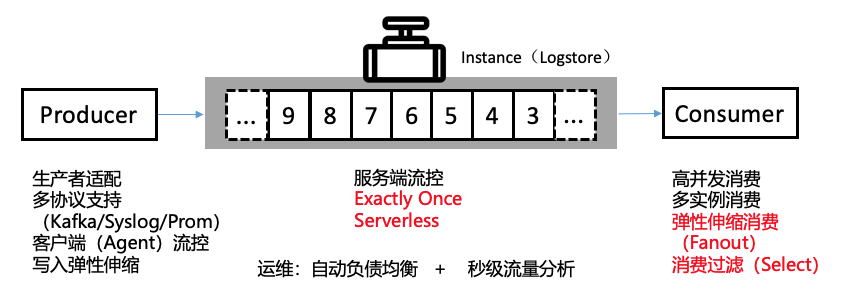
挑战1:生产者适配
SLS 第一版本支持一类数据源-- 飞天格式的日志文件,在五年中逐步扩展到各语言SDK,移动端,嵌入式芯片,物联网和云原生等环境:
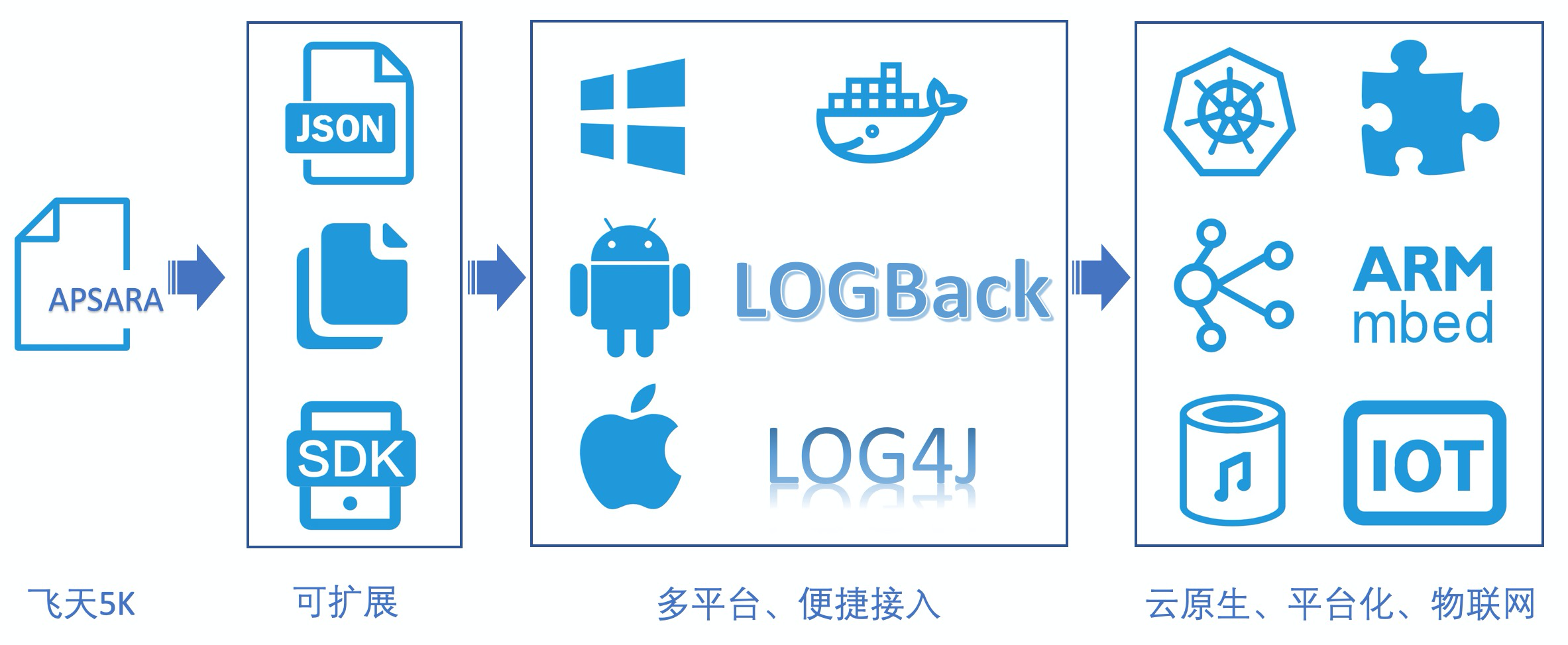
飞天日志
SLS起源与阿里云的飞天项目,当时我们飞天有一个基础的日志模块,几乎所有的系统都会使用这个模块打印日志,所以最开始我们开发了Logtail用于采集飞天日志,当时的Logtail还只是一个阿里云飞天系统内部使用的工具。
SDK可扩展
随着非阿里云团队使用,所以我们扩展了Logtail,支持通用的日志格式,比如正则、Json、分隔符等等。同时还有很多应用不希望落盘,因此我们提供了各种语言的SDK用于日志上传的代码集成。
多平台接入
随着移动互联网兴起,我们专门针对移动端开发了Android、IOS的SDK,便于用户快速接入日志;这个时间点阿里也开始了微服务改造、pouch开始上线,Logtail开始兼容pouch,同时我们还专门为Java微服务提供Log4J、LogBack的Appender,提供数据直传的服务。
对ARM平台、嵌入式系统、国产化系统也定制适配客户端进行接入。
Logtail平台化
在2018年初,为了应对多样化的需求,我们为Logtail增加了插件功能,有自定义需求的用户可以通过开发插件的方式扩展Logtail,实现各种丰富的功能;同时我们也紧跟时代步伐,支持云原生、智能设备、IoT等新兴领域的数据采集
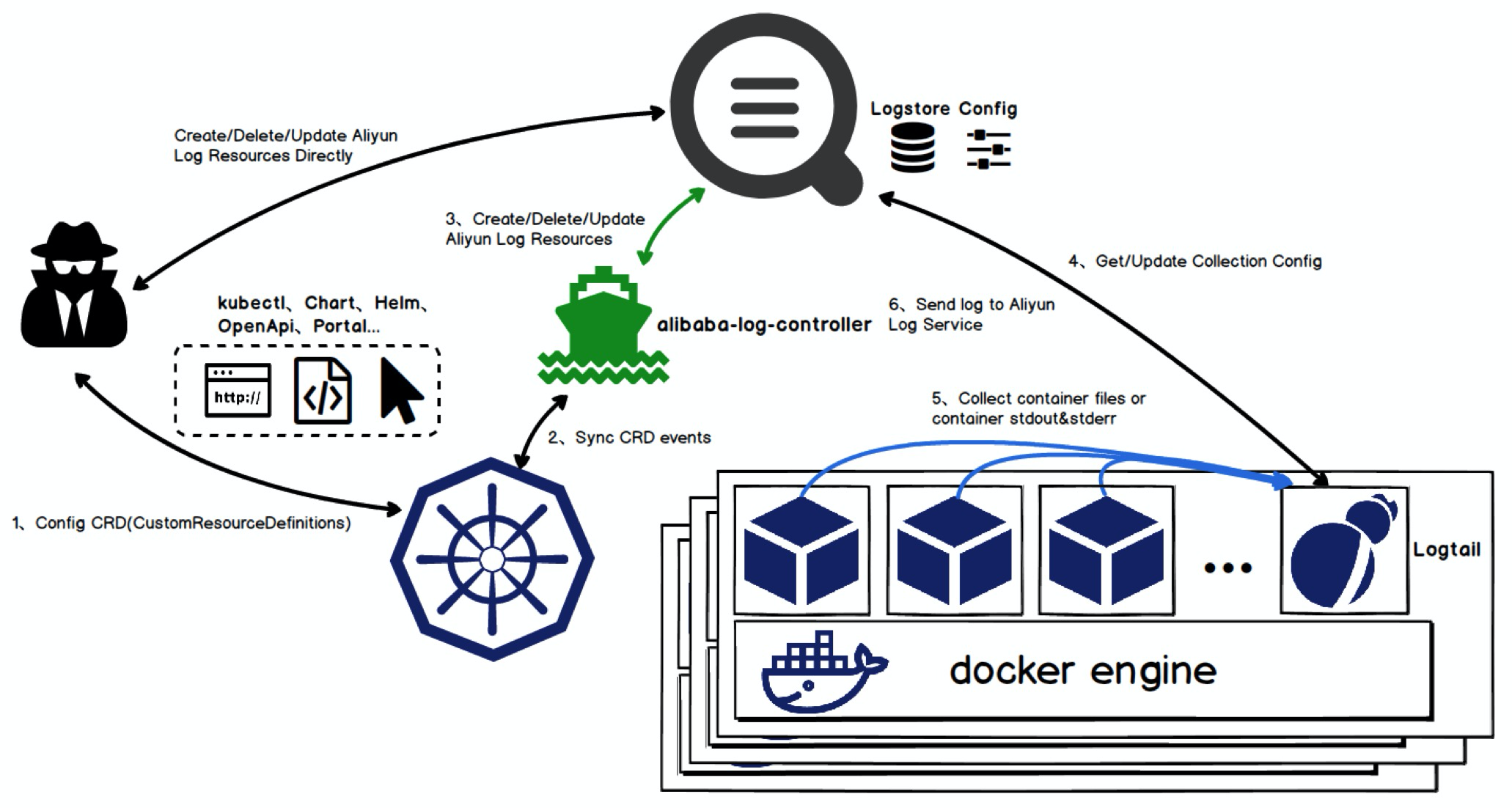
云原生支持
随着云原生落地,Logtail的数据采集在18年初就开始全面支持Kubernetes,并提供了CRD(CustomResourceDefinition)用于日志和Kubernetes系统的集成,目前这套方案已经应用在了集团内、公有云几千个集群中。
