MySQL的运行模式及一些特性,引擎、事务、并发控制、优化总结
一 MySQL总体架构
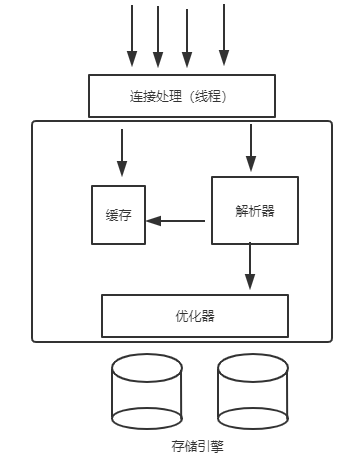
上图是《高性能MySQL》中对MySQL总体架构的描述,客户端对服务端的连接有很多条,有一个专门的处理组件,类似tomcat使用线程池处理请求。解析器负责解析sql语句,在这同时会访问缓存如果缓存有目标数据就直接返回。如果需要执行sql语句,还会先经过优化器重新编排执行过程(重写查询,重排查询表的顺序,选择合适的索引、优化min()max() in()、重排where的顺序以适应左前缀原则等),优化的原则根本上只有一个:从磁盘读取的数据页(一页4K,IO的基本单位)越少越好。例如:
使用where语句想走索引查询,但是如果优化器认为查到的数据基本是全表就会直接走全表扫描,不走索引减少数据页的读取,也无需回表,虽然这也是性能上的优化,但是会让MySQL执行的操作在我们的意料之外,例如不走索引的查询不会对受影响的行加锁,这有时会导致一些问题。因此,有explain这个指令让我们可以知道MySQL的具体执行过程。
以上说的都是服务层面的,一些通用的功能,还包括了用户权限验证啊等等。最下面的则是存储引擎,负责对磁盘数据的存取。看似对磁盘的数据存取只需调用API就行,实际上MySQL在存储引擎这做了很多工作,例如事务控制啊、并发控制啊。
二 引擎
目前最常用的是InnoDB引擎,据说95 %的情况下使用它就行了。主要有点有:
1. 采用聚簇索引,数据本体存在主键索引的叶子结点下,查询速度非常快。
2.还会视情况建立自适应的hash索引(根据数据的值散列运算得到地址,O(1)复杂度),hash索引虽然查询速度非常快但地址随机不适合范围查找,而且冲突多的时候表现不佳。
3. 相比MyISAM额外支持事务、支持行锁。虽然行锁不是任何情况优于表锁,表锁虽然并发量很低但是加锁开销小适合死锁率很高的情况。InnoDB二者都有,可以灵活选择。
4. InnoDB有完善的事务日志及热备份机制,可用性很强,崩溃后恢复很方便
MyISAM实现非常简单,功能非常有限:非聚簇索引(索引文件与数据文件单独保存,通过索引查询时总是需要回行)、不支持事务、锁只支持表锁。只适合小型项目、读操作占大都数写操作非常少的场景。
三 锁与并发控制
锁:MySQL的锁从模式上来说有 共享锁S(读锁)和 排他锁X(写锁),从粒度上或加锁策略上分又分为行锁与表锁。一个引擎支持行锁说明它可以一次给若干行加锁,只支持表锁的话就说明一次加锁过程要么不锁要么把全表锁住。两个事务获取同一目标(若干行或整个表)的不同模式的锁时,冲突情况如下:
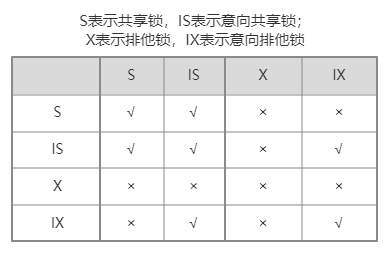
上图的√表示两个事务获取这两种锁时不会冲突,×表示这两种锁不能被两个事务同时获取,会冲突。上图内容其实总结就是:两个锁同时有‘S’,或同时有‘I’是可以同时被两个事务获取的,不会冲突。
MVCC多版本控制并发:由于加锁的开销比较大,导致并发量的下降,因此很多数据库都会有MVCC这个机制。这个机制简单的说是通过给每个事务分配一个版本号,这个事务修改删除等操作影响的行将被打上事务版本号存起来作为一个快照版本,通过这种做法可以在并发环境下避免很多的加锁操作同时也能保证数据库的正确性,从而大幅提高并发量。可以说MVCC是一种变种的行级锁(不是简单无脑给行加锁),当然只有支持行级锁的引擎支持。
具体是MySQL有一个系统版本号,每创建一个事务后就递增,并把这个版本号给新建事务,可以作为这个事务的标识。每个行有隐藏的两列,分别为创建时间、删除时间,实际中我们把这两列存放创建这一行的事务的版本号、删除这一行的版本号。进行各个操作的具体实现是:
insert: 把插入行的创建标识置为当前版本号(即当前事务版本号)。
delete: 把删除行的删除标识置为当前版本号。
update: 先新建一行,把当前版本号作为新建行的创建标识,把当前版本号作为原先行的删除标识。
