Mahout 系列之--canopy 算法
Canopy 算法,流程简单,容易实现,一下是算法
(1)设样本集合为S,确定两个阈值t1和t2,且t1>t2。
(2)任取一个样本点p属于S,作为一个Canopy,记为C,从S中移除p。
(3)计算S中所有点到p的距离dist
(4)若dist<t1,则将相应点归到C,作为弱关联。
(5)若dist<t2,则将相应点移出S,作为强关联。
(6)重复(2)~(5),直至S为空。
上面的过程可以看出,dist<t2的点属于有且仅有一个簇,t2<dist<t1 的点可能属于多个簇。可见Canopy是一种软聚类。
Canopy有消除孤立点的作用,而K-means在这方面却无能为力。建立canopies之后,可以删除那些包含数据点数目较少的canopy,往往这些canopy是包含孤立点的。根据canopy内点的数目,来决定聚类中心数目k,这样效果比较好。
Canopy 聚类结果如下图:
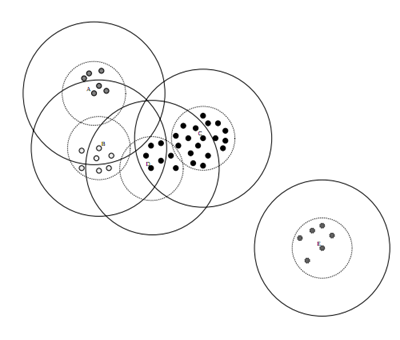
Mahout canopy 聚类流程如下:
(1)将文本向量化。
在文档向量化之前,需要将出于一个目录中的文档序列化,所谓序列化就是将文档内容写成SequenceFile 格式,key:文档标题 ,value:文档内容。
该过程将文本分词,计算ngram ,特征抽取,生成字典,计算特征权重生成文档词矩阵。
值得说明的是该过程可以由其他的方法替代,不仅限于用Mahout ,只要能生成向量即可。
(2)用Canopy 聚类。
参数:
距离度量 :cos距离(常用于文本距离度量)
T1:0.5左右
T2:0.25 左右
输入:向量化生成的sequencefile
当T1过大时,会使许多点属于多个Canopy,可能会造成各个簇的中心点间距离较近,各簇
间区别不明显;
当T2过大时,增加强标记数据点的数量,会减少簇个个数;T2过小,会增加簇的个数,同时
增加计算时间
(3)结果。
../clusteredPoints 最终结果,类标志 向量
.. /clusters-0 簇中心
ClusteredPoints 数据如下:
Key: 4: Value: 1.0: [1.000, -0.213, -0.956, -0.003, 0.056, 0.091, 0.017, -0.024, 1.000]
Key: 3: Value: 1.0: [0:1.000, 1:3.147, 2:2.129, 3:-0.006, 4:-0.056, 5:-0.063, 6:-0.002, 7:0.109]
Key: 0: Value: 1.0: [1.000, -2.165, -2.718, -0.008, 0.043, -0.103, -0.156, -0.024, 1.000]
Key: 0: Value: 1.0: [1.000, -4.337, -2.686, -0.012, 0.122, 0.082, -0.021, -0.042, 1.000]
clusters-0 数据如下:
Key: C-0: Value: C-0: {8:0.9903846153846154,7:0.03641560060121199,6:-0.011104891601517057,5:-0.018746460252920098,4:0.0018451485029808527,3:0.02659166333809029,2:-2.0914853859015725,1:-2.2735344078494943,0:1.0}
Key: C-1: Value: C-1: {8:0.005681818181818182,7:-0.005705937927015517,6:0.018373023001902314,5:-0.02408518413578759,4:-0.0649238556654074,3:-0.003042417008279087,2:2.5123232537912283,1:2.0664589339683306,0:1.0}
Key: C-2: Value: C-2: {8:0.006493506493506494,7:-0.01019964334516059,6:0.023497740573602648,5:-0.03181163901232867,4:-0.05941297790332273,3:-0.017834190866604666,2:2.382976575761404,1:2.1735244959638065,0:1.0}
Key: C-3: Value: C-3: {8:0.007575757575757576,7:-0.011551099054202508,6:0.023459485214657627,5:-0.02978024551438345,4:-0.05926968634175531,3:-0.016503525708008473,2:2.2626847929337592,1:2.1570361543820167,0:1.0}
Key: C-4: Value: C-4: {8:0.9230769230769231,7:0.04076923076923077,6:-0.011730769230769232,5:-0.019307692307692307,4:0.024653846153846155,3:0.01373076923076923
Mahout 系列之--canopy 算法的更多相关文章
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- mahout之canopy算法简单理解
canopy是聚类算法的一种实现 它是一种快速,简单,但是不太准确的聚类算法 canopy通过两个人为确定的阈值t1,t2来对数据进行计算,可以达到将一堆混乱的数据分类成有一定规则的n个数据堆 由于c ...