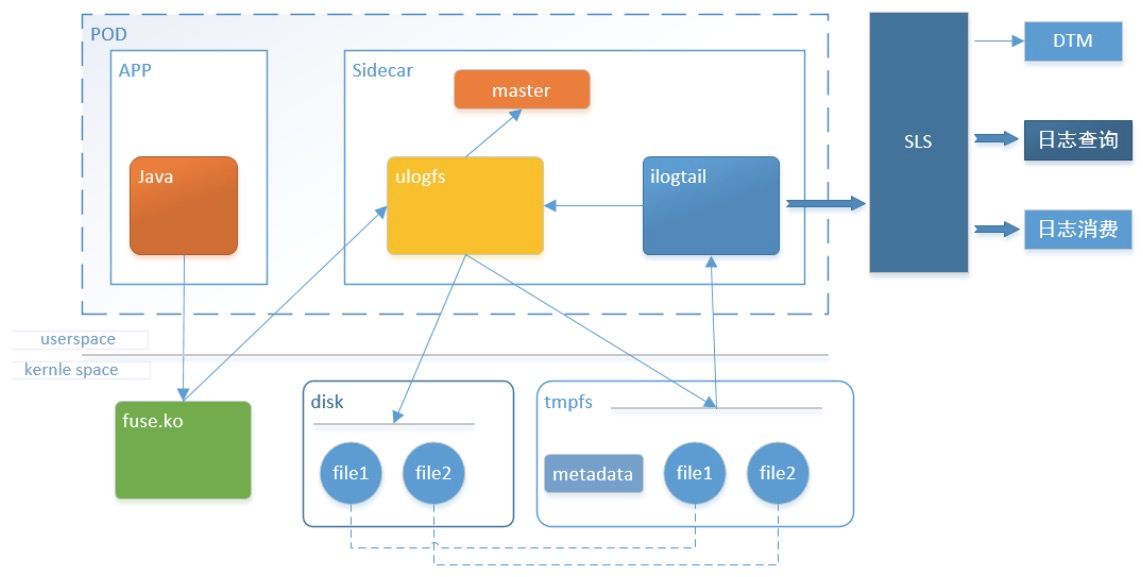
云原生后的无盘化
在阿里高度虚拟化的场景中,一台物理机可能运行上百个容器,传统的日志落盘采集方式对物理机磁盘的竞争很大,会影响日志写入性能,间接影响应用的RT;同时每天物理机需要为各个容器准备日志的磁盘空间,造成巨大的资源冗余。
因此我们和蚂蚁系统部合作开展了日志无盘化项目,基于用户态文件系统,为应用虚拟出一个日志盘,而日志盘的背后直接通过用户态文件系统对接Logtail并直传到SLS,以最快的方式实现日志可看、可查。
挑战2:多协议支持
SLS服务端支持HTTP协议写入,也提供了众多SDK和Agent,但在很多场景下还是和数据源间有巨大鸿沟,例如:
- 客户基于开源自建系统,不接受二次改造,希望只修改一下配置文件就能接入;
- 很多设备(交换机、路由器)提供的固定协议,无法使用HTTP协议;
- 各种软件的监控信息、二进制格式等,而这些开源Agent可以支持。
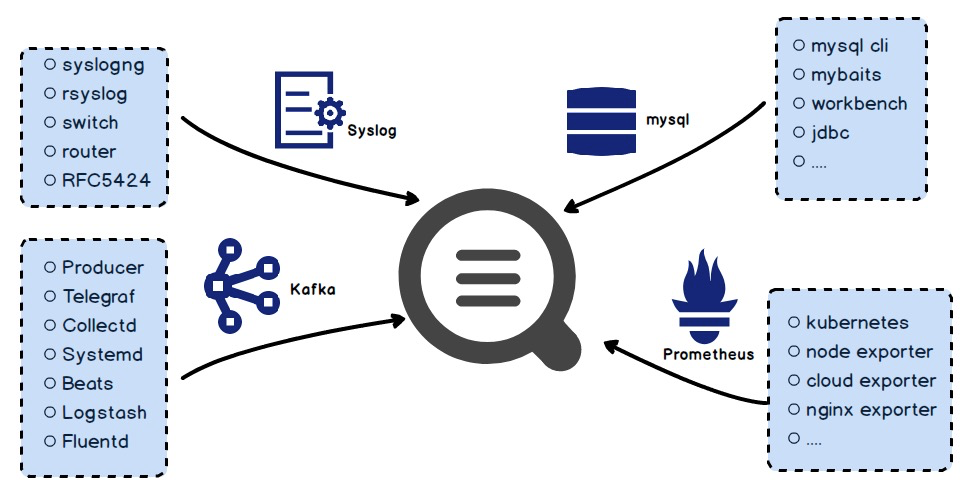
为此SLS开展了通用协议适配计划,除HTTP外还兼容Syslog,Kafka、Promethous和JDBC四种协议来兼容开源生态。用户现有系统只需要修改写入源即可实现快速接入;已有的路由器、交换机等可以直接配置写入,无需代理转发;支持众多开源采集组件,例如Logstash、Fluentd、Telegraf等。
挑战3:客户端(Agent)流控
在2017年前后,我们遇到了另外一个挑战:单机Agent的多租户流控,举一个例子:
- 某主机上有20+种日志,其中有需要对账的操作日志,也有级别为Info的程序输出日志
- 因日志生产者的不可控,在一段时间内可能会大量产生程序输出日志
- 该数据源会在短时间将采集Agent打爆,引起关键数据无法采集、或延迟采集
