java中list和map详解
一、概叙
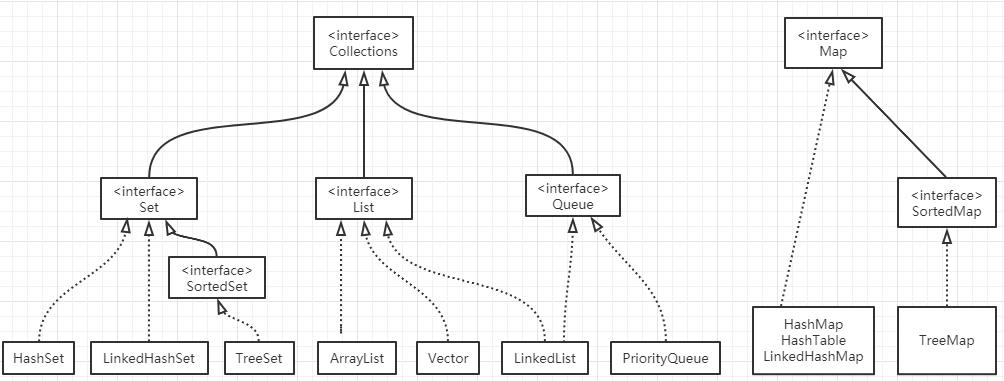
List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口,
List下有ArrayList,Vector,LinkedList
Set下有HashSet,LinkedHashSet,TreeSet
Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
Collection接口下还有个Queue接口,有PriorityQueue类
注意:Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList既可以实现Queue接口,也可以实现List接口.Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法)。
二、详解
(1)List 存储有序,可重复.
1、ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
ArrayList的实现原理
ArrayList继承AbstractList类,实现了List和RandomAccess,Cloneable, Serializable接口,底层是基于动态的数组。底层使用数组实现,默认初始容量为10.当超出后,会自动扩容为原来的1.5倍,即自动扩容机制。List list = Collections.synchronizedList(new ArrayList(...))即可线程安全。源码解析如下。
https://blog.csdn.net/u013309870/article/details/72519272
https://blog.csdn.net/u010250240/article/details/89762912
2、LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
LinkedList的实现原理
LinkedList继承AbstractList类,实现了List,Serializable,Queue接口,LinkedList是通过双向链表去实现的,既然是链表实现那么它的随机访问效率比ArrayList要低,顺序访问的效率要比较的高。每个节点都有一个前驱(之前前面节点的指针)和一个后继(指向后面节点的指针)。源码解析如下。
https://www.jianshu.com/p/ea5b7dd7dc01
3、Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
Vector实现原理:在ArrayList中每个方法中添加了synchronized关键字来保证同步。
(2)三种list的选择(元素可重复):要安全?
是:Vector
否:ArrayList或者LinkedList
查询多?:ArrayList
增删多?:LinkedList
知道要用List,但是不知道是哪个List,就用ArrayList。
ArrayList是基于动态的数组的数据结构 LinkedList是基于链表的数据结构
(3)Set存储无序,唯一
set保证里面元素的唯一性其实是靠两个方法,一是equals()和hashCode()方法先是判断set集合中是否有与新添加数据的hashcode值一致的数据,如果有,那么将再进行第二步调用equals方法再进行一次判断,假如集合中没有与新添加数据hashcode值一致的数据,那么将不调用eqauls方法。
1、HashSet
底层数据结构是哈希表。(无序,唯一)
使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数,HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象,如果没有哈希值相同的对象就直接存入集合,如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
2、LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
由链表保证元素有序,由哈希表保证元素唯一
3、TreeSet
底层数据结构是红黑树。(唯一,有序)
利用自然排序和比较器排序
根据比较的返回值是否是0来决定来保证元素的唯一性。
(4)Set的选择(元素唯一):
排序?
是:TreeSet或LinkedHashSet
否:HashSet
知道要用Set,但是不知道是哪个Set,就用HashSet。
(5)Map接口
Map接口有三个比较重要的实现类,分别是HashMap、HashTable和TreeMap,LinkedHashMap。
TreeMap是有序的,HashMap和HashTable是无序的。
Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
Hashtable是线程安全的,HashMap不是线程安全的。
HashMap效率较高,Hashtable效率较低。查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
Hashtable不允许null值,HashMap允许null值(key和value都允许)
父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
1、LinkedHashMap怎么实现有序的?
