java爬虫系列第三讲-获取页面中绝对路径的各种方法
在使用webmgiac的过程中,很多时候我们需要抓取连接的绝对路径,总结了几种方法,示例代码放在最后。
以和讯网的一个页面为例:
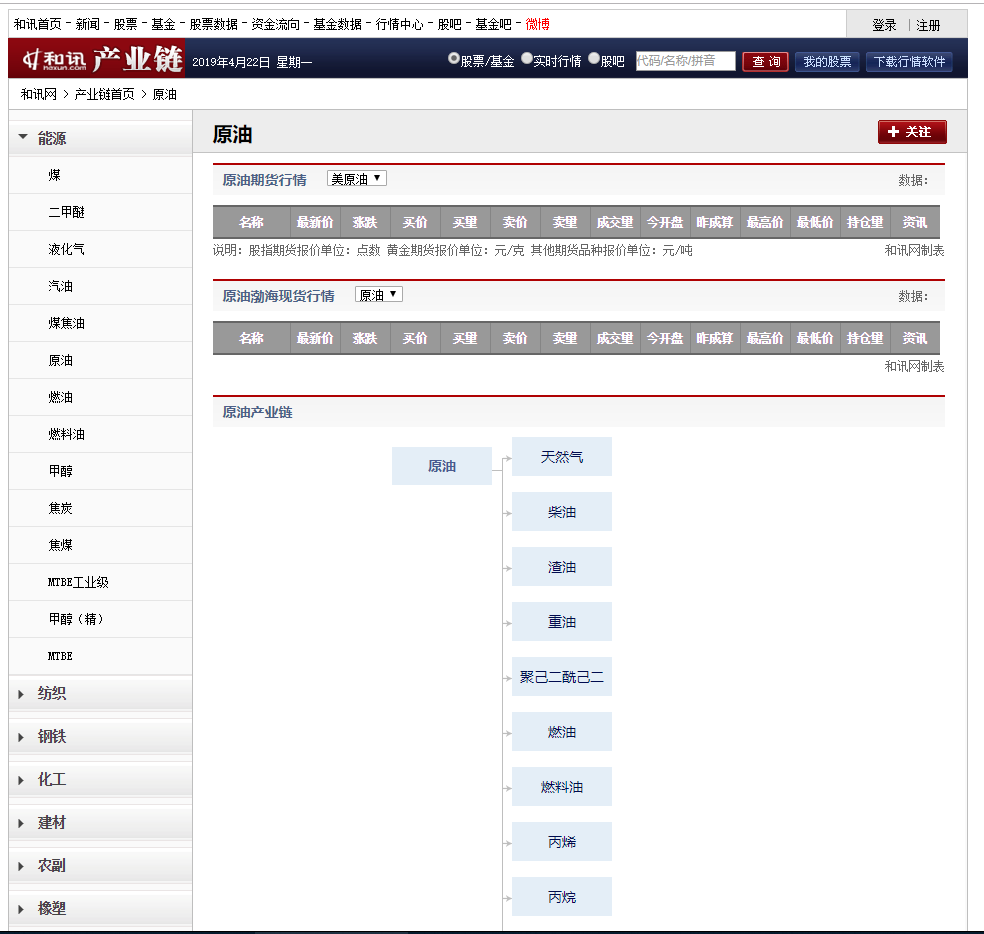
xpath方式获取
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']").links().all());
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']//a//@abs:href").all());
xpath+css选择器方式获取
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']").css("a", "abs:href").all());
css选择器方式获取
log.info("{}", page.getHtml().css("div[id='cyldata']").css("a", "abs:href").all());
log.info("{}", page.getHtml().css("div[id='cyldata']").links().all());
log.info("{}", page.getHtml().css("div[id='cyldata'] a").links().all());
log.info("{}", page.getHtml().css("div[id='cyldata'] a", "abs:href").all());
jsoup方式获取
for (Element element : Jsoup.parse(page.getRawText(), page.getRequest().getUrl()).select("#cyldata a")) {
log.info("{}", element.attr("abs:href"));
log.info("{}", element.absUrl("href"));
}
jsoup中stringutil工具类方式获取
for (Element element : Jsoup.parse(page.getRawText(), page.getRequest().getUrl()).select("#cyldata a")) {
log.info("{}", StringUtil.resolve(page.getRequest().getUrl(), element.attr("href")));
}
示例代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.ady01</groupId>
<artifactId>java-pachong</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>java-pachong</name>
<description>java爬虫项目</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- webmagic start -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>commons-io</artifactId>