我们对Agent(Logtail)进行了一系列多租户隔离优化:
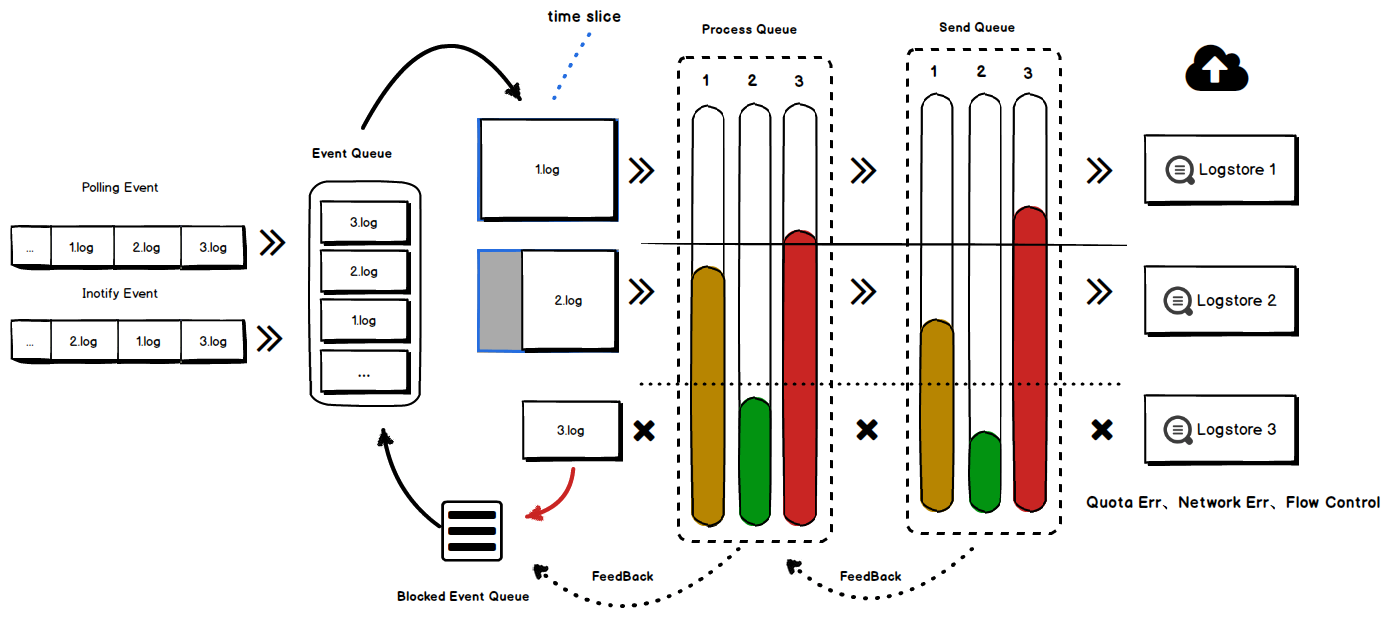
- 通过时间片采集调度保证各个配置数据入口的隔离性和公平性
- 设计多级高低水位反馈队列保证在极低的资源占用下依然可以保证各处理流程间以及多个配置间的隔离性和公平性,
- 采用事件处理不阻塞的机制保证即使在配置阻塞/停采期间发生文件轮转依然具有较高的可靠性
- 通过各个配置不同的流控/停采策略以及配置动态更新保证数据采集具备较高的可控性
该功能上线后,经过不断调优,较好解决了单机上多个数据源(租户)公平分配的问题。
挑战4:服务端流控
除了客户端流控外,我们在服务端也支持两种不同的流控方式(Project级、Shard级反压),防止单实例异常在接入层、或后端服务层影响其他租户。我们专门开发QuotaServer模块,提供了Project全局流控和Shard级流控两层流控机制,在百万级的规模下也能实现秒级的流控同步,保证租户之间的隔离性以及防止流量穿透导致集群不可用。
粗粒度流控:Project级
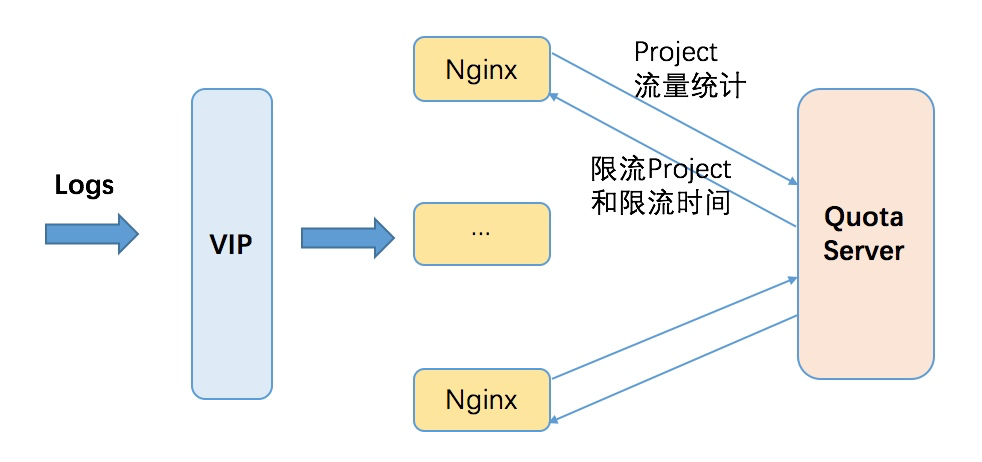
- 每秒上千个Nginx前端,将各种接收到的Project的流量、请求次数进行汇总,发送至QuotaServer(也是分布式架构,按照Project的进行分区)
- Quota Server汇总所有来自各Nginx的Project统计信息,计算出每个Project的流量、qps是否超过设置的quota上限,确定否需要禁用Project的各类操作,以及禁用时间
- 对于超过Quota的Project列表,QuotaServer能秒级通知到所有的Nginx前端
- Nginx前端获取禁用Project列表之后,立刻做出反应,拒绝这些Project的请求
