hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
spark-2.1.0-bin-hadoop2.7.tgz
下载地址:http://spark.apache.org/downloads.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=PATH:PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1.8.0_121
export SCALA_HOME=/usr/scala-2.12.1
export SPARK_MASTER_IP=10.10.0.1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.7.3/etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-01
DEV-SH-MAP-02
DEV-SH-MAP-03
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
34225 SecondaryNameNode
33922 NameNode49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:

34225 SecondaryNameNode
33922 NameNode
36562 Worker
49702 Jps
34632 NodeManager
34523 ResourceManager
34028 DataNode
36415 Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
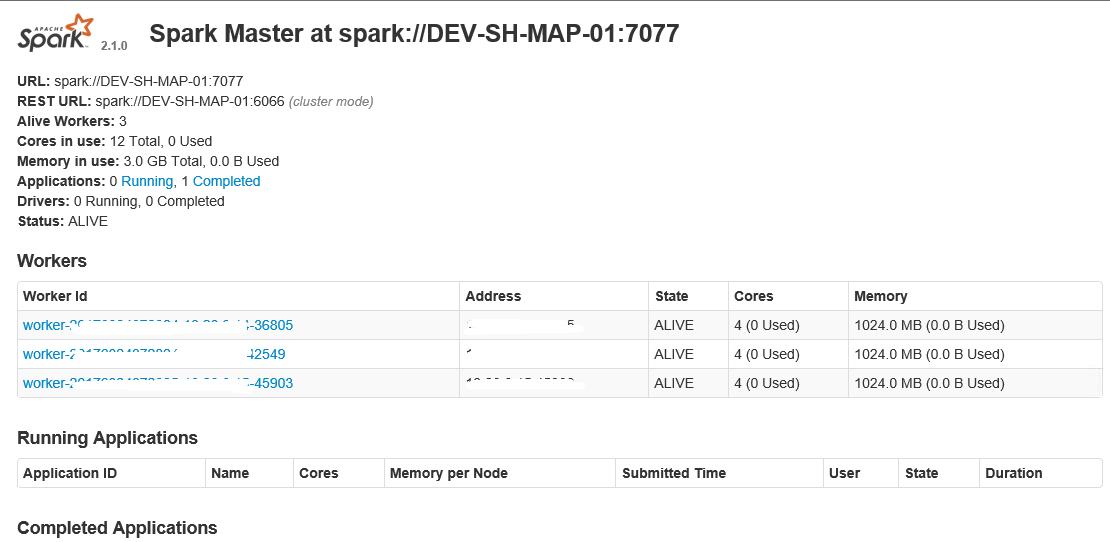
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
一.文件准备 scala-2.12.1.tgz 下载地址: http://www.scala-lang.org/download/2.12.1.html 二.工具准备 2.1 Xshell 2.2 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
一.依赖安装 安装JDK 二.文件准备 hadoop-2.7.3.tar.gz 2.2 下载地址 http://hadoop.apache.org/releases.html 三.工具准备 3.1 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
一.文件准备 下载jdk-8u131-linux-x64.tar.gz 二.工具准备 2.1 Xshell 2.2 Xftp 三.操作步骤 3.1 解压文件: $ tar zxvf jdk-8u131 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构.与MapReduce不同,Spark并不局限于编写map和reduce ...
- Windows Server 2003 IIS6.0+PHP5(FastCGI)+MySQL5环境搭建教程
准备篇 一.环境说明: 操作系统:Windows Server 2003 SP2 32位 PHP版本:php 5.3.14(我用的php 5.3.10安装版) MySQL版本:MySQL5.5.25 ...
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
随机推荐
- 云计算之路-阿里云上:docker swarm 问题最新进展
今天中午我们在 docker swarm 集群上发布应用时遇到了一个奇怪的 docker swarm 内置负载均衡的问题,该应用的 2 个新容器成功启动后,在容器内访问正常,但通过服务名访问时一会正常 ...
- 萌新关于C#委托一点见解
开博第一写C#委托(一个简单的委托) 1.关于委托,一直是学习c#的萌新们的噩梦,小生也是.最近在学委托感觉瞬间被虐成狗,但作为C#中极为重要的一个内容,学好了将会及大地减少我们的代码量,而且这也是够 ...
- The POM for ... is missing, no dependency information available
今天在重温淘淘商城的项目,准备用idea重写次,换个bootstrap的前端框架,但是在用idea构建maven项目后编译时却报错了: 经再三确认,common工程自身并没有任何问题,引用这个工程的地 ...
- PHP7变量的内部实现
PHP7变量的内部实现 受篇幅限制,这篇文章将分为两个部分.本部分会讲解PHP5和PHP7在zval结构体的差异,同时也会讨论引用的实现.第二部分会深入探究一些数据类型如string和对象的实现. P ...
- 第一迭代目标——future weather
第一个迭代目标(主要数据) 引导界面.获取天气数据(api接口).天气分享 人员工作分配: 引导界面:周子静,界面的引导,耗时3天 获取天气数据:包舒婷.俞先浩,api接口,耗时5天 天气分享:郭磊蕾 ...
- 笔记:MyBatis XML配置-Settings 完整属性表
设置参数 描述 有效值 默认值 cacheEnabled 该配置影响的所有映射器中配置的缓存的全局开关. true | false true lazyLoadingEnabled 延迟加载的全局开关. ...
- unittest自动化使用HTMLTestRunner的中文编码问题
1.使用unittest自动化测试框架,使用HTMLTestRunner生成测试报告,中文乱码问题! 如图 2.解决方法: 第一步:先在自己的测试脚本中添加 import sys reload(sys ...
- Java基础学习笔记八 Java基础语法之接口和多态
接口 接口概念 接口是功能的集合,同样可看做是一种数据类型,是比抽象类更为抽象的”类”.接口只描述所应该具备的方法,并没有具体实现,具体的实现由接口的实现类(相当于接口的子类)来完成.这样将功能的定义 ...
- Bean validation
公司测试非常严格,要求我们对每个参数的长度进行校验,提了一个参数长度校验的单,然后我们老大就把我们的代码全部打回去了.... 一个bean类中往往有超多变量,如果一个个写if else,够呛,而且圈复 ...
- css代码整理
width:(宽度) height:(高度) border:1px solid red:(边框 :边框粗细 显示 颜色) border-radius:10deg:(边框变圆角) box-shadow: ...