<groupId>commons-io</groupId>
</exclusion>
<exclusion>
<artifactId>commons-io</artifactId>
<groupId>commons-io</groupId>
</exclusion>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-selenium</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>2.2.1</version>
</dependency>
<!-- webmagic end -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.11</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
package com.ady01.demo3;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.helper.StringUtil;
import org.jsoup.nodes.Element;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* <b>description</b>:webmagic中获取绝对路径 <br>
* <b>time</b>:2019/4/22 10:42 <br>
* <b>author</b>:微信公众号:路人甲Java,专注于java技术分享(带你玩转 爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Slf4j
public class AbsHrefPageProcessor implements PageProcessor {
Site site = Site.me().setSleepTime(1000);
@Override
public void process(Page page) {
//获取超链接绝对路径的方式
log.info("----------------------xpath方式获取------------------------");
//xpath方式获取
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']").links().all());
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']//a//@abs:href").all());
//xpath+css选择器方式获取
log.info("----------------------xpath+css选择器方式获取------------------------");
log.info("{}", page.getHtml().xpath("//div[@id='cyldata']").css("a", "abs:href").all());
//css选择器方式获取
log.info("----------------------css选择器方式获取------------------------");
log.info("{}", page.getHtml().css("div[id='cyldata']").css("a", "abs:href").all());
log.info("{}", page.getHtml().css("div[id='cyldata']").links().all());
log.info("{}", page.getHtml().css("div[id='cyldata'] a").links().all());
log.info("{}", page.getHtml().css("div[id='cyldata'] a", "abs:href").all());
//jsoup方式获取
log.info("----------------------jsoup方式获取------------------------");
for (Element element : Jsoup.parse(page.getRawText(), page.getRequest().getUrl()).select("#cyldata a")) {
log.info("{}", element.attr("abs:href"));
log.info("{}", element.absUrl("href"));
}
//jsoup中stringutil工具类方式获取
log.info("----------------------jsoup中stringutil工具类方式获取------------------------");
for (Element element : Jsoup.parse(page.getRawText(), page.getRequest().getUrl()).select("#cyldata a")) {
log.info("{}", StringUtil.resolve(page.getRequest().getUrl(), element.attr("href")));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Request request = new Request("http://industry.hexun.com/c193_59.shtml");
Spider.create(new AbsHrefPageProcessor()).addRequest(request).run();
}
}
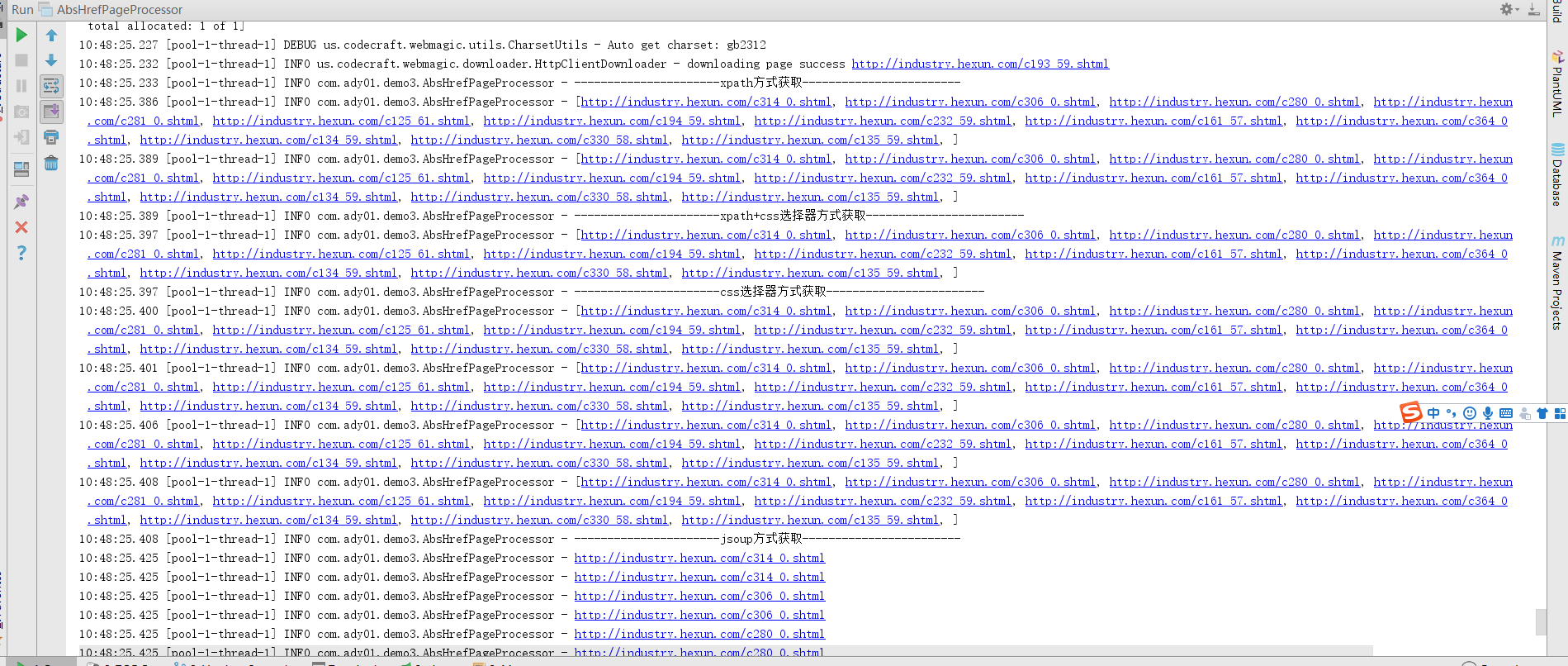
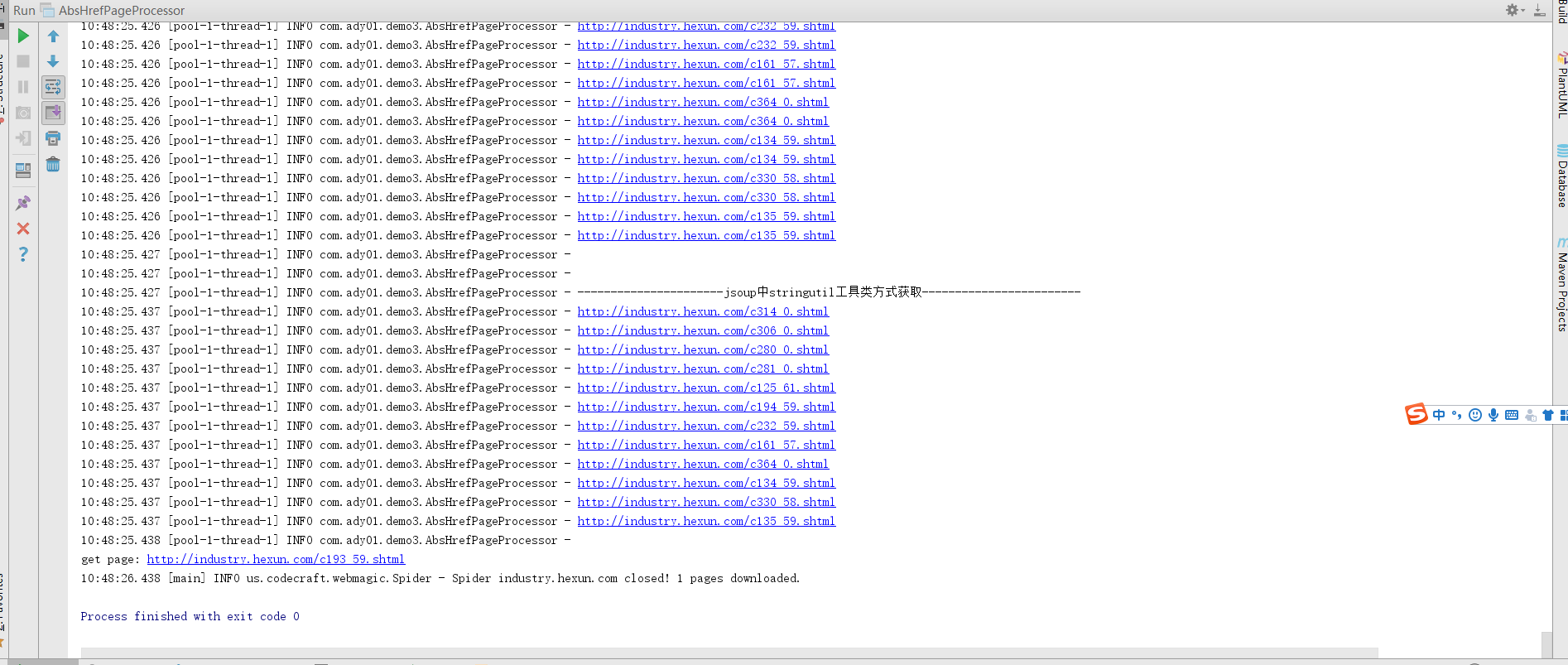
执行结果:
java爬虫系列第三讲-获取页面中绝对路径的各种方法的更多相关文章
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
- Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容.上一篇随笔<Java爬虫系列一:写在开始前>中提到了HttpClient可以抓取页面内 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- js获取页面中图片的总数
查看效果:http://keleyi.com/keleyi/phtml/image/9.htm 下面是完整代码: <html><body><div id="ke ...