Project全局流控最主要的目的是限制用户整体资源用量,在前端就拒绝掉请求,防止用户实例的流量穿透后端把整个集群打爆。真正做到流控更加精细、语义更加明确、可控性更强的是Shard级别流控。
细粒度流控:Shard级
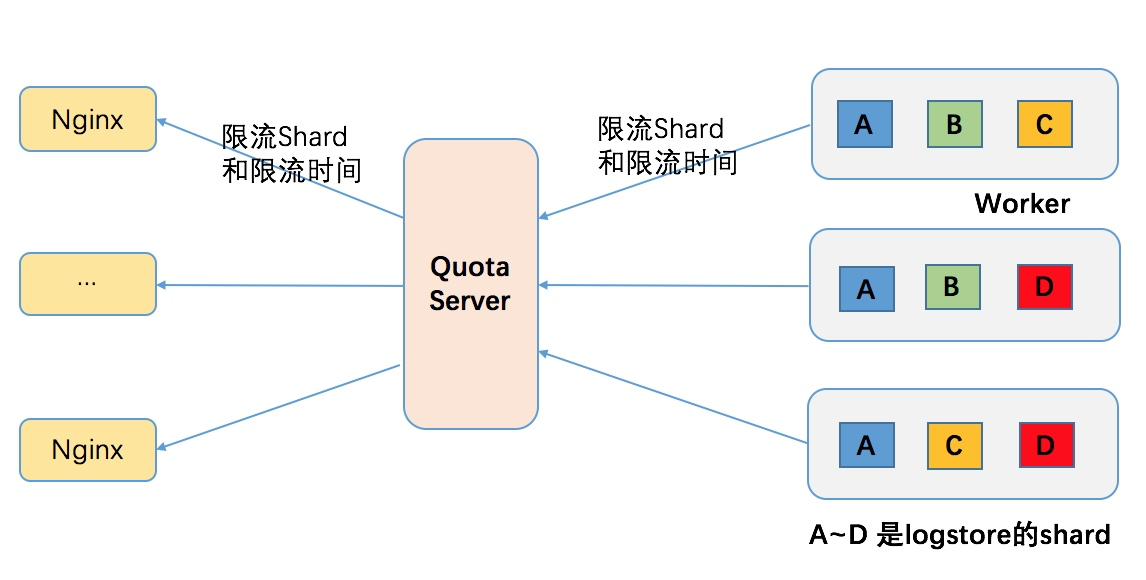
- 每个shard明确定义处理能力, 如5MB/sec写入,10MB/sec的读取
- 在shard所在的机器资源有空闲的时候,尽量处理(也有资源消耗上限限制)
- 当shard队列出现堵塞,根据shard流量是否超过quota,返回用户是限流还是系统错误(返回的Http错误码是403还是500),同时将Shard限流信息通知QuotaServer
- QuotaServer接收到限流信息后,通过Nginx和QuotaServer之间存在Long pull通道,可瞬时将限流信息同步至所有的Nginx
- Nginx端获得Shard的流控信息之后,对shard进行精确的流控
通过shard级别流控,好处非常明显:
- 每个shard接收的流量有上限,异常流量在前端Nginx直接被拒绝,在各种情况下,都无法穿透至后端
- Project的流控不作为主要流控手段,只作为用户保护手段,防止代码异常等情况而导致的流量剧增
- 根据错误码(http code是403还是500),用户可以和明确知道是被限流了,还是后端日志服务出现问题
- 出现403流控错误后,用户可以直接通过分裂shard方式,来获取更高的吞吐,用户获得更多自主处理权(花钱买资源)
挑战5:消费端(高并发)
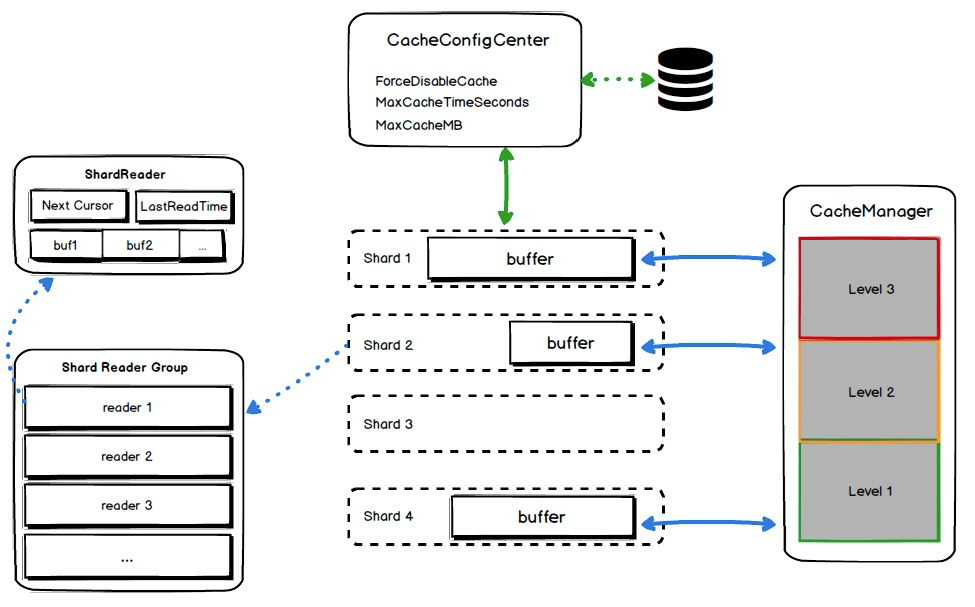
解决日志消费问题还是需要从应用场景出发,SLS作为实时管道,绝大部分消费场景都是实时消费,SLS针对消费场景提供了一层Cache,但Cache策略单一,随着消费客户端增多、数据量膨胀等问题而导致命中率越来越低,消费延迟越来越高。后来我们重新设计了缓存模块:
