Big Data(八)MapReduce的搭建和初步使用
---恢复内容开始---
回顾:
1.最终开发MR的计算程序
2.hadoop 2.x 出现了一个yarn:资源管理>>MR没有后台场服务
yarn模型:container 容器,里面会运行我们的AppMaster,map/reduce Task
解耦
mapreduce on yarn
架构:RM NM
搭建:
RM要和NN岔开,NM个数要和DN一样
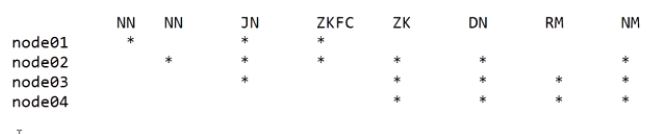
搭建图
----------通过官网:
mapred-site.xml > mapreduce on yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
//shuffle 洗牌 M -shuffle> R
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:,node03:,node04:</value>
</property> <property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mashibing</value>
</property> <property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
流程:
我hdfs等所有的都用root来操作的
node01:
cd $HADOOP_HOME/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
vi yarn-site.xml
scp mapred-site.xml yarn-site.xml node02:`pwd`
scp mapred-site.xml yarn-site.xml node03:`pwd`
scp mapred-site.xml yarn-site.xml node04:`pwd`
vi slaves //可以不用管,搭建hdfs时候已经改过了。。。
start-yarn.sh
node03~:
yarn-daemon.sh start resourcemanager
http://node03:8088
http://node04:8088
This is standby RM. Redirecting to the current active RM: http://node03:8088/
-------MR 官方案例使用:wc
实战:MR ON YARN 的运行方式:
hdfs dfs -mkdir -p /data/wc/input
hdfs dfs -D dfs.blocksize= -put data.txt /data/wc/input
cd $HADOOP_HOME
cd share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6..jar wordcount /data/wc/input /data/wc/output
1)webui:
2)cli:
hdfs dfs -ls /data/wc/output
-rw-r--r-- root supergroup -- : /data/wc/output/_SUCCESS //标志成功的文件
-rw-r--r-- root supergroup -- : /data/wc/output/part-r- //数据文件
part-r-
part-m-
r/m : map+reduce r / map m
hdfs dfs -cat /data/wc/output/part-r-
hdfs dfs -get /data/wc/output/part-r- ./
抛出一个问题:
data.txt 上传会切割成2个block 计算完,发现数据是对的~!~?后边注意听源码分析~!~~
Big Data(八)MapReduce的搭建和初步使用的更多相关文章
- Spring学习笔记--环境搭建和初步理解IOC
Spring框架是一个轻量级的框架,不依赖容器就能够运行,像重量级的框架EJB框架就必须运行在JBoss等支持EJB的容器中,核心思想是IOC,AOP,Spring能够协同Struts,hiberna ...
- Android开发利器之Data Binding Compiler V2 —— 搭建Android MVVM完全体的基础
原创声明: 该文章为原创文章,未经博主同意严禁转载. 前言: Android常用的架构有:MVC.MVP.MVVM,而MVVM是唯一一个官方提供支持组件的架构,我们可以通过Android lifecy ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- Redis总结(八)如何搭建高可用的Redis集群
以前总结Redis 的一些基本的安装和使用,大家可以这这里查看Redis 系列文章:https://www.cnblogs.com/zhangweizhong/category/771056.html ...
- Kubernetes 系列(八):搭建EFK日志收集系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十八):搭建ELK日志采集与分析系统
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈.查找定位系统问题.上一篇说明了日志的多种业务场景以及日志记录的实现方式,那么日志记录下来,相关人员就需要对日志数据进行 ...
- android开发教程(八)——环境搭建之java-ndk
目录 android ndk是android用于开发本地代码的开发工具包.它提供C/C++交叉编译工具.android内核.驱动.已有的C/C++代码,都需要ndk来支持开发. 目前支持以下平台:ar ...
- mybatis框架搭建学习初步
mybatis框架搭建步骤:1. 拷贝jar到lib目录下,而且添加到工程中2. 创建mybatis-config.xml文件,配置数据库连接信息 <environments default=& ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
随机推荐
- 七、创建UcRESTTemplate请求管理器
一.创建UcRESTTemplate管理器封装 import com.alibaba.fastjson.JSON; import org.apache.http.client.config.Reque ...
- 在CentOS7上搭建Kubernetes
来源 中文教程 http://blog.51cto.com/devingeng/2096495?from=singlemessage 官方文档 https://kubernetes.io/docs/s ...
- JavaEE-实验四 HTML与JSP基础编程
1.使用HTML的表单以及表格标签,完成以下的注册界面(验证码不做) html代码(css写于其中) <!DOCTYPE html> <html> <head> & ...
- APP测试流程梳理
APP测试流程梳理 1 APP测试基本流程 1.1流程图 1.2测试周期 测试周期可按项目的开发周期来确定测试时间,一般测试时间为两三周(即15个工作日),根据项目情况以及版本质量可适当缩短或延长测试 ...
- 实现Servlet接口
1 右键项目->Build Path->Configure Build Path 2 Add Library...->Server Runtime 3 Apache Tomcat-& ...
- Day02:正则表达式 / Object / 包装类
JAVA正则表达式 实际开发中,经常需要对字符串数据进行一些复杂的匹配,查找,替换等操作. 通过"正则表达式",可以方便的实现字符串的复杂操作. 正则表达式是一串特定字符,组成一个 ...
- 【HANA系列】SAP HANA跟我学HANA系列之创建分析视图一
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA跟我学HANA系 ...
- docker面试总结
1.什么是docker Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化.容 ...
- 【Python开发】【神经网络与深度学习】网络爬虫之图片自动下载器
python爬虫实战--图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识(没看的赶紧去看)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap show ...
- scrapy 正则汉字的提取方法
[\u4E00-\u9FA5]