MySQL如何发型不乱的应对半年数十TB数据增量
前段时间,Oracle官方发布了MySQL 5.7的GA版本。新版本中实现了真正意义的并行复制(基于Group Commit的Group Replication),而不再是基于schema的并行复制。这一特性极大的改善了特定场景下的主从复制延迟过高的状况。随着MySQL成熟度的提升,越来越多的用户选择使用MySQL存放自家的数据,其中不乏使用MySQL来存放大量数据的。
在过去的半年多时间里,听云业务量呈爆发式增长,后端的数据量由去年第一季度的几TB增长到几十TB,业务量翻了十几倍。后端应用及数据库面临的一个突出的问题就是频繁的进行扩容来应对前端流量的增长。数据库层面我们使用MySQL来分布式存储业务数据,数据库集群的架构也比较简单,我们使用开源中间件Amoeba来实现数据的拆分和读写分离。Amoeba后端有几百个数据库的节点组,每个节点组中都包含一对主从实例。master实例负责接受write请求,slave负责接受query请求。如下图:
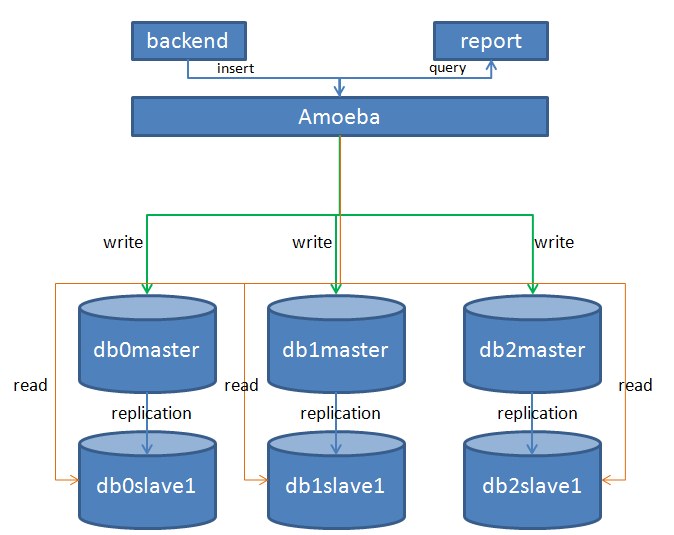
正确的拆分姿势
随着可选择的开源中间件越来越多,好多数据量并不是很大的使用者都会过早的考虑水平拆分数据库。但其实过早的水平拆分未见得是一件有意义的事情。主要原因有两个:一个方面是水平拆分会对现网的业务造成冲击,如果系统在设计之初就没有考虑过后续要进行拆分的话,这个冲击就会被放大。比如业务中有大量的多表join的查询,或者是对事务有强一致性的要求时,水平拆分就捉襟见肘了。另一方面,如果过早的进行了水平拆分,那么到达一定程度后再想要垂直进行拆分时,代价是很大的。以听云app为例,当我们业务库拆成8个分片后,有一天发现数据增长的很快,于是决定对其进行垂直拆分,将小时纬度和天纬度的数据拆分到一个新的实例上去,这时我们不得不同时部署8个节点组来将现有的8个分片上的小时纬度和天纬度的数据迁移出来。工作量相当大。如果水平拆分到了64个片,那么这时要想再做垂直拆分,保证累的你不要不要的。
所以更合理的路线是这样的,首先对业务数据进行垂直拆分,原本一个库按业务单元垂直拆分成多个库,同时应用中配置多个数据源或者使用中间件来访问拆分后的多个库,对应用本身来说,基本没做什么改动,但是后端存储的容量和性能却翻了好几倍。如果某天出现瓶颈之后,再来考虑水平拆分的事情。
优雅的从n到2n
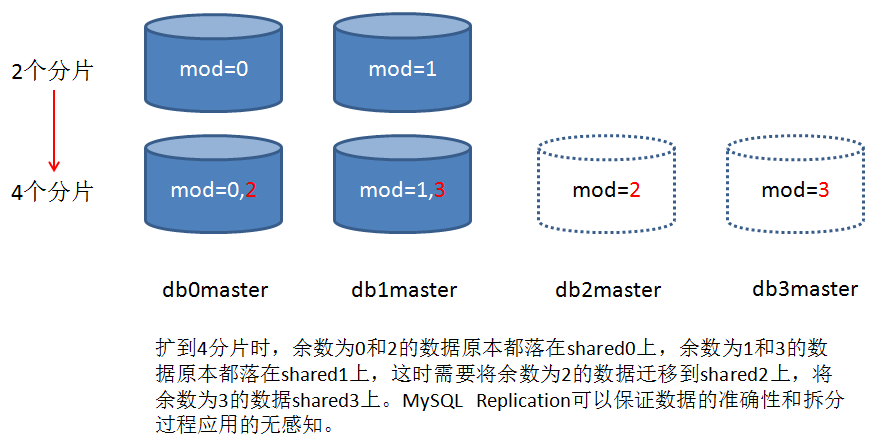
水平扩展过程中最让人头疼的是数据的迁移,以上图中迁移mod(mobile_app_id,4)=2的数据为例,最开始的做法是先创建两个新的节点组shared0_new和shared2,拿shared0的全备恢复到shared0_new和shared2,然后在shared0_new上删除mod(mobile_app_id,4)=2的数据,在shared2上删除mod(mobile_app_id,4)=0的数据,删除操作完成后shared0_new、shared2与shared0做同步,同步删除操作执行过程中的数据增量。同步追上之后,切换amoeba的路由规则,然后下线shared0。这种方式问题很多,首先时耗很高很高,delete完了之后并不能释放存储空间,还要optimize table,同样也是一个漫长的过程。针对大表的delete会产生一个很大的transaction,会在系统表空间中申请很大一块undo,delete完成后事务提交。这个undo空间并不会释放,而是直接给其他事务复用,这无疑会浪费很多存储空间。
后来我们想到一个便捷的办法,就是利用mysqldump的—where参数,在备份数据的时候加一个mod(mobile_app_id,4)=2的参数,就可以单独备份出余数为2的数据,然后拿这个逻辑备份恢复到shared2上去,高效且优雅。
数据倾斜