- 全局缓存管理,对于每一个Shard的消费计算消费权值,优先为权值高的Shard提供缓存空间;
- 更加精细化、启发式的缓存管理,根据用户近期时间的消费情况来动态调整缓存大小;
- 对于高保用户,强制分配定量的缓存空间,确保不受其他用户影响。
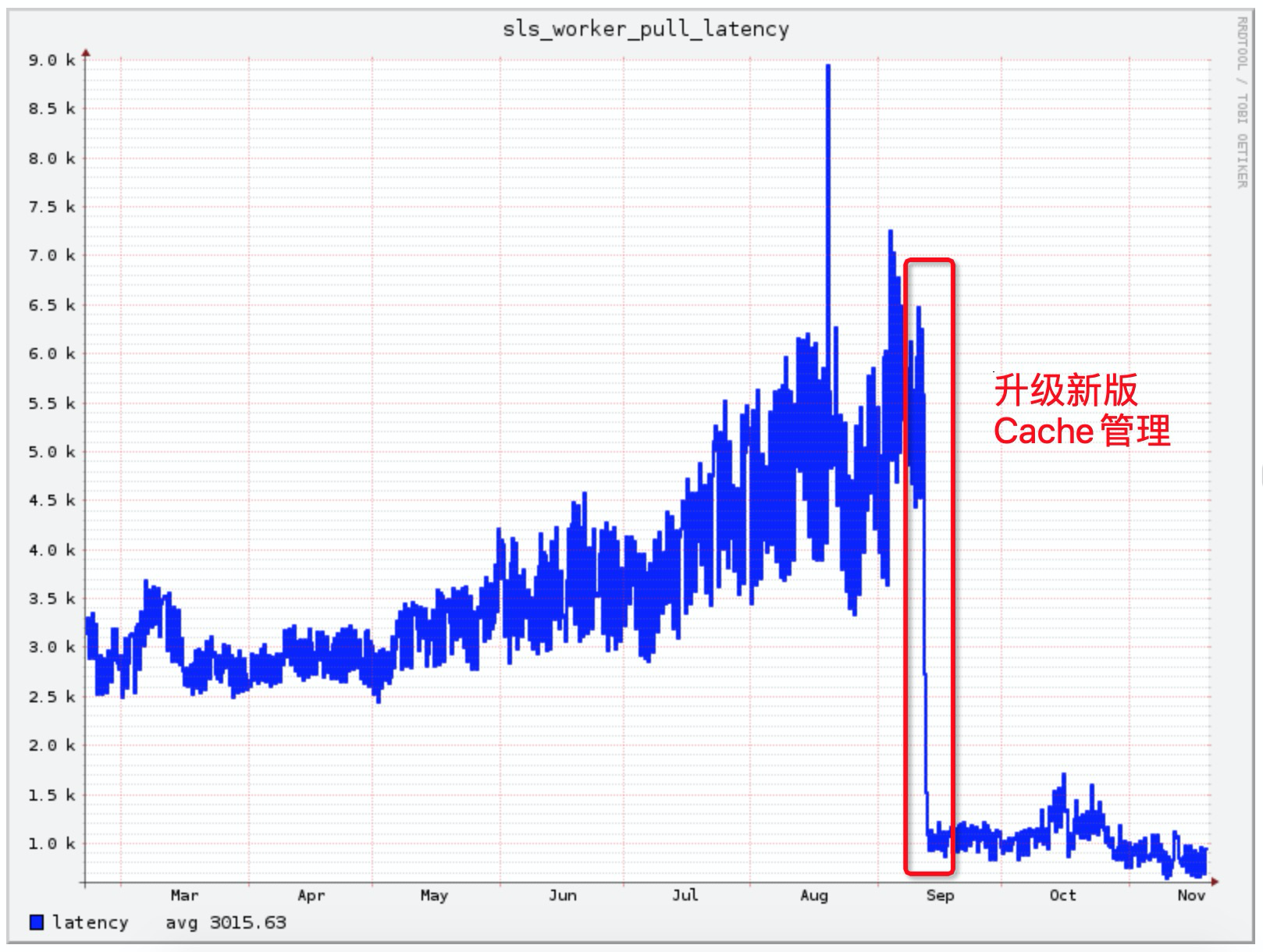
上述优化上线后,集群日志平均消费延迟从5ms降低到了1ms以内,有效缓解双十一数据消费压力。
挑战6:消费端(多实例与并发)
在以微服务、云原生为主导的大背景下,应用被切分的越来越细、整个链路也越来越复杂,其中产生的日志种类和数量也越来越多;同时日志的重要性也越来越强,同一个日志可能会有好几个甚至数十个业务方需要消费。
传统的方式粗暴简单,需要日志的人自己去机器上采集,最终一份日志可能被重复采集几十遍,严重浪费客户端、网络、服务端的资源。
SLS从源头上禁止同一文件的重复采集,日志统一采集到SLS后,我们为用户提供ConsumerGroup用于实时消费。但伴随着日志的细分化以及日志应用场景的丰富化,SLS的数据消费逐渐暴露出了两个问题:
- 日志细分场景下,ConsumerGroup无法支持同时消费多组Logstore的日志,其中的日志还可能跨越多个Project、隶属于多个不同账号,资源映射和权限归属管理越发复杂;
- ConsumerGroup分配的最小单位是Shard,SLS的一个Shard在不开启索引的情况下可以支撑几十MB/s的写入,而很多消费端单机并没有能力处理几十MB/s的数据,造成严重的生产、消费不对等。
View消费模式
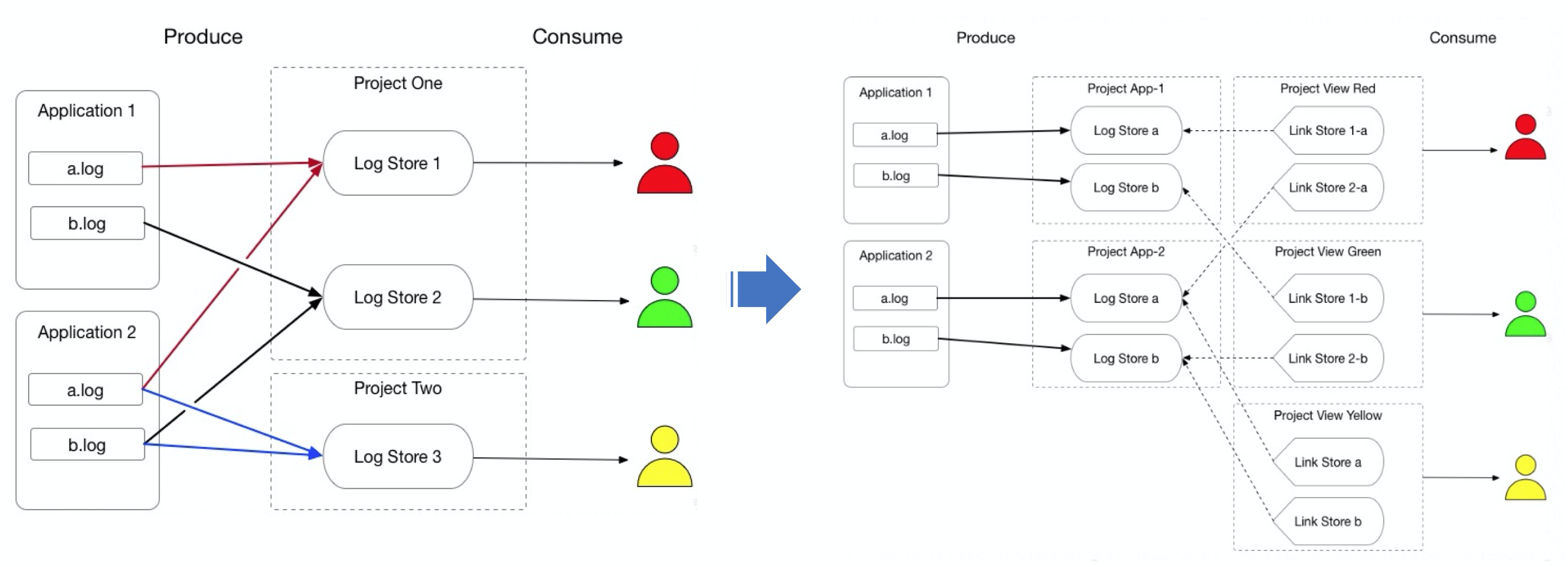