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或访问顺序排序。
2、TreeMap怎么实现有序的?
TreeMap是按照Key的自然顺序或者实现的Comprator接口的比较函数的顺序进行排序,内部是通过红黑树来实现。所以要么key所属的类实现Comparable接口,或者自定义一个实现了Comparator接口的比较器,传给TreeMap用于key的比较。
三、HashMap和ConcurrentHashMap的解析
(1)JDK1.8中HashMap
1、JDK1.8中HashMap的实现原理(数组+链表红黑树):
用一个数组来存储元素,但是这个数组存储的不是基本数据类型。HashMap实现巧妙的地方就在这里,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry)
2、HashMap如何设定初始容量大小?
一般如果new HashMap() 不传值,默认大小是16,负载因子是0.75, 如果自己传入初始大小k,初始化大小为 大于k的 2的整数次方,例如如果传10,大小为16。负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容
3、HashMap的哈希函数如何设计(如何求hash值)?
hash函数是先拿到通过key 的hashcode,是32位的int值,然后让hashcode的高16位和低16位进行异或操作即key.hashCode()^(key.hashCode()>>>6)。这样操作可以尽可能降低hash碰撞,使hash表越分散越好,同时算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
4、为什么采用hashcode的高16位和低16位异或能降低hash碰撞?hash函数能不能直接用key的hashcode?
因为key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为-2147483648~2147483647,前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。如果HashMap数组的初始大小才16,用之前需要对数组的长度取模运算,得到的余数才能用来访问数组下标。
5、如何通过hash值定位元素的位置
并不是对hash表的长度取余而使用了位运算来得到位置下标,由key的哈希值对数组的长度位运算得到即h & (length-1)
6、为什么用位运算定位hash以及HashMap的扩容都是以2的次方来进行?
假设当前table的length是15,二进制表示为1111,那么length-1就是1110,此时有两个hash值为8和9的key需要计算索引值,计算过程如下:
8的二进制表示:1000
8&(length-1)= 1000 & = 1000,索引值即为8;
9的二进制表示:1001
9&(length-1)= 1001 & 1110 = 1000,索引值也为8;
这样一来就产生了相同的索引值,也就是说两个hash值为8和9的key会定位到数组中的同一个位置上形成链表,这就产生了碰撞,降低了查询的效率,HashMap的初始大小和扩容都是以2的次方来进行的,换句话说length-1换成二进制永远是全部为1,比如容量为16,则length-1为1111,大家知道位运算的'&'规则是两个1才得1,遇0得0,也就是说length-1中的某一位为1,则对应位置的计算结果才取决于h中的对应位置(h中对应位取0,对应位结果为0,h对应位取1,对应位结果为1。这样就有两个结果),但是如果length-1中某一位为0,则不论h中对应位的数字为几,对应位结果都是0,这样就让两个h取到同一个结果,这就是hash冲突了,恰恰length-1又是全部为1的数,所以结果自然就将hash冲突最小化了。
7、h%length与h&(length-1)得到的结果其实是一个值,但是为什么hashmap中要用后者呢?
1)length(2的整数次幂)的特殊性导致了length-1的特殊性(二进制全为1)
2)位运算快于十进制运算,hashmap扩容也是按位扩容,所以相比较就选择了后者
8、两个不同key经过key.hashCode()&(length-1)计算后得到相同的数组下标后,如何操作?