- Canopy算法聚类
Canopy一般用在Kmeans之前的粗聚类.考虑到Kmeans在使用上必须要确定K的大小,而往往数据集预先不能确定K的值大小的,这样如果 K取的不合理会带来K均值的误差很大(也就是说K均值对噪声的抗 ...
- SM系列国密算法(转)
原文地址:科普一下SM系列国密算法(从零开始学区块链 189) 众所周知,为了保障商用密码的安全性,国家商用密码管理办公室制定了一系列密码标准,包括SM1(SCB2).SM2.SM3.SM4.SM7. ...
- 数据挖掘算法之聚类分析(二)canopy算法
canopy是聚类算法的一种实现 它是一种快速,简单,但是不太准确的聚类算法 canopy通过两个人为确定的阈值t1,t2来对数据进行计算,可以达到将一堆混乱的数据分类成有一定规则的n个数据堆 由于c ...
- Canopy算法计算聚类的簇数
Kmeans算是是聚类中的经典算法.步骤例如以下: 选择K个点作为初始质心 repeat 将每一个点指派到近期的质心,形成K个簇 又一次计算每一个簇的质心 until 簇不发生变化或达到最大迭代次数 ...
- Mahout系列之----kmeans 聚类
Kmeans是最经典的聚类算法之一,它的优美简单.快速高效被广泛使用. Kmeans算法描述 输入:簇的数目k:包含n个对象的数据集D. 输出:k个簇的集合. 方法: 从D中任意选择k个对象作为初始簇 ...
- mahout运行测试与kmeans算法解析
在使用mahout之前要安装并启动hadoop集群 将mahout的包上传至linux中并解压即可 mahout下载地址: 点击打开链接 mahout中的算法大致可以分为三大类: 聚类,协同过滤和分类 ...
- mahout运行测试与数据挖掘算法之聚类分析(一)kmeans算法解析
在使用mahout之前要安装并启动hadoop集群 将mahout的包上传至linux中并解压即可 mahout下载地址: 点击打开链接 mahout中的算法大致可以分为三大类: 聚类,协同过滤和分类 ...
随机推荐
- Swift基础之如何使用iOS 9的Core Spotlight框架
本文由CocoaChina译者KingOfOnePiece(博客)翻译 作者:GABRIEL THEODOROPOULOS?校对:hyhSuper 原文:How To Use Core Spotlig ...
- windows上安装nodejs,升级npm,安装webpack指南
安装nodejs https://nodejs.org/en/ 安装webpack和其他一些常用的 npm install -g node-gyp webpack coffee-script 监控 w ...
- android studio 转为eclipse快捷键后还存在的问题汇总
提取局部变量:Ctrl+Alt+V 提取全局变量:Ctrl+Alt+F 提取方法:Shit+Alt+M 使用android studio 出现红色下划线代表有错误产生,eclipse中的Ctrl+1( ...
- 等价于n*n的矩阵,填写0,1,要求每行每列的都有偶数个1 (没有1也是偶数个),问有多少种方法。
#define N 4 /* * 公式: * f(n) = 2^((n - 1) ^2) */ int calWays(int n) { int mutiNum = (n - 1) * (n - 1) ...
- 详解EBS接口开发之采购订单导入
采购订单常用标准表简介 1.1 常用标准表 如下表中列出了与采购订单导入相关的表和说明: 表名 说明 其他信息 po.po_headers_all 采购订单头 采购订单号,采购类型,供应商,地点, ...
- android的消息通知栏
在android的应用层中,涉及到很多应用框架,例如:Service框架,Activity管理机制,Broadcast机制,对话框框架,标题栏框架,状态栏框架,通知机制,ActionBar框架等等. ...
- 【Netty源码学习】ChannelPipeline(一)
ChannelPipeline类似于一个管道,管道中存放的是一系列对读取数据进行业务操作的ChannelHandler. 1.ChannelPipeline的结构图: 在之前的博客[Netty源码学习 ...
- 15 ActionProvider代码例子
Menu文件夹下代码: <menu xmlns:android="http://schemas.android.com/apk/res/android" > <! ...
- 2.0、Android Studio编写你的应用
Android Studio包含了每个开发阶段的各种工具,但是最重要就是编写代码. 高效编码 接下来的是能够帮助你高效编程的方法. 使用Lint快速修复 Android Studio提供一个叫Lint ...
- 1.1、Android Studio创建一个项目
Android Studio中的项目包含一个或多个模块.本节帮助你创建一个新的项目. 创建一个新的项目 如果你之前没有打开项目,Android Studio显示欢迎页面,通过点击Start a New ...