针对日志细分场景下的资源映射和权限归属管理等问题,我们和蚂蚁日志平台团队合作开发了View消费模式(思路来源于数据库中View),能够将不同用户、不同logstore的资源虚拟成一个大的logstore,用户只需要消费虚拟的logstore即可,虚拟logstore的实现以及维护对用户完全透明。该项目已经在蚂蚁集群正式上线,目前已经有数千个View消费实例在工作中。
Fanout消费模式
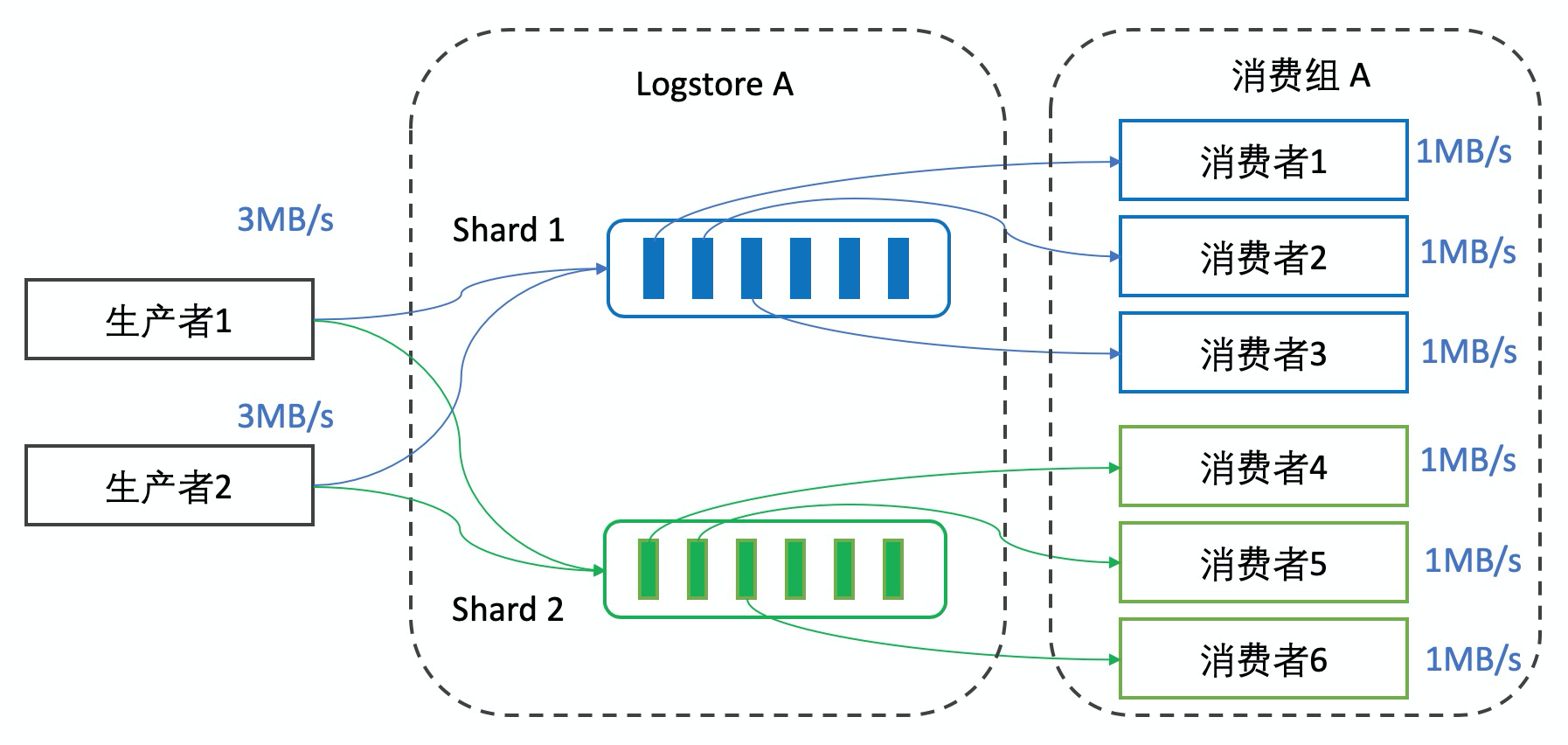
针对单消费者能力不足的问题,我们对ConsumerGroup进一步增强,开发了Fanout消费模式,在Fanout模式下,一个Shard中的数据可交由多个消费者处理,将Shard与消费者解耦,彻底解生产者消费者能力不匹配的问题。同时消费端无需关心Checkpoint管理、Failover等细节,Fanout消费组内部全部接管。
挑战7:自动化运维
SLS对外SLA承诺99.9%服务可用性(实际99.95%+),刚开始的时候我们很难达到这样的指标,每天收到很多告警,经常夜里被电话Call醒,疲于处理各种问题。总结下来主要的原因有2点:
- 热点问题:SLS会把Shard均匀调度到各个Worker节点,但每个Shard实际负载不一而且随着时间会动态变化,经常由于一些热点Shard存在同一台机器而导致请求变慢甚至超出服务能力;
- 出现问题定位时间太长:线上问题终究不可避免,为了实现99.9%的可靠性,我们必须能够在最短的时间内定位问题,及时止血。虽然有很多监控和日志,但人工去定位问题还是要花很多时间。
自动热点消除
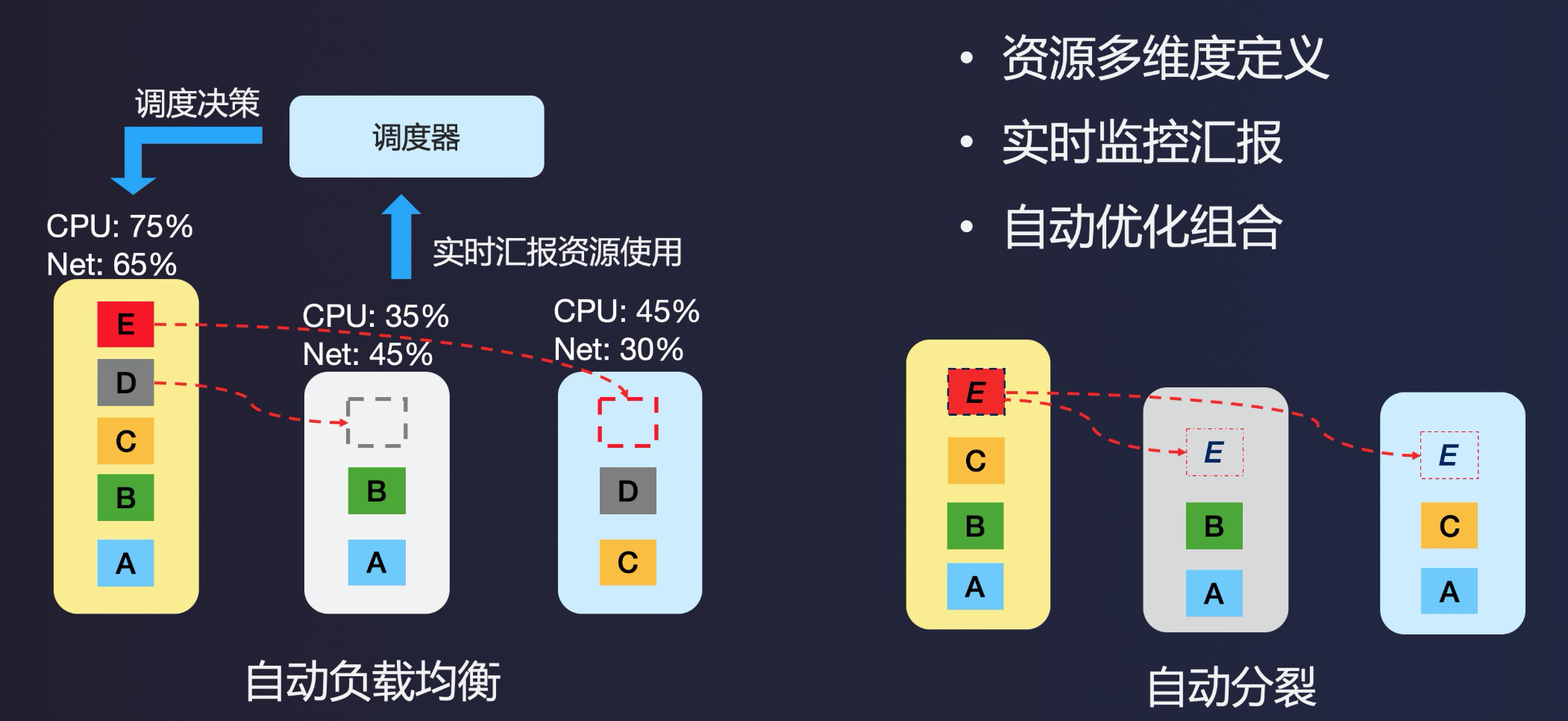
针对热点问题,我们在系统中增加了调度角色,通过实时数据收集和统计后,自动做出调整,来消除系统中存在的热点,主要有以下两个手段:
自动负载均衡
- 系统实时统计各节点的负载,以及节点上每个数据分区对于资源的消耗(CPU、MEM、NET等资源)