hashmap在插入元素的时候,会首先检查这个位置上有没有元素,如果已经有了元素,那么就把这个新插入的Entry的next指向本来这个位置上的元素的地址,然后再插入这个位置,这也就是为什么插入多个相同的key的value时,这个位置的value始终是最后插入的那个元素的值。
9、jdk1.8的HashMap的put方法:
1)判断数组是否为空,为空进行初始化;
2)不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
3)查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
4)存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
5)如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;
6)如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8, 大于的话链表转换为红黑树;
7)插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的2倍。
10、jdk1.8的HashMap的get方法:
1)首先将 key hash 之后取得所定位的桶。
2)如果桶为空则直接返回 null 。
3)否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
4)如果第一个不匹配,则判断它的下一个是红黑树还是链表。
5)红黑树就按照树的查找方式返回值。
6)不然就按照链表的方式遍历匹配返回值。
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
//推荐使用
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
} Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key)); }
HashMap的遍历
11、jdk1.8中HashMap的三点主要的优化:
1)数组+链表改成了数组+链表或红黑树;1.8使用红黑树:防止发生hash冲突,链表长度过长,将时间复杂度由O(n)降为O(logn);
2)链表的插入方式从头插法改成了尾插法,是插入时,若数组位置上已经有元素,1.7利用头插法,1.8遍历链表,将元素放置到链表的最后; 因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环
3)扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变;
4)在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
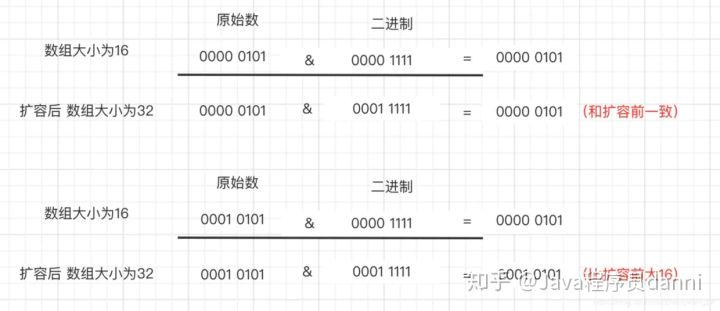
12、扩容的时候为什么1.8 不用重新hash就可以直接定位原节点在新数据的位置呢?
由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1,扩容前长度为16,用于计算(n-1) & hash 的二进制n-1为0000 1111,扩容为32后的二进制就高位多了1,为0001 1111。因为是& 运算,1和任何数 & 都是它本身,那就分二种情况:hash比(length-1)大和比(length-1)小。如下图所示:
13、链表转红黑树的阈值是8,为什么红黑树转链表的阈值是6?
在hash函数设计合理的情况下,发生hash碰撞8次的几率为百万分之6,概率说话。因为8够用了,至于为什么转回来是6,因为如果hash碰撞次数在8附近徘徊,会一直发生链表和红黑树的互相转化,为了预防这种情况的发生,设置为6。
14、Java中有HashTable、Collections.synchronizedMap、以及ConcurrentHashMap可以实现线程安全的Map。
1)HashTable是直接在操作方法上加synchronized关键字,锁住整个数组,锁粒度比较大,
2)Map m = Collections.synchronizedMap(new HashMap());
3)ConcurrentHashMap相比HashTable降低了锁粒度,并发度提高。jdk1.7使用分段锁实现ConcurrentHashMap线程安全,jdk1.8使用CAS实现ConcurrentHashMap线程安全。
(2)ConcurrentHashMap
1、ConcurrentHashMap在jdk1.7是如何实现的?
jdk1.7中是采用Segment 数组+ HashEntry +成员变量用volatile修饰+ ReentrantLock的方式进行实现的。其中其中segment继承自ReentrantLock,另外因为成员变量使用volatile 修饰,免除了指令重排序,同时保证内存可见性,不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理。理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组长度)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
注意:volatile关键字对于基本类型的修改可以在随后对多个线程的读保持一致,但是对于引用类型如数组仅仅保证引用的可见性,但并不保证引用内容的可见性。
2、ConcurrentHashMap在jdk1.8是如何实现的?
数据结构类似于hashmap,放弃了Segment臃肿的设计,取而代之的是采用Node数组+ CAS + Synchronized来保证并发安全进行实现。
jdk1.8 在jdk1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
3、jdk1.8的ConcurrentHashMap的put操作:
1)根据 key 计算出 hashcode ;
2)判断是否需要进行初始化。
3) 定位出当前 key的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
4)如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
5)如果都不满足,则利用 synchronized 锁写入数据。
6)如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
4、jdk1.8的ConcurrentHashMap 的get操作
1)根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
2)如果是红黑树那就按照树的方式获取值。
3)就不满足那就按照链表的方式遍历获取值。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。get 方法是非常高效的,因为整个过程都不需要加锁。
HashMap与ConcurrentHashMap详解:https://blog.csdn.net/weixin_44460333/article/details/86770169
HashMap常见问题:https://blog.csdn.net/wy757510722/article/details/65635734
java中list和map详解的更多相关文章
- java中的io系统详解 - ilibaba的专栏 - 博客频道 - CSDN.NET
java中的io系统详解 - ilibaba的专栏 - 博客频道 - CSDN.NET 亲,“社区之星”已经一周岁了! 社区福利快来领取免费参加MDCC大会机会哦 Tag功能介绍—我们 ...