select:读取数据时有两个条件 a:行的创建标识要早于或等于本事务版本号(保证不会读到后到的事务修改的数据,即解决不可重复读); b:行的删除标识要晚于或未定义本事务版本号(保证不会读到被之前事务执行删除操作的数据,即数据不失效)。
MVCC总结就是:变种的行级锁,增删改时维护行的创建标识和删除标识,读取时对这两个标识加点限制条件。实现了不加锁的情况下读取到正确的数据,少加了这么多锁,大幅提高了并发量。
四 事务与实际加锁策略
事务:事务的概念及ACID特性都是老生常谈了,这里总结一下‘I’隔离性的每个隔离级别下的加锁策略以及解决的问题。

RU级别脏读原因:此级别事务可以读到其他事务修改的且未提交的数据,如事务A将x = 1,事务B此时读到了x = 1,但是A回滚了,数据库中x肯定也不为1了,所以B的数据是脏数据。
RC级别: 此隔离级别规定只有事务提交了,数据才能被其他事务读到,自然解决了脏读。但是却没解决不可重复读的问题:事务A先读到x = 1,然后事务B修改x = 2并提交,这时事务A再读就会发现x = 2,与之前不一样了。
RR级别: 不可重复读使一个事务可能会读到后来的事务修改的数据,为了避免这种情况,有了MVCC机制,读数据时对每一行的版本做一些限制(MVCC在上一部分已总结原理)。
S级别: 这个级别下,操作表时会锁住整个表,所以事务A操作此表时,其他事务不能对这张表做任何操作,包括了插入操作,自然也没了幻读的事情。
注意关于间隙锁的误区:上述都是理论上各个隔离级别解决的问题,在实际的MySQL中,RR隔离级别就没有幻读问题了,因为它有MVCC,快照读不存在幻读,而不是间隙锁的功劳。间隙锁会锁住额外的行(即不止受影响的行),让其他事务没法删和改后面的行。间隙锁的作用具体例子:当事务A在修改删除 id>10的数据时,还没执行完事务B插了进来添加了10条数据id都大于10,这时事务A再恢复执行就会把事务B插进来的数据也给改/删咯。总之就是间隙锁只有在删/改操作才会触发,锁住其他行防止中途插到这来的数据被无辜污染。
MySQL的实际加锁策略:前面也说了,由于有了MVCC,RR及以下级别读操作无需加锁,增删改操作影响的行加X锁,删/改还会有有间隙锁,除非sql中显示指明select .... lock in share mode则为读操作影响的行加S锁。S隔离级别有点特殊,为了防止幻读,读操作时会对整个表加S锁,写操作时会给整个表加X锁。
五 优化总结
合理建表:
变长字段与定长字段尽量分离,每一行的大小固定方便跳跃时计算
常用字段与非常用字段尽量分离,合理分配访问量
列的选择:
优先选用: int -> date time -> enum -> char -> vchar -> text
避免可为null的列,不适合索引的建立
建立合适的索引:
查询时应该用独立的列,像where id+1 = 5是用不上索引的
选择区分度大的列建立索引,像性别这种列就没必要
使用频率高的联合查询 where 列1..and 列2...则需要考虑为这几个列建一个联合索引
由于最左原则,联合索引建立时应该把区分度高的放到左边建立
用到索引覆盖最好,像select * 则几乎用不到索引覆盖
SQL语句的优化:
少用In查询
where ... or ...这类的查询可以拆分为几个select 再用union合并,性能提升明显
表在连接之前先用where筛选,也要避免过多表的连接
select ..时要几个列就写几个,不要多写,会增加数据传送量
MySQL的运行模式及一些特性,引擎、事务、并发控制、优化总结的更多相关文章
- WebSphere ILOG JRules 规则引擎运行模式简介
WebSphere ILOG JRules 规则引擎运行模式简介 引言 作为 JRules 的核心组件,规则引擎决定了在规则集的执行过程中,哪些业务规则会被执行,以及以何种顺序执行.理解并合理选择规则 ...
