TensorFlow-谷歌深度学习库 用tfrecord写入读取
先介绍一下TensorFlow自带的数据格式:
TensorFlow自带一种数据格式叫做tfrecords。 你可以把你的输入转成专属与TensorFlow的tfrecords格式并保存在本地。
-关于输入碎碎念:输入比如图片,可以有各种格式呀首先你从网上下载到的一般是png或者jpg格式的吧, 你可以把它存成一个矩阵的形式(numpy ndarray),如果不用TensorFlow自带的tfrecords,你其实也可以存成python独有的pickle文件哈。
那么要怎样把数据存成tfrecords呢?
当然是用TensorFlow api库啦,就是下面这个Class:
tf.python_io.TFRecordWriter __init__(self, path, options=None)
Opens file `path` and creates a `TFRecordWriter` writing to it.
Args:
path: The path to the TFRecords file.
options: (optional) A TFRecordOptions object.
在参数列表里指明你想要存放的路径。
tf.python_io.TFRecordWriter('SVHN/train.tfrecords')
虽然有一点没逻辑,但是我还是要介绍一下在处理图片数据输入需要用到的一个TensorFlow Class:
class GFile(tensorflow.python.lib.io.file_io.FileIO)
这是一个用来处理文件IO的类,它包含一个类似正则的查找匹配的函数我们可以用它来找到我们想要的文件->tf.gfile.Glob
它返回一个包含所有满足条件元素的列表。
初始化一个TFRecordWriter完成后,就等于知道了tfrecords的存放路径,接下来就要往这个文件中存数据呀!这里用到了这个类的write函数。
tf.python_io.TFRecordWriter
write(self, record)
Write a string record to the file.
Args:
record: str
当要读取tfrecords中的数据时,要做以下的事情:
首先呢需要一个pipeline,然后需要将tfrecords的存放路径作为一个str放入到一个queue中。string_input_producer这个函数负责完成这件事。
string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, shared_name=None, name=None, cancel_op=None)
Output strings (e.g. filenames) to a queue for an input pipeline.
这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了。
类似的TensorFlow有相对应的TFRecordReader类来读取。
class TFRecordReader(ReaderBase)
A Reader that outputs the records from a TFRecords file
__init__(self, name=None, options=None)
Create a TFRecordReader.
Args:
name: A name for the operation (optional).
options: A TFRecordOptions object (optional).
初始化一个TFRecordWriter完成后,接下来就要往这个文件中读数据呀!这里用到了这个类的read函数。
read(self, queue, name=None)
Returns the next record (key, value) pair produced by a reader. Will dequeue a work unit from queue if necessary (e.g. when the
Reader needs to start reading from a new file since it has
finished with the previous file). Args:
queue: A Queue or a mutable string Tensor representing a handle
to a Queue, with string work items.
name: A name for the operation (optional). Returns:
A tuple of Tensors (key, value).
key: A string scalar Tensor.
value: A string scalar Tensor.
当要读取整个文件的时候,也可以使用WholeFileReader这个阅读器。它是TensorFlow提供的一个类。class tf.WholeFileReader
一个阅读器,读取整个文件,返回文件名称key,以及文件中所有的内容value。
创建阅读器之后,要从文件名队列中读取文件。
read(queue, name=None) method of tensorflow.python.ops.io_ops.WholeFileReader instance
Returns the next record (key, value) pair produced by a reader.返回下一个文件名称key和文件中所有内容的value。
Will dequeue a work unit from queue if necessary (e.g. when the
Reader needs to start reading from a new file since it has
finished with the previous file).
如果需要,会从队列中出队一个单元。读取器在完成上一个文件后,继续读取下一个文件。Args:
queue: A Queue or a mutable string Tensor representing a handle
to a Queue, with string work items.
name: A name for the operation (optional).Returns:
A tuple of Tensors (key, value).
key: A string scalar Tensor.
value: A string scalar Tensor.
关于TensorFlow的读取机制:
转载于https://zhuanlan.zhihu.com/p/27238630
什么是数据读取?假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算。
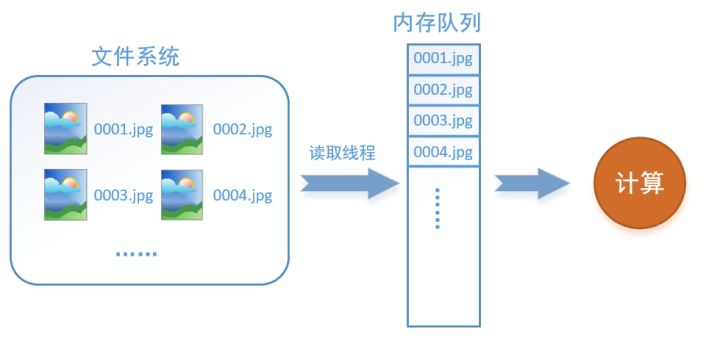
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。

TensorFlow-谷歌深度学习库 用tfrecord写入读取的更多相关文章
- Keras:基于Theano和TensorFlow的深度学习库
catalogue . 引言 . 一些基本概念 . Sequential模型 . 泛型模型 . 常用层 . 卷积层 . 池化层 . 递归层Recurrent . 嵌入层 Embedding 1. 引言 ...