- Java中的main()方法详解
在Java中,main()方法是Java应用程序的入口方法,也就是说,程序在运行的时候,第一个执行的方法就是main()方法,这个方法和其他的方法有很大的不同,比如方法的名字必须是main,方法必须是 ...
- Java I/O : Java中的进制详解
作者:李强强 上一篇,泥瓦匠基础地讲了下Java I/O : Bit Operation 位运算.这一讲,泥瓦匠带你走进Java中的进制详解. 一.引子 在Java世界里,99%的工作都是处理这高层. ...
- JAVA中的GC机制详解
优秀Java程序员必须了解的GC工作原理 一个优秀的Java程序员必须了解GC的工作原理.如何优化GC的性能.如何与GC进行有限的交互,因为有一些应用程序对性能要求较高,例如嵌入式系统.实时系统等,只 ...
- Java中的枚举使用详解
转载至:http://www.cnblogs.com/linjiqin/archive/2011/02/11/1951632.html package com.ljq.test; /** * 枚举用法 ...
- Java中getBytes()方法--使用详解
getBytes()方法详解 在Java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组.这表示在不同的操作系统下,返回的东西不一样! 1. str.getByte ...
- HTTP协议报文、工作原理及Java中的HTTP通信技术详解
一.web及网络基础 1.HTTP的历史 1.1.HTTP的概念: HTTP(Hyper Text Transfer Protocol ...
- Java中的枚举类型详解
枚举类型介绍 枚举类型(Enumerated Type) 很早就出现在编程语言中,它被用来将一组类似的值包含到一种类型当中.而这种枚举类型的名称则会被定义成独一无二的类型描述符,在这一点上和常量的定义 ...
- java中hashCode()与equals()详解
首先之所以会将hashCode()与equals()放到一起是因为它们具备一个相同的作用:用来比较某个东西.其中hashCode()主要是用在hash表中提高 查找效率,而equals()则相对而言使 ...
随机推荐
- 禁用linux的密码策略
注释掉文件 /etc/pam.d/system-auth-ac中的 password requisite pam_passwdqc.so enforce=everyone 这一行 #%PAM-1.0 ...
- java:Spring框架2(bean的作用域,静态工厂和实例工厂,自动装配,动态代理)
1.bean的作用域,静态工厂和实例工厂: bean.xml: <?xml version="1.0" encoding="UTF-8"?> < ...
- 如何在 Spring/Spring Boot 中做参数校验
数据的校验的重要性就不用说了,即使在前端对数据进行校验的情况下,我们还是要对传入后端的数据再进行一遍校验,避免用户绕过浏览器直接通过一些 HTTP 工具直接向后端请求一些违法数据. 本文结合自己在项目 ...
- IIS部署网站 HTTP 错误 500.21 - Internal Server Error
HTTP 错误 500.21 - Internal Server Error处理程序“PageHandlerFactory-Integrated”在其模块列表中有一个错误模块“ManagedPipel ...
- 浏览器访问ipv6站点(未绑定主机的ipv6站点)
我们在浏览器直接输入ipv6地址敲回车,一般情况下浏览器会跳转到搜索引擎进行搜索. 我们需要在浏览器器中输入: http://[::1] 或者 [::1]
- 自动部署脚本-bash
from here !/bin/bash Check if user is root if [ $(id -u) != "0" ]; then Echo_Red "Err ...
- cocos2dx基础篇(6) 定时器schedule/update
定时器在大部分游戏中是不可或缺的,即每隔一段时间,就要执行相应的刷新体函数,以更新游戏的画面.时间.进度.敌人的指令等等.cocos2dx为我们提供了定时器schedule相关的操作.其操作函数的定义 ...
- linux中权限对文件和目录的影响?
######### rwx 权限对文件和目录的含义 ############ 代表字符 权限 对文件的含义 对 目录 ...
- Centos6.5修改mysql登陆用户密码
1.修改mysql的登陆设置: vim /etc/my.cnf 并在[mysqld] 下面添加一句:skip-grant-tables=1 添加成功后保存退出. 2.重启mysql并修改密码 重启my ...
- echats--》饼图 如何在环形中央设置 文字?
遇到一个需求,在环形图中央空白部分显示总数量. let data = { totalNum: "", data: [ { val ...