MySQL复制入门
Ⅰ、复制类型
1.1 逻辑复制
- 记录每次逻辑操作
- 主从数据库可以不一致
1.2 物理逻辑复制
- 记录每次对于数据页的操作
- 主从数据物理严格一致
- 基于重做日志
说明:
如果一个块(页)修改了,就把这个修改发到远端
主从两端不仅仅是数据一致,而是物理上的一致,页都是一样的
1.3 复制选型与对比
简单的主从环境,两边同样的表,space_id不用一样,只要保证数据在逻辑内容上一致,物理上不用一样。也就是说,一张表的数据一致就行,不要求这些数据对应的表空间里面内容也一致
Oracle的优势
Oracle中commit时间是平均的,MySQL却不是
MySQL中事务越大commit越慢,binlog是事务执行完commit之后才写,从而产生延时的问题,Oracle中是物理逻辑复制,块的变化实时同步到从上
MySQL的优势
做大数据,把MySQL里面的数据变化传到数据仓库平台,MySQL做起来就很方便,Oralce做起来麻烦,物理日志要去解析是解析不出来行的变化的,但是有ogg工具可以同步到hive,不过偏商业
Ⅱ、典型关系型数据库复制对比
| - | MySQL | Oracle Data Gurad | SQL Server Mirroring |
|---|---|---|---|
| 类型 | 逻辑复制 | 物理逻辑复制 | 物理逻辑复制 |
| 优点 | 灵活 | 复制速度快 | 复制速度快 |
| 缺点 | 配置不当易出错 | 要求物理数据严格一致 | 要求物理数据严格一致 |
问:MySQL的innodb也有redo,那为什么不支持redo级别的复制呢?
答:因为MySQL有很多种引擎,需要有一个统一的复制层,而不是在引擎层做复制,所以在server层实现复制,每个引擎做一个复制就做不到一致性了
一般业务架构,一主两从足够,金融行业可能会做一主四从
Ⅲ、复制搭建
小常识
MySQL的事务一次commit分成三个阶段
第一阶段的prepare和第三阶段的commit都在innodb层
第二阶段的write binlog在server层
三个步骤都是group commit的,所以性能不会差
3.1 基本原理
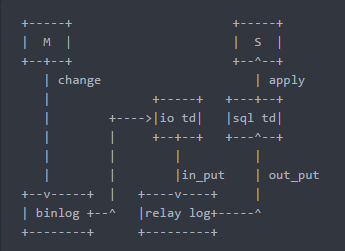
当commit写到二进制文件之后,如果搭建了复制,就会有一个dump thread将binlog传送到远程服务器
远端服务器上有一个IO thread来接收这些event放到relay log中,还有一个SQL thread来回放relay log中的event
5.6版本开始,可以多个线程并行回放,所以速度相对来说可能快一些
tips:
①关于binlog,详见binlog——逻辑复制的基础
②master发送给slave的是什么东西?具体怎么发送的? 答:以event为最小单位发送,千万不要说sql语句或者记录
③关于relay log
- Relay_Log_File和Relay_Log_Pos是中继日志(relay log)信息
- 由于IO线程拉取数据的速度快于SQL线程回放数据的速度,所以relay log可在两者之间起到一个缓冲的作用
- relay log的格式和binlog的格式是一样的,但是两者的内容是不一样的(不是和binlog一一对应的)
- relay log在SQL线程回放完成后就会被删除(默认),而 binlog 不会(由expire_logs_days控制)
- relay log 可以通过设置 relay_log_purge=0,使得relay Log不被删除(MHA中不希望被purge),需要通过外部的脚本进行删除
3.2 动手搭一个
炒鸡简单,虽然没mongodb简单,但比oracle简单太多了(redis的cluster比mongodb都简单),搞起来!!!