MySQL分布式存储不可避免的一个问题就是数据倾斜。业务在运行一段时间之后,会发现少部分shared数据增量特别快,原因是该shared上面部分用户的数据量较大。对于数据倾斜问题我们目前的措施是将这些shared迁移到1TB存储上来,但这并非长久之计。因此我们目前正在做一些新的尝试,比如对Amoeba做了一下扩展,扩展后的Amoeba支持将某一个mobile_app_id的数据单独指向后端一个shared节点组,即一个shared只存放一个用户的数据,同时采用ToKuDB存储引擎来存储这部分数据,ToKuDB能够对数据进行有效的压缩,除了查询性能稍有损耗之外,基本具备InnoDB引擎所拥有的特点,而且在线表结构变更比InnoDB快好几倍不止。这些测试基本已经进入尾声,很快将会应用到生产环境。
分布式join
分布式join在业界仍没有完美的解决方案,好在听云业务在设计之初就从业务上避免了多表的join,在业务库中,报表中的每个纬度都会有一张表与之对应,因此查询某个纬度直接就会查询后端的某张表,都是在每张表上做一些操作。目前比较流行的分布式join的解决方案主要有两种:
1、全局表的形式。举个栗子,A表 join B表,B表分布式存储在多个shared上,如果A表比较小,可以在所有的shared上都存一份A表的全量数据。那么就可以很高效的做join。看起来很美好,但是限制很多,应用的场景也很有限。
2、E-R形式。举个栗子,用户表user(id,name)和订单表order(id,uid,detail),按用户id分片,order表的uid引用自user表的id。存放订单时,首先确定该订单对应用户所在的shared,然后将订单记录插入到用户所在的shared上去,这样检索某个用户所有的订单时,就可以避免跨库join低效的操作。
目前的开源中间件中,MyCat对分布式join处理的是比较细腻的。阿里的DRDS对于分布式join的处理也是这样的思路。
MySQL擅长什么
任何一种工具可能都只是解决某一个领域的问题,肯定不是放之四海而皆准的。正确的使用方式是让工具做自己擅长的事情。关系型数据库擅长的是结构化的查询,本身并不擅长巨量数据的清洗。我们在出2015年度APP行业均值数据报表时,需要将后端所有shared上的相关数据汇总起来然后做进一步的分析,这些数据最终汇总在5张表中,每张表都有几亿条的记录。然后对5、6个字段group by之后取某些指标的 sum值,最初尝试在MySQL中处理这些数据,MySQL实例给出24GB的内存,结果OOM了好几次也没有出结果。最后把数据拉到了hadoop集群上,使用impala引擎来汇总数据,处理最大的表近7亿条记录,9min左右出结果。所以,不要有all in one的想法,要让系统中的每个组件做自己擅长的事情。
分布式MySQL架构下的运维
MySQL分布式虽然解决了存储和性能问题,但是在运维支持过程中却带来了一些痛点。
1、跨分片统计数据。中间件是无法对后端的全量数据做查询的,类似年度APP行业均值报表这样的跨分片的全量数据的查询,只能使用自动化脚本从后端逐个shared上提取数据,最终再汇总。
2、DML。经常会有变更表结构的需求,这样的操作大部分中间件是支持不了的,如果只有一个库好说,当后端几十个shared时,就比较头疼了,目前我们并没有很好的处理办法,只能使用自动化脚本批量到后端shared上执行命令,执行完成后,运行一个校验的脚本,人工核对校验脚本的输出内容。
应对这样的情景,发型必然会稍显凌乱,但是目前仍旧很无奈,有必要重新设计一下我们的脚本,写一个输出更加友好,完全自动化的工具出来。
原文链接:http://blog.tingyun.com/web/article/detail/386
MySQL如何发型不乱的应对半年数十TB数据增量的更多相关文章
- 【实战】使用 Kettle 工具将 mysql 数据增量导入到 MongoDB 中
最近有一个将 mysql 数据导入到 MongoDB 中的需求,打算使用 Kettle 工具实现.本文章记录了数据导入从0到1的过程,最终实现了每秒钟快速导入约 1200 条数据.一起来看吧~ 一.K ...