- 负载信息汇报至调度器,调度器自动发现当前是否有节点处于高负载情况
- 对于负载过高节点,通过优化组合的方式,将高压力数据分区,自动迁移到负载低的节点,达到资源负载均衡的目的
自动分裂
- 实时监控每个Shard负载压力
- 如果发现持续超过单分片处理上限,则启动分裂
- 旧的分区变成Readonly,生成2个新的分区,迁移至其他节点
实际场景下有很多情况需要特殊考虑,例如颠簸情况、异构机型、并发调度、迁移的负面影响等,这里就不再展开。
秒级流量分析(Root Cause Analysis)
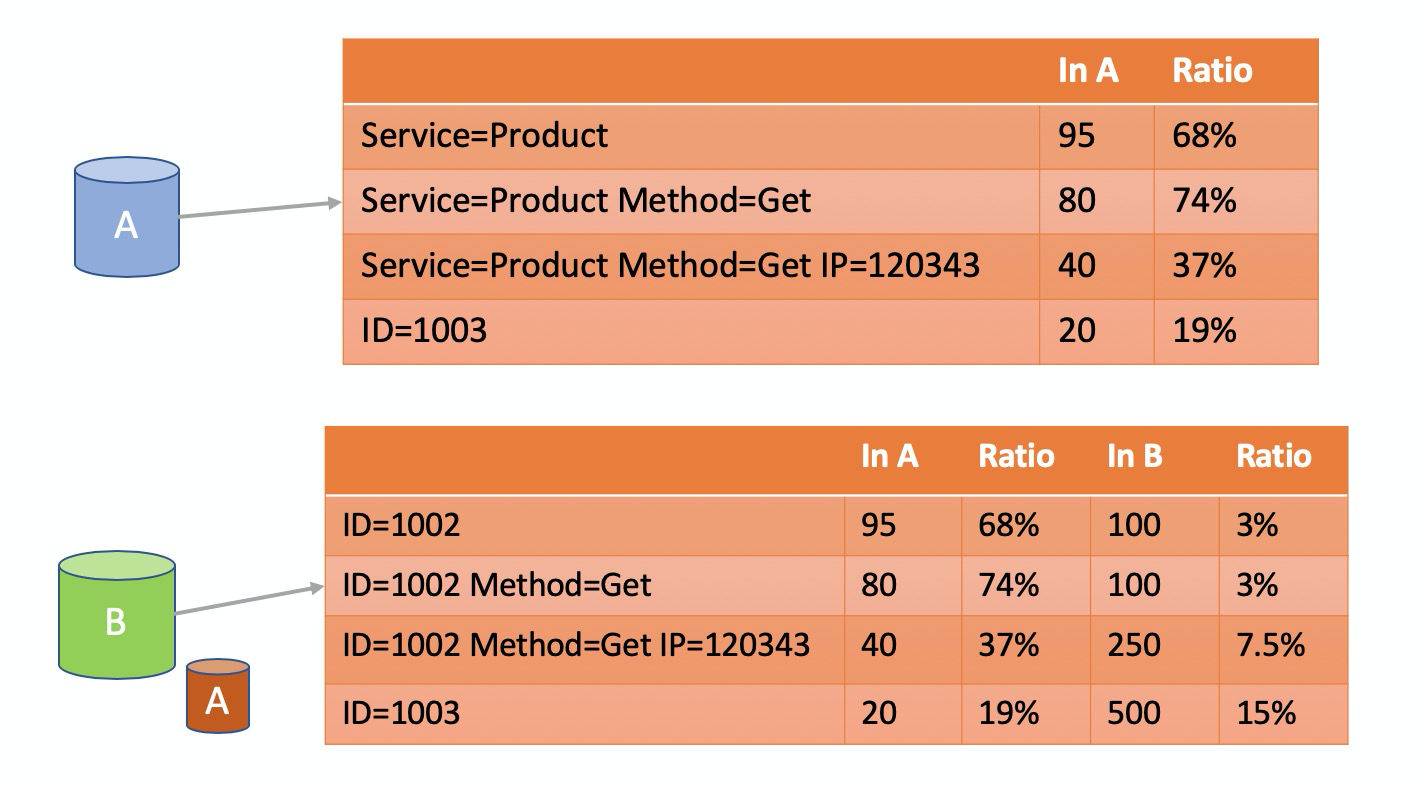
目前SLS线上收集了数千种实时指标,每天的访问日志有上千亿,出现问题时纯粹手工调查难度非常大。为此我们专门开发了根因分析相关算法,通过频繁集和差异集的方式,快速定位和异常最相关的数据集合。
如样例中,将出现错误(status >= 500)的访问数据集,定义为异常集合A,在这个集合发现90%的请求,都是由ID=1002引起,所以值得怀疑,当前的错误和ID=1002有关,同时为了减少误判,再从正常的数据集合B(status <500)中,查看ID=1002的比例,发现在集合B中的该ID比例较低,所以更加强系统判断,当前异常和这个ID=1002有非常高的相关性。
借助此种方法大大缩短了我们问题调查的时间,在报警时我们会自动带上根因分析结果,很多时候收到告警时就已经能够定位具体是哪个用户、哪台机器还是哪个模块引发的问题。
其他挑战:正在解决的问题
1. Shardless
为了便于水平扩展我们引入了Shard的概念(类似Kafka Partition),用户可以通过分裂Shard、合并Shard来实现资源的伸缩,但这些概念也会为用户带来很多使用上的困扰,用户需要去了解Shard的概念、需要去预估流量分配Shard数、有些时候因为Quota限制还需要手动分裂...