- TensorFlow-谷歌深度学习库 手把手教你如何使用谷歌深度学习云平台
自己的电脑跑cnn, rnn太慢? 还在为自己电脑没有好的gpu而苦恼? 程序一跑一俩天连睡觉也要开着电脑训练? 如果你有这些烦恼何不考虑考虑使用谷歌的云平台呢?注册之后即送300美元噢-下面我就来介 ...
- windows下Anaconda3配置TensorFlow深度学习库
Anaconda3(python3.6)安装tensorflow Anaconda3中安装tensorflow3是非常简单的,仅需通过 pip install tensorflow 测试代码: imp ...
- 人工智能不过尔尔,基于Python3深度学习库Keras/TensorFlow打造属于自己的聊天机器人(ChatRobot)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_178 聊天机器人(ChatRobot)的概念我们并不陌生,也许你曾经在百无聊赖之下和Siri打情骂俏过,亦或是闲暇之余与小爱同学谈 ...
- 30个深度学习库:按Python、C++、Java、JavaScript、R等10种语言分类
30个深度学习库:按Python.C++.Java.JavaScript.R等10种语言分类 包括 Python.C++.Java.JavaScript.R.Haskell等在内的一系列编程语言的深度 ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- Kelp.Net是一个用c#编写的深度学习库
Kelp.Net是一个用c#编写的深度学习库 基于C#的机器学习--c# .NET中直观的深度学习 在本章中,将会学到: l 如何使用Kelp.Net来执行自己的测试 l 如何编写测试 l ...
- 深度学习库 SynapseML for .NET 发布0.1 版本
2021年11月 微软开源一款简单的.多语言的.大规模并行的机器学习库 SynapseML(以前称为 MMLSpark),以帮助开发人员简化机器学习管道的创建.具体参见[1]微软深度学习库 Synap ...
随机推荐
- dojo中获取表格中某一行的某个值
dojo中经常出现对表格中的某行进行操作,如单击某行修改.删除等.那怎样获取某行的唯一标示呢? 如查询表格中的某列有个userId,并且这个是唯一的,那么可以通过它来访问这一列 具体操作代码如下: v ...
- 使用 opencv 将图片压缩到指定文件尺寸
前言 图片压缩应用很广泛,如生成缩略图等.前期我在进行图片处理的过程中碰到了一个问题,就是如何将图片压缩到指定尺寸,此处尺寸指的是生成图片文件的大小. 我使用 opencv 进行图片处理,于是想着直接 ...
- Servlet程序
编写: (1)搭建javaweb项目: 1,创建一个java项目:HelloServletWeb 2,在HelloServletWeb中创建一个文件夹webapp表示Web的根 3,在webapp中创 ...
- 洛谷P4219 [BJOI2014]大融合(LCT,Splay)
LCT维护子树信息的思路总结与其它问题详见我的LCT总结 思路分析 动态连边,LCT题目跑不了了.然而这题又有点奇特的地方. 我们分析一下,查询操作就是要让我们求出砍断这条边后,x和y各自子树大小的乘 ...
- [APIO2009]会议中心
[APIO2009]会议中心 题目大意: 原网址与样例戳我! 给定n个区间,询问以下问题: 1.最多能够选择多少个不相交的区间? 2.在第一问的基础上,输出字典序最小的方案. 数据范围:\(n \le ...
- [HDU4812]D Tree
vjudge 题意:给一棵树,每个点上有一个权值,求一条路径使得路径上权值的乘积膜\(10^6+3\)的结果为\(K\),输出路径的两个端点\(x,y\).如有多解,设\(x<y\),输出\(x ...
- 【BZOJ4816】数字表格(莫比乌斯反演)
[BZOJ4816]数字表格(莫比乌斯反演) 题面 BZOJ 求 \[\prod_{i=1}^n\prod_{j=1}^mf[gcd(i,j)]\] 题解 忽然不知道这个要怎么表示... 就写成这样吧 ...
- 【NOIP2012】疫情控制(二分,倍增,贪心)
洛谷上的题目链接,题目不在赘述 题解 既然要时间最短,首先考虑二分. 因此,考虑二分时间,问题转换为如何检查能否到达. 如果一支军队一直向上走,能够到达根节点,那么他可以通过根节点到达其他的节点,因此 ...
- [BZOJ1306] [CQOI2009] match循环赛 (搜索)
Description Input 第一行包含一个正整数n,队伍的个数.第二行包含n个非负整数,即每支队伍的得分. Output 输出仅一行,即可能的分数表数目.保证至少存在一个可能的分数表. Sam ...
- oracle数据库和表的操作
一.字符函数 (1)连接符 concat --连接符 select concat('10086','-')||'1531234567' 电话号 from dual; (2)首字母大写 initcap ...