- 如何在发型不乱的前提下应对单日十亿计Web请求
原文地址:http://developer.51cto.com/art/201502/464640.htm 就在不久之前,AppLovin移动广告平台的单一广告请求数量突破了200亿大关——相当于每一 ...
- mysql中获取一天、一周、一月时间数据的各种sql语句写法
今天抽时间整理了一篇mysql中与天.周.月有关的时间数据的sql语句的各种写法,部分是收集资料,全部手工整理,自己学习的同时,分享给大家,并首先默认创建一个表.插入2条数据,便于部分数据的测试,其中 ...
- MySQL 如何只导出 指定的表 的表结构和数据 ( 转 )
MySQL 如何只导出 指定的表 的表结构和数据 ( 转 ) 2011-01-04 15:03:33 分类: MySQL MySQL 如何只导出 指定的表 的表结构和数据 导出更个库的表结构如下:my ...
- MYSQL存储过程,清除指前缀的定表名的数据
MYSQL存储过程,清除指前缀的定表名的数据 DELIMITER $$ DROP PROCEDURE IF EXISTS `drop_table`$$ ),)) BEGIN ) DEFAULT NUL ...
- mysql学习【第3篇】:使用DQL查询数据
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! mysql学习[第3篇]:使用DQL查询数据 DQL语言 DQL( Data Query Lan ...
- mysql获取group by的总记录行数方法
mysql获取group by内部可以获取到某字段的记录分组统计总数,而无法统计出分组的记录数. mysql的SQL_CALC_FOUND_ROWS 使用 获取查询的行数 在很多分页的程序中都这样写: ...
- mysql数据库迁移到oracle数据库后 如何删除相同的数据
mysql数据库迁移到oracle数据库后 如何删除相同的数据 首先搞清楚有多少数据是重复的 select pid from product group by pid having count(pid ...
- mysql查询昨天 一周前 一月前 一年前的数据
mysql 昨天 一周前 一月前 一年前的数据 这里主要用到了DATE_SUB, 参考如下 代码如下: SELECT * FROM yh_contentwhere inputtime>DATE_ ...
随机推荐
- Windows Server 2012安装时所需要的KEY
Windows Server 2012不像Server 2008和2008 R2那样可以先装系统再输入序列号,而是在一开始就必须输入Server 2012 cdkey,目前在网上找到两枚序列号,标准版 ...
- CSS易混淆知识点总结与分享-定位与布局
CSS定位有四种模式:static.relative.absolute.fixed,其它static是默认值,下面分别讲解下各自的特点: static:静态定位,处于动态布局流中,按照页面中的各元素先 ...
- 【Android】做一款类似我要当学霸里的学习监督的APP
我要当学霸这款App有个学习监督的功能,当你启动它的时候,你将无法使用其他App,以此达到帮助人提高自觉性,起到监督学习的效果.最近和同学做了个小App,正好有这个功能,所以就来说说它是怎么实现的. ...
- mysql基于init-connect+binlog完成审计功能
目前社区版本的mysql的审计功能还是比较弱的,基于插件的审计目前存在于Mysql的企业版.Percona和MariaDB上,但是mysql社区版本有提供init-connect选项,基于此我们可以用 ...
- IOS 回收键盘通用代码
感觉IOS的键盘回收好累,所以封装了一个通用一点的方法 -(IBAction)spbResignFirstResponder:(id)sender { // NSLogObj(sender); if ...
- .NET Nancy 详解(三) Respone 和 ViewEngine
我们在ASP.NET MVC中可以返回各种类型的ActionResult(以下图片来自于园友--待补..) 在Nancy 中本着简单粗暴的原则,使用方式略有不同.这期我们使用的版本是Nancy的第一个 ...
- 【转载】ASP.NET MVC Web API 的路由选择
此文章描述了ASP.NET Web API如何将Http请求路由到controller. 路由表 在ASP.NET Web API中,controller是用来处理HTTP请求的一个类.这个类中用于处 ...
- 使用.NET 4.0+ 操作64位系统中的注册表
一.64位系统中的注册表 以 LocalMachine 中的启动项为例: 64位应用的注册表位置还是在: SOFTWARE\Microsoft\Windows\CurrentVersion\Run 而 ...
- Application对象、Session对象、Cookie对象、Server对象初步认识
Application对象:记录应用程序参数的对象 用于共享应用程序级信息,即多个用户共享一个Application对象.在第一个用户请求ASP.NET文件时,将启动应用程序并创建Applicatio ...
- Extjs中全键盘操作,回车跳到下一单元格
listeners: { afterRender: function (thisForm, options) { var els = Ext.DomQuery.select('input[type!= ...