优秀的产品应该对用户暴露尽可能少的概念,未来我们会弱化甚至去除Shard概念,对于用户而言,SLS的数据管道只需要声明一定的Quota,我们就会按照对应的Quota服务,内部的分片逻辑对用户彻底透明,做到管道能力真正弹性。
2. 从At Least Once到Exactly Once
和Kafka一样,SLS目前支持At Least Once写入和消费方式,但很多核心场景(交易、结算、对账、核心事件等)必须要求Exactly Once,现在很多业务只能通过在上层包装一层去重逻辑来Work around,但实现代价以及资源消耗巨大。
马上我们会支持写入和消费的Exactly Once语义,且Exactly Once语义场景下也将支持超大流量和高并发。
3. LogHub Select功能(过滤下推)
和Kafka类似,SLS支持的消费是Logstore级别的全量消费方式,如果业务只需要其中的一部分数据,也必须将这段时间的所有数据全量消费才能得到。所有的数据都要从服务端传输到计算节点再进行处理,这种方式对于资源的浪费极其巨大。
因此未来我们会支持计算下推到队列内部,可以直接在队列内进行无效数据过滤,大大降低无效的网络传输和上层计算代价。
本文作者:元乙
本文为阿里云内容,未经允许不得转载。
五年双十一:SLS数据管道发展之路的更多相关文章
- “双十一”购物狂欢节,电商运营和商业智能(BI)才是绝配
百年前,人们获取信息的方式是通过报纸.书籍:十年前,人们获取信息的方式是通过传统PC互联网:而如今,在4G网络高速发展的浪潮下,伴随着移动智能终端的普及,人们获取信息的方式已经逐渐转向了移动 ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- C#采用的是“四舍六入五成双”、上取整、下取整
c# 四舍五入.上取整.下取整 Posted on 2010-07-28 12:54 碧水寒潭 阅读(57826) 评论(4) 编辑 收藏 在处理一些数据时,我们希望能用“四舍五入”法实现,但是C#采 ...
- ABBYY FineReader去他的光棍节,我要我的双十一
今天就是双十一,全民剁手的双十一,一年仅一次的双十一,不只是半价的双十一.....此时此刻,多少钱拿起手机在疯狂购物,又有多少人死守着电脑,不敢怠慢一丁点机会,买着买着购物车就空了,然后才发现,咦!超 ...
- Java NIO 学习笔记(五)----路径、文件和管道 Path/Files/Pipe
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- 备战双十一,腾讯WeTest有高招——小程序质量优化必读
WeTest 导读 2018年双十一战场小程序购物通道表现不俗,已逐渐成为各大品牌方角逐的新战场.数据显示,截止目前95%的电商平台都已经上线了小程序.除了电商企业外,许多传统线下商家也开始重视小程序 ...
- 贾扬清谈大数据&AI发展的新挑战和新机遇
摘要:2019云栖大会大数据&AI专场,阿里巴巴高级研究员贾扬清为我们带来<大数据AI发展的新机遇和新挑战>的分享.本文主要从人工智能的概念开始讲起,谈及了深度学习的发展和模型训练 ...
- 双十一HostGator独立服务器方案
一年一度的“双十一”购物狂欢节到来,各大电商平台线上消费的各种“吸金”开启了“双十一”模式,一年一度的“双十一”网购狂欢又开始以“巨大的价格优势”来勾起消费者的购买欲望. 此次双十一期间,HostGa ...
随机推荐
- windows环境下PostgreSQL的安装
1.首先在如下链接下载PostgreSQL的压缩包,我这里下载的是postgresql-12.1-1-windows-x64-binaries.zip. https://www.enterprised ...
- Oracle 查询库文件信息
--.查看Oracle数据库中数据文件信息的命令方法 select b.file_name 物理文件名, b.tablespace_name 表空间, b.bytes// 大小M, (b.bytes- ...
- 【Linux开发】Linux启动脚本设置
前言linux有自己一套完整的启动 体系,抓住了linux启动 的脉络,linux的启动 过程将不再神秘.阅读之前建议先看一下附图.本文中假设inittab中设置的init tree为:/etc/rc ...
- Mysql 5.7存储过程的学习
存储过程:对sql的封装和重用,经编译创建并保存在数据库中,通过指定存储过程的名字并给定参数(需要时)来调用执行. 优缺点: (1) 优点: 执行速度快------存储过程只在创建时进行编译,以后每次 ...
- 查看linux中所有用户的三种方式
通过使用/etc/passwd 文件,getent命令,compgen命令这三种方法查看系统中用户的信息. Linux 系统中用户信息存放在/etc/passwd文件中. 这是一个包含每个用户基本信息 ...
- TMS320F28335——下载程序到flash中
一.让CCS软件支持Flash烧写 添加F28335.cmd文件 如图屏蔽掉25335_RAM_lnk.cmd 2.支持从Flash中拷贝文件到RAM中 添加DSP2832x_MemCopy.c 在主 ...
- Jmeter学习总结
学习内容: 1.用户定义的变量 作用:多个地方使用同一个值,且该值在不同的环境下不同,方便脚本在不同环境下运行时修改. 2.基本的HTTP请求,请求方式:get 3.传入参数为json 4.HTTP信 ...
- 1-ES简单介绍
一.ES简单介绍 ES:Elastic Search,一个分布式.高扩展.高实时的搜索与数据分析引警.它可以准实时地快速存储.搜索.分析海量的数据. 1.ES实现原理 a.用户数据提交到ES数据库中 ...
- 【 React -- 2/100 】使用React实现评论功能
React| 组件化 | 递归 | 生成唯一ID 需要探究一下 .find() 和 findIndex() 的区别 import React from 'react' import './commen ...
- web.xml文件头声明各个版本参考
Servlet 3.1 Java EE 7 XML schema, namespace is http://xmlns.jcp.org/xml/ns/javaee/ <web-app xmlns ...