- jQuery基础学习5——JavaScript方法获取页面中的元素
给网页中的所有<p>元素添加onclick事件 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN& ...
- 获取页面中任意一个元素距离body的偏移量
//offSet:等同于jQuery中的offSet方法,获取页面中任意一个元素距离body的偏移量function offSet(curEle) { var totalLeft = null; va ...
随机推荐
- js 的 骚操作
单行的js 代码虽然简洁,但却不易维护,甚至难以理解, 但这却并不影响前端童鞋们编写简洁代码的热情, 一 , 生成随机ID // 生成长度为10的随机字母数字字符串 Math.random().t ...
- 安装Mysql时端口号3306被占用,解决方法
当我们在卸载mysql数据库重新安装的时候,会出现端口号3306被占用的情况 有两种解决方案: 一:可以不使用3306端口,也可以换成别的端口,如3307,3308等等 二:可以打开命令窗口 1.wi ...
- html学习之路--简单图片轮播
一个简单的图片轮播效果 photo.html页面代码,基本的HTML结构,在main中显示图片,此处图片依次命名为1.jpg.2.jpg.3.jpg.4.jpg. <!DOCTYPE html& ...
- openlayers4 入门开发系列之地图属性查询篇(附源码下载)
前言 openlayers4 官网的 api 文档介绍地址 openlayers4 api,里面详细的介绍 openlayers4 各个类的介绍,还有就是在线例子:openlayers4 官网在线例子 ...
- 003-005:Java平台相关的面试题
本文首发于公众号:javaadu 003:字节码是什么? 在Java中,字节码存放于以.class结尾的二进制文件. 字节码之于Java,类似于汇编语言之于C/C++.对于C/C++语言来说,不同的平 ...
- The operation could not be performed because OLE DB provider "SQLNCLI11" for linked server "SDSSDFCC" was unable to begin a distributed transaction.
Question: SQL SERVER 通过Linkserver连接A和B 2台,A对B执行单条的增删改查没有异常(没有配置DTC) 但是开启事务后就会出现报错 Solution: 在A和B上配置D ...
- Django-CSRF跨站请求伪造防护
前言 CSRF全称Cross-site request forgery(跨站请求伪造),是一种网络的攻击方式,也被称为“One Click Attack”或者Session Riding,通常缩写为C ...
- ML.NET 发布0.11版本:.NET中的机器学习,为TensorFlow和ONNX添加了新功能
微软发布了其最新版本的机器学习框架:ML.NET 0.11带来了新功能和突破性变化. 新版本的机器学习开源框架为TensorFlow和ONNX添加了新功能,但也包括一些重大变化, 这也是发布RC版本之 ...
- 如何使用SignTool签署应用程序包
备注 有关签署UWP应用程序包的信息,请参阅使用SignTool签署应用程序包. 了解如何使用SignTool对Windows应用商店应用包进行签名,以便部署它们.SignTool是Windows软件 ...
- 开放windows服务器端口-----以打开端口8080为例
[转载]原文地址:https://blog.csdn.net/spt_dream/article/details/75014619 本文记录两个内容: 1.win7下打开端口 2.服务器(2003或者 ...