| 步骤 | 操作 |
|---|---|
| step1 | 主机备份数据 |
| step2 | 从机恢复数据 |
| step3 | 主机授权一个复制用户权限 |
| step4 | 从机change master to(filename,pos) |
- pos之前是导过来的数据,pos之后通过binlog同步,这是一个最终一致性的模型,master不断将binlog发到slave
- binlog的恢复是手工的,MySQL的复制是准实时的
实操
本人是穷人,这里用单机多实例模拟:
主用3306端口 server-id:3306
从用3307端口 server-id:3307
重点:
主从之间的server-id千万不能一样,否则可能导致宕机
说明:我这里3306跑的是mysql5.5,3307跑的mysql5.6,所以bashrc和my.cnf中配置的东西55就是3306,56就是3307的意思
step1:
主上做备份
[root@VM_0_5_centos ~]# mysqldump --single-transaction --master-data=1 -A -S /tmp/mysql.sock55 > /tmp/fullbackup.sql
step2:
从上导入备份
[root@VM_0_5_centos ~]# mysql56 < /tmp/fullbackup.sql
step3:
主上授权复制用户权限
(root@172.16.0.10) [test]> create user 'rpl'@'%' identified by '123';
Query OK, 0 rows affected (0.01 sec)
(root@172.16.0.10) [test]> grant replication slave on *.* to 'rpl'@'%'; --需要replication和slave的权限,线上建议 限制成内网的网段
Query OK, 0 rows affected (0.01 sec)
打开备份文件,找到二进制文件位置点
[root@VM_0_5_centos ~]# head -n 30 /tmp/fullbackup.sql
CHANGE MASTER TO MASTER_LOG_FILE='bin.000004', MASTER_LOG_POS=107;
找到上面这句
step4:
登陆到从实例执行如下语句:
(root@172.16.0.10) [test]> CHANGE MASTER TO MASTER_LOG_FILE='bin.000004', MASTER_LOG_POS=107, MASTER_HOST='127.0.0.1' ,MASTER_PORT=3306 ,MASTER_USER='rpl' ,MASTER_PASSWORD='123';
Query OK, 0 rows affected, 2 warnings (0.12 sec) -- 有warning是因为密码写在了里面
检查:
从上执行show slave status\G --此处只贴部分关键内容
(root@172.16.0.10) [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 127.0.0.1
Master_User: rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: bin.000004 -- change master中的filename
Read_Master_Log_Pos: 107 -- change master中的pos
Relay_Log_File: relay.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: bin.000004
Slave_IO_Running: No
Slave_SQL_Running: No
到这一步,我们的主从复制就搭建好了!但是我们看到io线程和sql线程都是no,我们需要在从机上启动复制
(root@172.16.0.10) [test]>start slave;
Query OK, 0 rows affected (0.00 se
再看两个线程就都是Yes了
Slave_IO_Running和Slave_SQL_Running这两个指标都为YES,表示目前的复制的状态是正常的
3.3 细说show slave status\G
(root@172.16.0.10) [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event IO线程状态
Master_Host: 127.0.0.1 主机IP
Master_User: rpl 复制用户名
Master_Port: 3306 主机端口号
Connect_Retry: 60 连不上,重连次数,默认60次
Master_Log_File: bin.000004 当前同步到主机的logfile
Read_Master_Log_Pos: 15451622 当前同步到的位置点
Relay_Log_File: cloud-relay-bin.000002 slave上的中继日志
Relay_Log_Pos: 15451775 中继日志的位置点
Relay_Master_Log_File: bin.000004 当前Relay文件对应的Master文件
Slave_IO_Running: Yes IO线程状态
Slave_SQL_Running: Yes SQL线程状态
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0 最近一次的错误号
Last_Error: 最近一次错误信息
Skip_Counter: 0 跳过错误次数
Exec_Master_Log_Pos: 15451622 现在回放到的位置
Relay_Log_Space: 15451944 当前中继日志的大小
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0 sql线程落后io线程的时间
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3306
Master_UUID:
Master_Info_File: /data/mysql_test_data56/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
最终来看,io线程和sql线程执行的位置应该一样,但是通常sql线程会比io线程慢一点
tips:
①Seconds_Behind_Master: The number of seconds that the slave SQL thread is behind processing the master binary log
relay log中event记录的时间戳是主库上的时间戳,而SQL thread的时间戳是从库上的,只有主从时间完全一致,该指标才有意义
②重连机制
slave-net-timeout 从获取不到数据后等待时间
master-connect-retry 重连等待时间
master-retry-count 重连次数
当从库发现从主库上无法获得更多的数据了,就会等待slave-net-timeout时间,然后将IO thread置为no状态,接着开始尝试重建建立连接,每次建立失败之后等待master-connect-retry时间,一直重试master-retry-count次
Ⅳ、主从架构中常用的操作
4.1 主
查看从服务器列表
(root@172.16.0.10) [test]> show slave hosts;
+-----------+------+-------+-----------+
| Server_id | Host | Port | Master_id |
+-----------+------+-------+-----------+
| 3307 | | 3307 | 3306 |
+-----------+------+-------+-----------+
1 row in set (0.00 sec)
看binlog到了什么位置
(root@172.16.0.10) [test]> show master status;
+----------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+----------------+----------+--------------+------------------+
| mysql-bin.003 | 73 | | |
+-------------------------------------------------------------+
1 row in set (0.00 sec)
4.2 从
show slave status;
change master to
start/stop slave
4.3 报错处理
模拟报错:
从:
(root@172.16.0.10) [test]> create database sb;
Query OK, 1 row affected (0.00 sec)
主:
(root@172.16.0.10) [test]> create database sb;
Query OK, 1 row affected (0.00 sec)
从:
(root@172.16.0.10) [test]> show slave status\G
Last_SQL_Errno: 1007
Last_SQL_Error: Error 'Can't create database 'sb'; database exists' on query. Default database: 'sb'. Query: 'create database sb'
报错冲突了!
