转 Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置。
1、softmax-loss
softmax-loss层和softmax层计算大致是相同的。softmax是一个分类器,计算的是类别的概率(Likelihood),是Logistic Regression 的一种推广。Logistic Regression 只能用于二分类,而softmax可以用于多分类。
softmax与softmax-loss的区别:
softmax计算公式:
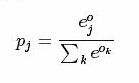
而softmax-loss计算公式:
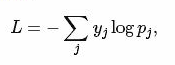
关于两者的区别更加具体的介绍,可参考:softmax vs. softmax-loss
用户可能最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax层,而不一定要进行softmax-Loss 操作;或者是用户有通过其他什么方式已经得到了某种概率似然值,然后要做最大似然估计,此时则只需要后面的 softmax-Loss 而不需要前面的 Softmax 操作。因此提供两个不同的 Layer 结构比只提供一个合在一起的 Softmax-Loss Layer 要灵活许多。
不管是softmax layer还是softmax-loss layer,都是没有参数的,只是层类型不同而也
softmax-loss layer:输出loss值

layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
softmax layer: 输出似然值
layers {
bottom: "cls3_fc"
top: "prob"
name: "prob"
type: “Softmax"
}
2、Inner Product
全连接层,把输入当作成一个向量,输出也是一个简单向量(把输入数据blobs的width和height全变为1)。
输入: n*c0*h*w
输出: n*c1*1*1
全连接层实际上也是一种卷积层,只是它的卷积核大小和原数据大小一致。因此它的参数基本和卷积层的参数一样。
层类型:InnerProduct
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
必须设置的参数:
num_output: 过滤器(filfter)的个数
其它参数:
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
3、accuracy
输出分类(预测)精确度,只有test阶段才有,因此需要加入include参数。
层类型:Accuracy
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
4、reshape
在不改变数据的情况下,改变输入的维度。
层类型:Reshape
先来看例子
layer {
name: "reshape"
type: "Reshape"
bottom: "input"
top: "output"
reshape_param {
shape {
dim: 0 # copy the dimension from below
dim: 2
dim: 3
dim: -1 # infer it from the other dimensions
}
}
}
有一个可选的参数组shape, 用于指定blob数据的各维的值(blob是一个四维的数据:n*c*w*h)。
dim:0 表示维度不变,即输入和输出是相同的维度。
dim:2 或 dim:3 将原来的维度变成2或3
dim:-1 表示由系统自动计算维度。数据的总量不变,系统会根据blob数据的其它三维来自动计算当前维的维度值 。
假设原数据为:64*3*28*28, 表示64张3通道的28*28的彩色图片
经过reshape变换:
reshape_param {
shape {
dim: 0
dim: 0
dim: 14
dim: -1
}
}
输出数据为:64*3*14*56
5、Dropout
Dropout是一个防止过拟合的trick。可以随机让网络某些隐含层节点的权重不工作。
先看例子:
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7-conv"
top: "fc7-conv"
dropout_param {
dropout_ratio: 0.5
}
}
只需要设置一个dropout_ratio就可以了。
还有其它更多的层,但用的地方不多,就不一一介绍了。
随着深度学习的深入,各种各样的新模型会不断的出现,因此对应的各种新类型的层也在不断的出现。这些新出现的层,我们只有在等caffe更新到新版本后,再去慢慢地摸索了。
转 Caffe学习系列(5):其它常用层及参数的更多相关文章
- Caffe学习系列(2):数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件 ...
- 转 Caffe学习系列(2):数据层及参数
http://www.cnblogs.com/denny402/p/5070928.html 要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 转 Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
随机推荐
- JSP错误页面的处理和exception对象
exception对象可以使用的主要方法如下所示. l getMessage():该方法返回错误信息. l printStackTrace():该方法以标准错误的形式输出一 ...
- 【转】DELL R710服务器可以安装的VMWare ESX Server 4.1 全套下载带注册码
随着R710的停产,R720随之面世,但DELL R720服务器只支持vmware esxi5.0以上,DELL客户经理给了一套系统安装后序列号无法解决,还是用4.1好了,却又发现怎么都无法安装.按网 ...
- The mkdir Command
The mkdir command is is used to create new directories. A directory, referred to as a folder in some ...
- sizeof和strlen的使用
sizeof和strlen的使用 1. sizeof 其值在编译时就计算好了,所以不能用来返回动态分配的内存空姐的大小. 当参数为下面内容是,所表达的含义: 数组——编译时分配的数组空间大小: 指针— ...
- python之作业--------购物车优化
Read Me:继上次简单购物车的实现,有再一次的升级优化了下,现实现以下几个功能: 1.有客户操作和商家操作,实现,客户可以买东西,当金额不足提醒,最后按q退出,打印购物车列表 2.商家可以添加操作 ...
- zookeeper 实现分布式锁
主要是依赖临时节点的特性.数据存储到内存中效率高:例如有web1 web2 两台应用服务器 db1 db2两台db服务器 db互为主备,web1 web2 分别去修改db1 .有限db2库里张三的年 ...
- spring之集合注入
list: <bean id="userAction" class="com.xx.action.UserAction"> <property ...
- 安装Mercurial进行版本管理
mercurial是又一个去中心化的版本管理软件,类似git 先介绍如何安装mercurial yum -y install mercurial mercurial需要一个用户名来记录commit动作 ...
- windows免费?linux免费?赶紧过来看吧
1.今天分享大家一个免费申请linux的网站,可以用来做学习使用! 1.链接地址:https://linuxzoo.net 一次性邮箱:https://temp-mail.org 打开网址申请一个 ...
- ASM字节码框架学习之动态代理
ASM字节码操纵框架,可以直接以二进制的形式来来修改已经存在的类或者创建新的类.ASM封装了操作字节码的大部分细节,并提供了非常方便的接口来对字节码进行操作.ASM框架是全功能的,使用ASM字节码框架 ...