- MySQL · 引擎特性 · InnoDB 事务子系统介绍
http://mysql.taobao.org/monthly/2015/12/01/ 前言 在前面几期关于 InnoDB Redo 和 Undo 实现的铺垫后,本节我们从上层的角度来阐述 InnoD ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- MySQL 5.7 模式(SQL_MODE)详细说明 转
5.7 默认模式: ONLY_FULL_GROUP_BY, STRICT_TRANS_TABLES, NO_ZERO_IN_DATE, NO_ZERO_DATE, ERROR_FOR_DIVISION ...
- 【Spark深入学习-11】Spark基本概念和运行模式
----本节内容------- 1.大数据基础 1.1大数据平台基本框架 1.2学习大数据的基础 1.3学习Spark的Hadoop基础 2.Hadoop生态基本介绍 2.1Hadoop生态组件介绍 ...
- Apache Flink on K8s:四种运行模式,我该选择哪种?
1. 前言 Apache Flink 是一个分布式流处理引擎,它提供了丰富且易用的API来处理有状态的流处理应用,并且在支持容错的前提下,高效.大规模的运行此类应用.通过支持事件时间(event-ti ...
- javascript运行模式:并发模型 与Event Loop
看了阮一峰老师的JavaScript 运行机制详解:再谈Event Loop和[朴灵评注]的文章,查阅网上相关资料,把自己对javascript运行模式和EVENT loop的理解整理下,不一定对,日 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- MySQL的sql_mode模式说明及设置
MySQL的sql_mode模式说明及设置 MySQL的sql_mode合理设置 sql_mode是个很容易被忽视的变量,默认值是空值,在这种设置下是可以允许一些非法操作的,比如允许一些非法数据的插入 ...
随机推荐
- Go开发[八]goroutine和channel
进程和线程 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位. 一个进程可以创 ...
- 把自己活成AI
干啥都失败,所以从0重新开始. 把自己活成AI 准则1:一件事的对错,只代表这件事本身.多一点的解释都是错误. 准则2:大多数人默认遵守的就是规则和法律.大多数人默认承认的就是道德. 然后取其和法律的 ...
- shoi 魔法树
Harry Potter新学了一种魔法:可以改变树上的果子个数.满心欢喜的他找到了一个巨大的果树,来试验他的新法术.这棵果树共有N个节点,其中节点0是根节点,每个节点u的父亲记为fa[u],保证有fa ...
- TS学习笔记----(一)基础类型
布尔值: boolean let isDone: boolean = false; 数字: number 和JavaScript一样,TS里的所有数字都是浮点数. 支持十进制和十六进制字面量,TS还支 ...
- 20191127 Spring Boot官方文档学习(4.14-4.17)
4.14.使用RestTemplate调用REST服务 如果需要从应用程序调用远程REST服务,则可以使用Spring Framework的RestTemplate类.由于RestTemplate实例 ...
- Centos7安装protobuf3.6.1
简介 最近学习go语言,需要安装protobuf,但是网上的教程很多都不太适用于centos7 的系统.现在总结下protobuf在centos7下的安装教程. protobuf是Google开发出来 ...
- python深度学习培训概念整理
对于公司组织的人工智能学习,每周日一天课程共计五周,已经上了三次,一天课程下来讲了两本书的知识.发现老师讲的速度太快,深度不够,而且其他公司学员有的没有接触过python知识,所以有必要自己花时间多看 ...
- 多线程15-ReaderWriterLockSlim
)); } ); rwl.EnterUpgradeableReadLock(); ...
- Linux常用命令基础
linux 常用指令 基础命令 宿主目录 目录结构 文件管理 目录管理 用户管理 别名管理 压缩包管理 网络设置 shell技巧 帮助方法 /表示根目录 ~表示家目录 软件的安装(光盘中的软件呢): ...
- DateHandler日期处理工具(JSP中使用后台工具类)
1.DateHandler.java package Utils.dateHandler; import java.text.ParseException; import java.text.Simp ...