怎么办?
从:
执行如下sql,跳过当前报错,不执行这个event
(root@172.16.0.10) [test]> set global sql_slave_skip_counter=1;
Query OK, 0 row affected (0.00 sec)
重新把主从复制拉起来
start slave;
Query OK, 0 row affected (0.00 sec)
关于这个跳过当前报错后面会专门具体展开分析,暂时了解这么多即可
Ⅴ、read_only与super_read_only
如果在slave机器上对数据库进行修改或者删除,会导致主从的不一致,需要对Slave机器设置为read_only = 1,让slave提供只读操作。
tips:
read_only仅仅对没有SUPER权限的用户有效(即 mysql.user表的Super_priv字段为Y),一般给APP的权限是不需要SUPER权限的
MySQL 5.7中参数super_read_only可以将有SUPER权限的用户也设置为只读,且该参数设置为ON后,read_only也跟着自动设置为ON
当前MySQL中,在/etc/my.cnf中将super_read_only=1配置好后重启,还是可以插入或修改数据。需要在命令行中执行set global super_read_only=1; 才能真正修改为只读,具体何时修复还没注意
MySQL复制入门的更多相关文章
- [转]MySQL主从复制入门
1.MySQL主从复制入门 首先,我们看一个图: 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的33 ...
- MySQL 菜鸟入门“秘籍”
一.MySQL简介 1.什么是数据库 ? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不 ...
- MySQL主从复制入门
1.MySQL主从复制入门 首先,我们看一个图: MySQL 主从复制与读写分离概念及架构分析 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志 ...
- MySQL菜鸟入门“秘籍”
一.MySQL简介 1.什么是数据库 ? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不 ...
- MySQL基础入门(1)
MySQL基础入门(1) 为什么学习MySQL 关系数据库管理系统(Relational Database Management System, RDBMS)是一种极为重要的工具,其应用十分广泛,从商 ...
- 浅析MySQL复制
MySQL的复制是基于binlog来实现的. 流程如下 涉及到三个线程,主库的DUMP线程,从库的IO线程和SQL线程. 1. 主库将所有操作都记录到binlog中.当复制开启时,主库的DUMP线程根 ...
- MySQL复制环境(主从/主主)部署总结性梳理
Mysql复制概念说明Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves) ...
- MYSQL复制
今天我们聊聊复制,复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现.下文主要从4个方面展开,mysql的异步复制,半同步复制和并行复制,最后会简单聊下第三 ...
- mysql复制一列到另一列
mysql复制一列到另一列 UPDATE 表名 SET B列名=A列名 需求:把一个表某个字段内容复制到另一张表的某个字段. 实现sql语句1: 复制代码代码如下: UPDATE file_man ...
随机推荐
- 让App中加入LruCache缓存,轻松解决图片过多造成的OOM
上次有过电话面试中问到Android中的缓存策略,当时模糊不清的回答,现在好好理一下吧. Android中一般情况下采取的缓存策略是使用二级缓存,即内存缓存+硬盘缓存->LruCache+Dis ...
- Struts2技术内幕 读书笔记三 表示层的困惑
表示层能有什么疑惑?很简单,我们暂时忘记所有的框架,就写一个注册的servlet来看看. index.jsp <form id="form1" name="form ...
- kettle控件 add a checksum
This step calculates checksums for one or more fields in the input stream and adds this to the outpu ...
- android studio比较长用的几款插件
不懂安装studio插件,看参考博文:android stuido插件安装:http://blog.csdn.net/liang5630/article/details/46372447 1.Butt ...
- iOS 即时视频和聊天(基于环信)
先上效果图: 屏幕快照 2015-07-30 下午5.19.46.png 说说需求:开发一个可以进行即时视频聊天软件. 最近比较忙,考完试回到公司就要做这个即时通信demo.本来是打算用xmpp协议来 ...
- 和菜鸟一起学产品之用户体验设计UED
ps:参考产品经理深入浅出ppt
- python 网络框架twisted基础学习及详细讲解
twisted网络框架的三个基础模块:Protocol, ProtocolFactory, Transport.这三个模块是构成twisted服务器端与客户端程序的基本.Protocol:Protoc ...
- AOP的相关概念
- JQuery(二)---- JQ的事件与动画详解
JQuery的事件 /** * 1.事件绑定的快捷方式: */ $("button:eq(0)").dblclick(function(){ alert("hahaah& ...
- dom4j 解析 xml标签属性
重写onEnd()和onStart()方法 public class XmlElementHandler implements ElementHandler { @Override public vo ...