hadoop hdfs 高可用
单点故障:
如果某一个节点或服务出了问题,导致服务不可用
单点故障解决方式:
1.给容易出故障的地方安排备份
2.一主一备,要求同一时刻只能有一个对外提供服务
3.当active挂掉之后,standby很短时间内切换成为active,保证服务可用性
HA脑裂问题:
1.主备互相认为对方挂掉,都去启动
2.主备互相认为对方启动,都把自己切换为备,就没有服务了
hadoop hdfs HA:使用Clouera QJM解决hdfs HA
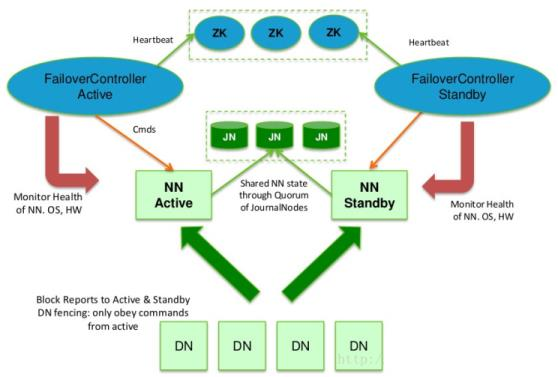
一.如何保证集群之间不会出现脑裂问题,使得集群同一时间有且只有一个active
1.启动ha集群,两个zkfc到zk集群指定目录创建znode(非序列化,短暂的),谁创建成功,谁对应的那台机器的nn就是active,没创建成功的设置该节点的监听.
2.当active节点不健康,zkfc能够感知不健康信息,断开自己跟zk集群的连接,节点被zk删除,触发监听事件,另外一个standby对应就会收到监听
3.当standby对应的zkfc收到监听回调,远程补刀,保证active不能假死,防止出现脑裂问题,ssh active kill -9 xxxx(6.因为补刀的存在,需要在两个nn之间互相免密登录)
4.补刀回来,再去zk注册该节点,同时把自己的状态变成active
5. 之前的那个active机器修复好之后,重新启动,zkfc去注册监听,设置节点监听,把自己变成standby
二.如何保证active standby之间元数据同步
1.JournalNode集群2n+1共享edits log
2..active向jn集群写edit log,只有n+1台写成功,即认为写成功
3..satndby就会感知jn集群有数据变化,把变化的edits log拉取过来,重演一遍操作记录
4.实际上standby跟所需要的内存一模一样,内存中的元数据也时刻在变化,但是不对外提供服务
三.DN怎么知道接收是Active还是Standby的信息
1.每个 NN 改变状态的时候,向 DN 发送自己的状态和一个序列号。
2.DN 在运行过程中维护此序列号,当 failover 时,新的 NN 在返回 DN 心跳时会返回自
己的 active 状态和一个更大的序列号。DN 接收到这个返回则认为该 NN 为新的 active。
3.如果这时原来的 active NN 恢复,返回给 DN 的心跳信息包含 active 状态和原来的序
列号,这时 DN 就会拒绝这个 NN 的命令。
hadoop hdfs 高可用的更多相关文章
- Hadoop框架:HDFS高可用环境配置
本文源码:GitHub·点这里 || GitEE·点这里 一.HDFS高可用 1.基础描述 在单点或者少数节点故障的情况下,集群还可以正常的提供服务,HDFS高可用机制可以通过配置Active/Sta ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- Hadoop完全高可用集群安装
架构图(HA模型没有SNN节点) 用vm规划了8台机器,用到了7台,SNN节点没用 NN DN SN ZKFC ZK JNN RM NM node1 * * node2 * ...
- Hadoop HA(高可用) 详细安装步骤
什么是HA? HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用.(简言之,有两台机器 ...
- HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 高可用分布式环境搭建 CSDN:HDFS 高可用分布式环境搭建 首先,一定要先完成分布式环境搭建 并验证成功 然后在 no ...
- HADOOP docker(二):HDFS 高可用原理
1.环境简述2.QJM HA简述2.1为什么要做HDFS HA?2.2 HDFS HA的方式2.2 HSFS HA的结构2.3 机器要求3.部署HDFS HA3.1 详细配置3.2 部署HDF ...
- HADOOP docker(三):HDFS高可用实验
前言1.机器环境2.配置HA2.1 修改hdfs-site.xml2.2 设置core-site.xml3.配置手动HA3.1 关闭YARN.HDFS3.2 启动HDFS HA4.配置自动HA4. ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
随机推荐
- java子类重写父类的要点
子类不能重写父类的静态方法,私有方法.即使你看到子类中存在貌似是重写的父类的静态方法或者私有方法,编译是没有问题的,但那其实是你重新又定义的方法,不是重写.具体有关重写父类方法的规则如下:重写规则之一 ...
- Django中ORM介绍和字段及其参数
ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...
- sqlalchemy通过ssh连接远程mysql服务器
首先需要一个模块sshtunnel,如果没有直接pip install sshtunnel from sshtunnel import SSHTunnelForwarder from sqlalche ...
- Spring之IOC(一)
Spring之IOC(一) 对于Spring的基本概念在这里就不在赘述了. Spring的最核心的两部分则是AOP(面向切面编程)和IOC(控制反转).本篇文章主要讲我对IOC的理解. IOC:即In ...
- assert后面如果是假则程序崩溃
assert后面如果是假,则程序崩溃.
- 00-翻译IdentityServer4的目的
强迫自己阅读英文文档 加深IdentityServer4的概念认识
- 学习react系列(八)—— mixins迁移
先来介绍一下mixins(混入) 先来看一段代码: const mixin = function(obj, mixins) { const newObj = obj; newObj.prototype ...
- 【MySQL】通过Binary Log简单实现数据回滚(一)
一.前言 对,没错,我又水了好一阵子,深刻反思寄几.前段时间,工作项目上出于对excel等批量操作可能出现误操作的问题,要求提供一个能够根据操作批次进行数据回滚的能力.在开发的过程中接触到了MySQL ...
- JavaScript数据结构与算法(七) 双向链表的实现
TypeScript方式实现源码 // 双向链表和普通链表的区别在于, 在链表中, // 一个节点只有链向下一个节点的链接,而在双向链表中,链接是双向的:一个链向下一个元素, // 另一个链向前一个元 ...
- java中lamda表达式的应用
lamda表达式主要是为了解决匿名内部类的繁琐过程 范例:简单的lamda表达式 此处使用匿名内部类 package com.java.demo; interface IMessage{ public ...